AI 코딩, 복잡한 코드베이스에서도 작동하게 만들기
게시일: 2026년 1월 28일 | 원문 작성일: 2025년 8월 30일 | 저자: Dex Horthy | 원문 보기

핵심 요약
AI 코딩 도구가 대규모 프로덕션 코드베이스에서 작동하지 않는다는 건 이제 널리 알려진 사실이에요. 하지만 컨텍스트 엔지니어링(context engineering) 원칙을 적용하면 오늘날의 모델로도 충분히 좋은 결과를 낼 수 있어요.
- 빈번한 의도적 압축(Frequent Intentional Compaction) — 전체 개발 워크플로우를 컨텍스트 관리 중심으로 설계하고, 컨텍스트 사용률을 40-60%로 유지하는 기법
- 리서치(Research) → 플랜(Plan) → 구현(Implement) 워크플로우 — 단계별로 압축된 산출물을 만들어 다음 단계에 활용
- 사람의 고레버리지(high-leverage) 리뷰 — 코드가 아닌 리서치와 플랜을 리뷰해서 더 큰 영향력을 발휘
영상 버전: 영상을 선호한다면, 이 글은 8월 20일 Y Combinator3에서 한 발표를 기반으로 했어요.
• • •
AI 코딩 도구가 실제 프로덕션 코드베이스에서는 잘 안 된다는 건 이제 꽤 널리 받아들여지는 사실이에요. 스탠퍼드의 개발자 생산성 연구에 따르면:
- AI 도구가 만들어낸 “추가 코드” 상당 부분이 결국 지난주에 찍어낸 슬롭(slop)을 수습하는 데 쓰여요
- 코딩 에이전트는 새 프로젝트나 작은 변경에는 훌륭하지만, 크고 오래된 코드베이스에서는 개발자를 덜 생산적으로 만들 수 있어요
흔히 나오는 반응은 비관론자의 “이건 절대 안 될 거야”부터 좀 더 신중한 “언젠가 더 똑똑한 모델이 나오면…”까지 다양해요.
몇 달 동안 이것저것 만지작거려본 결과, 핵심적인 컨텍스트 엔지니어링 원칙을 받아들이면 오늘날의 모델로도 정말 멀리 갈 수 있다는 걸 알게 됐어요.
이건 또 다른 “생산성 10배” 이야기가 아니에요. 저는 AI 과대광고에는 꽤 냉정한 편이거든요. 하지만 우연히 발견한 워크플로우들이 가능성에 대해 상당히 낙관적이게 만들어줬어요. Claude Code로 30만 줄 규모의 Rust 코드베이스를 다루고, 일주일치 작업을 하루 만에 끝내고, 전문가 리뷰를 통과하는 코드 품질을 유지할 수 있었거든요. 저는 “빈번한 의도적 압축(frequent intentional compaction)“이라고 부르는 기법군을 사용해요 - 개발 과정 전체에 걸쳐 AI에게 컨텍스트를 어떻게 제공할지 의도적으로 구조화하는 거예요.
저는 이제 AI 코딩이 장난감이나 프로토타입용만이 아니라, 진정한 의미의 전문 엔지니어링 기술이라고 완전히 확신하게 됐어요.
AI Engineer 컨퍼런스에서 얻은 영감
AI Engineer 2025의 두 발표가 이 문제에 대한 제 생각을 근본적으로 바꿔놨어요.
첫 번째는 Sean Grove의 “스펙이 새로운 코드다” 발표이고, 두 번째는 스탠퍼드의 AI 개발자 생산성 연구예요.
Sean의 주장은 우리 모두 바이브 코딩(vibe coding)을 잘못하고 있다는 거예요. AI 에이전트와 두 시간 동안 대화하면서 원하는 걸 설명하고, 프롬프트는 죄다 버리고 최종 코드만 커밋하는 건… Java 개발자가 JAR 컴파일해서 바이너리만 체크인하고 소스는 버리는 꼴이라는 거예요.
Sean의 제안은 AI 시대에는 스펙이 진짜 코드가 될 것이라는 거예요. 2년 후에는 IDE에서 Python 파일을 여는 빈도가, 오늘날 헥스 에디터로 어셈블리를 읽는 빈도와 비슷해질 거라고요. 대부분의 개발자에게 그건 “평생에 한 번도 없음”이거든요.
Yegor의 개발자 생산성 발표는 다른 각도에서 문제를 다뤘어요. 10만 명 개발자의 커밋을 분석한 결과:
- AI 도구가 재작업을 많이 만들어서, 실제로 느끼는 생산성 향상이 줄어듦
- AI 도구가 그린필드(greenfield, 새로 시작하는 프로젝트)에는 잘 작동하지만, 브라운필드(brownfield, 이미 복잡하게 얽힌 기존 코드베이스)와 복잡한 작업에는 오히려 역효과
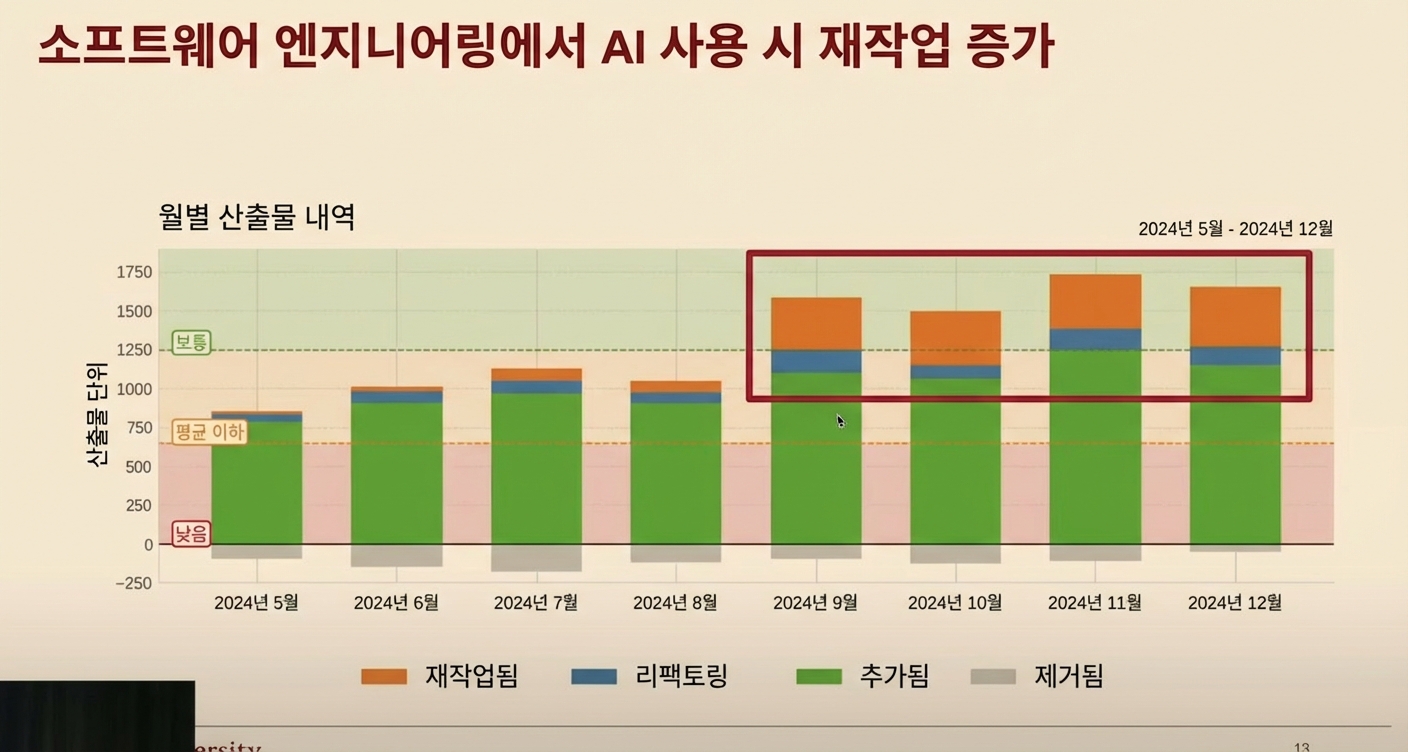

이건 제가 창업자들한테 들은 것과 딱 맞았어요:
- “슬롭(slop, AI가 만든 저품질 코드)이 너무 많아요."
- "기술 부채 공장이에요."
- "큰 저장소에서는 안 돼요."
- "복잡한 시스템에서는 안 돼요.”
어려운 문제에 AI 코딩을 쓰는 것에 대한 일반적인 분위기는 이래요:
“언젠가, 모델이 더 똑똑해지면…”
아니, 심지어 Amjad(Replit 창업자)조차도 9개월 전 Lenny’s Podcast4에서 PM(Product Manager)들이 Replit 에이전트로 새 기능 프로토타입을 만들고 프로덕션 구현은 엔지니어에게 넘긴다고 말했었거든요. (참고로 저는 최근에 그와 이야기해본 적 없어요. 사실 한 번도요. 입장이 바뀌었을 수도 있고요)
“언젠가 모델이 똑똑해지면”이라는 말을 들으면 저는 바로 이렇게 외치게 돼요 - 그게 바로 컨텍스트 엔지니어링이 하는 일이에요: 오늘날의 모델에서 최대한을 뽑아내는 것.
오늘날 실제로 가능한 것
이론만이 아니라는 걸 증명하기 위해 구체적인 예시를 들어볼게요. 몇 주 전, 저는 BAML에서 우리 기법들을 테스트하기로 했어요. BAML은 LLM과 함께 작동하는 프로그래밍 언어를 위한 30만 줄 규모의 Rust 코드베이스예요. 저는 기껏해야 아마추어 Rust 개발자이고, BAML 코드베이스를 한 번도 본 적이 없었어요.
한 시간 정도 만에 버그를 수정하는 PR(Pull Request)5을 만들었고, 다음 날 아침 메인테이너의 승인을 받았어요. 몇 주 후에는 @hellovai와 함께 BAML에 3만 5천 줄을 배포해서 취소 지원과 WASM 컴파일6을 추가했어요 - 팀에서 시니어 엔지니어가 각각 3-5일 걸릴 것으로 예상한 기능들이에요. 우리는 약 7시간 만에 두 드래프트 PR을 준비했어요.
이 모든 게 빈번한 의도적 압축이라는 워크플로우를 기반으로 해요 - 본질적으로 전체 개발 프로세스를 컨텍스트 관리 중심으로 설계하고, 사용률을 40-60% 범위로 유지하며, 정확히 맞는 지점에 고레버리지 휴먼 리뷰를 넣는 거예요. “리서치, 플랜, 구현” 워크플로우를 사용하지만, 핵심 역량과 배움은 특정 워크플로우나 프롬프트 세트보다 훨씬 일반적이에요.
여기까지 오게 된 이상한 여정
저는 제가 만나본 가장 생산적인 AI 코더 중 한 명과 일하고 있었어요. 며칠마다 2000줄짜리 Go PR을 던지더라고요. 이건 Next.js 앱이나 CRUD API가 아니었어요. Unix 소켓으로 JSON RPC를 하고 포크된 Unix 프로세스의 스트리밍 stdio를 관리하는 복잡한, 레이스 컨디션(race condition)이 발생하기 쉬운 시스템 코드였어요.
며칠마다 2000줄의 복잡한 Go 코드를 꼼꼼히 읽는다는 건 그냥 지속 가능하지 않았어요. Mitchell Hashimoto7가 Ghostty에 “AI 기여는 밝혀야 함” 규칙을 추가할 때 기분이 어땠을지 슬슬 알 것 같았어요.
우리가 선택한 건 Sean의 스펙 주도 개발(spec-driven development)과 비슷한 방식이었어요.
처음에는 불편했어요. PR의 모든 코드를 한 줄씩 읽는 습관을 내려놓아야 했거든요. 테스트는 여전히 꼼꼼히 읽지만, “뭘 왜 만드는지”는 이제 스펙만 보면 알 수 있게 됐어요.
변화하는 데 8주 정도 걸렸어요. 모두에게 엄청 불편했고, 특히 저한테요. 근데 지금은 완전 날아다녀요. 몇 주 전에는 하루에 6개 PR을 배포했어요. 지난 3개월 동안 마크다운 아닌 파일을 직접 건드린 건 손에 꼽을 정도예요.
코딩 에이전트를 위한 고급 컨텍스트 엔지니어링(Advanced Context Engineering)
우리에게 필요한 건 이거였어요:
- 브라운필드 코드베이스에서 잘 작동하는 AI
- 복잡한 문제를 해결하는 AI
- 슬롭 없음
- 팀 전체의 멘탈 얼라인먼트(mental alignment) 유지 — 팀원들이 코드가 어떻게 작동하는지 함께 이해하고 있는 상태
(물론 토큰이야 최대한 많이 쓰면 좋고요. 😉)
다룰 내용은:
- 코딩 에이전트에 컨텍스트 엔지니어링을 적용하며 배운 것
- 이 에이전트들을 사용하는 것 자체가 하나의 전문 기술인 이유
- 왜 이 접근법들이 일반화 가능하지 않다고 생각하는지
- (3)에 대해 반복적으로 틀렸다는 게 증명된 횟수
먼저: 에이전트 컨텍스트를 관리하는 순진한 방법
대부분은 코딩 에이전트를 챗봇처럼 사용하는 것부터 시작해요. 에이전트랑 대화하거나 (술김에 고래고래 소리지르거나) 하면서 감으로 문제를 풀어가다가 컨텍스트가 바닥나거나, 포기하거나, 에이전트가 사과하기 시작하죠.
약간 더 똑똑한 방법은 잘못됐을 때 그냥 다시 시작하는 거예요. 세션을 버리고 새로 시작하면서 프롬프트에 조금 더 방향을 잡아주는 거죠.
“[원래 프롬프트], 하지만 XYZ 접근법을 사용해. ABC 접근법은 안 되니까”
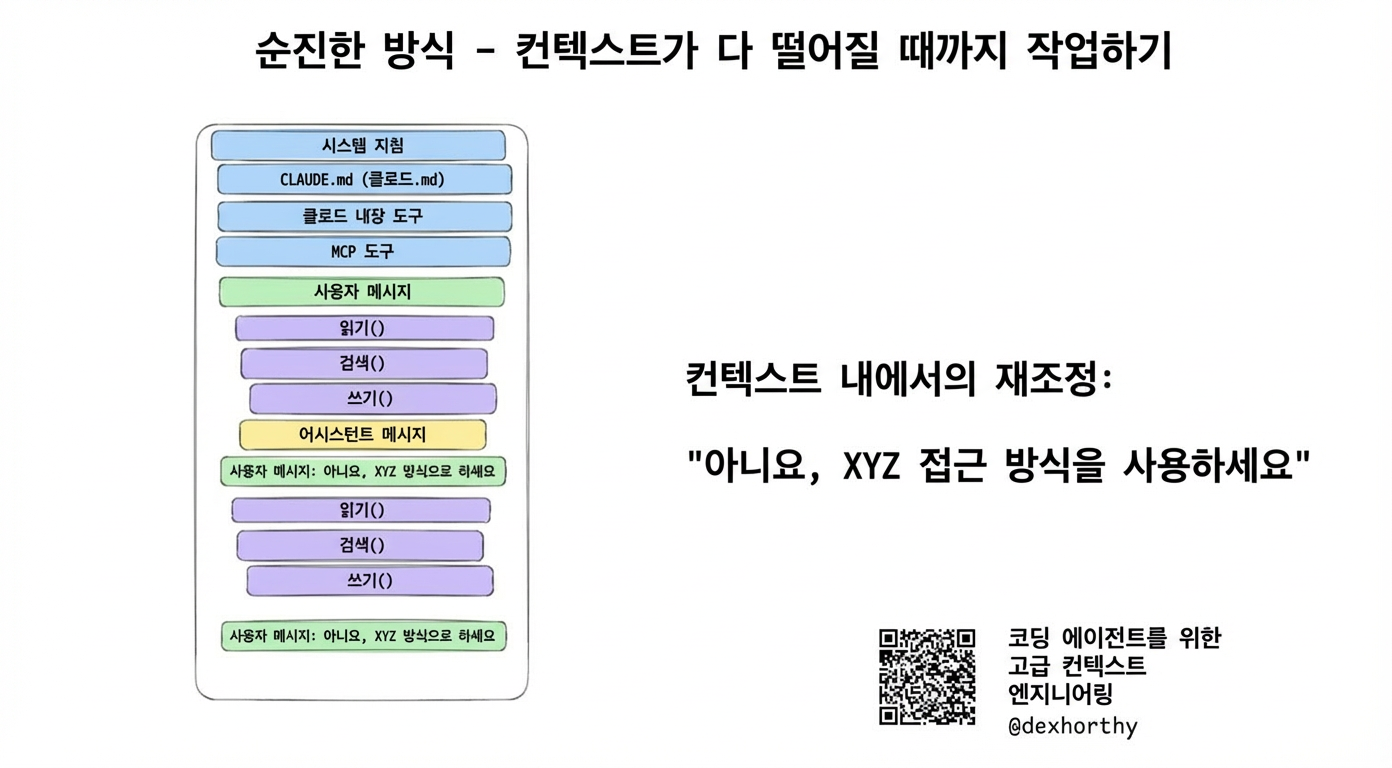
조금 더 똑똑하게: 의도적 압축
아마 제가 “의도적 압축(intentional compaction)“이라고 부르는 걸 해본 적 있을 거예요. 제대로 진행되고 있든 아니든, 컨텍스트가 차오르기 시작하면 작업을 멈추고 새 컨텍스트 창으로 다시 시작하고 싶을 거예요. 이렇게 하려면 이런 프롬프트를 쓸 수 있어요:
“지금까지 한 모든 걸 progress.md에 작성해. 최종 목표, 취하고 있는 접근법, 지금까지 완료한 단계들, 현재 작업 중인 실패 상황을 반드시 기록해”
커밋 메시지를 의도적 압축에 사용할 수도 있어요.
정확히 뭘 압축하는 건가요?
뭐가 컨텍스트를 잡아먹나요?
- 파일 검색
- 코드 흐름 이해
- 편집 적용
- 테스트/빌드 로그
- 도구에서 오는 거대한 JSON blob
이것들 모두 컨텍스트 창을 넘치게 할 수 있어요. 압축은 이 모든 걸 핵심만 뽑아서 구조화된 문서로 정리하는 거예요.
좋은 의도적 압축 출력에는 이런 게 포함될 수 있어요:
- 목표: [무엇을 달성하려고 하는지]
- 접근법: [취하고 있는 접근법]
- 완료한 단계: [지금까지 한 것]
- 관련 파일: [핵심 파일 목록과 역할]
- 현재 상태: [막힌 부분이나 다음 단계]
왜 컨텍스트에 집착하나요?
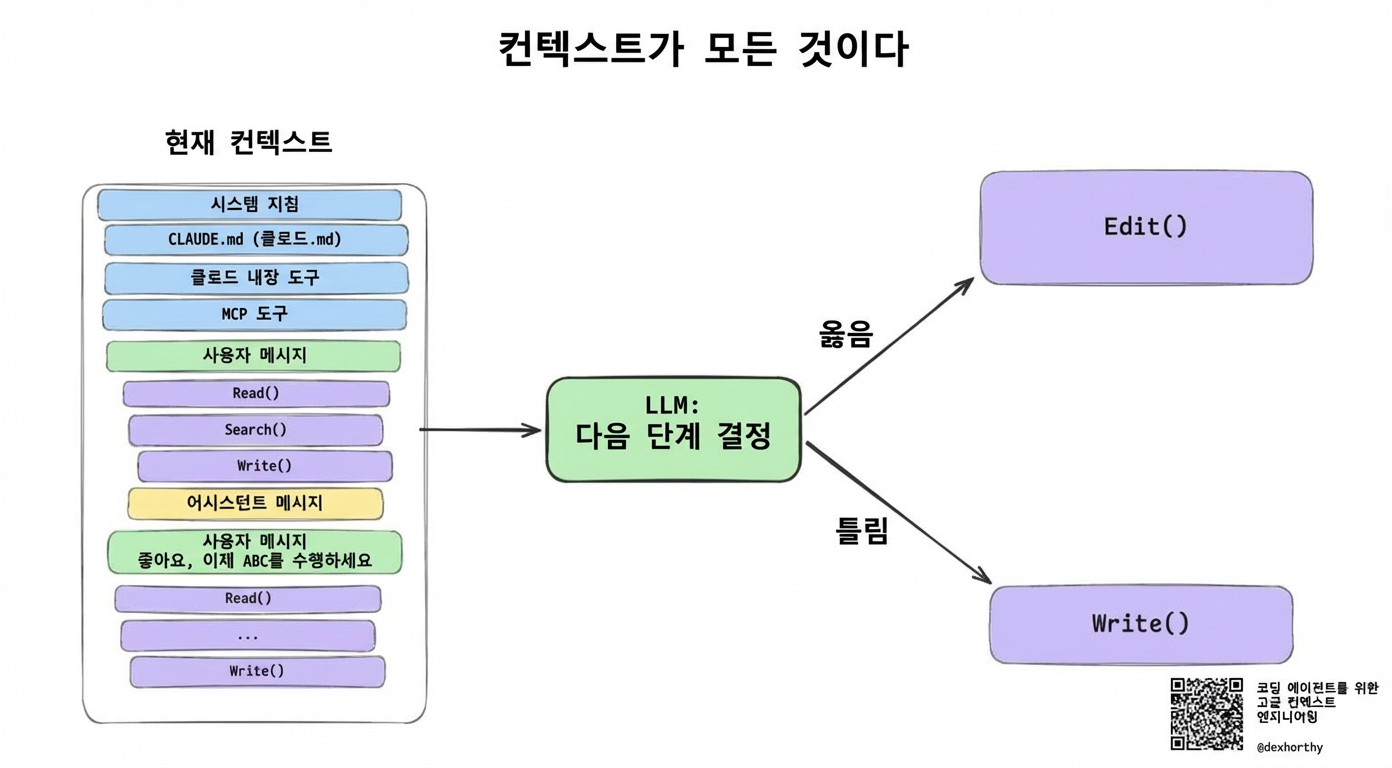
12-factor agents에서 깊이 다뤘듯이, LLM은 상태 없는 함수(stateless function)예요. 모델 자체를 학습/튜닝하지 않고 출력 품질에 영향을 미치는 유일한 것은 입력의 품질이에요.
이건 일반적인 에이전트 설계에서만큼이나 코딩 에이전트를 능숙하게 다루는 데도 마찬가지예요. 문제 공간이 더 작고, 에이전트를 만드는 게 아니라 사용하는 것에 대한 이야기일 뿐이에요.
어느 시점에서든, Claude Code 같은 에이전트의 턴은 상태 없는 함수 호출이에요. 컨텍스트 창이 들어가고, 다음 단계가 나와요.
즉, 컨텍스트 창의 내용이 출력 품질에 영향을 미치는 유일한 레버예요. 그래서 네, 집착할 가치가 있어요.
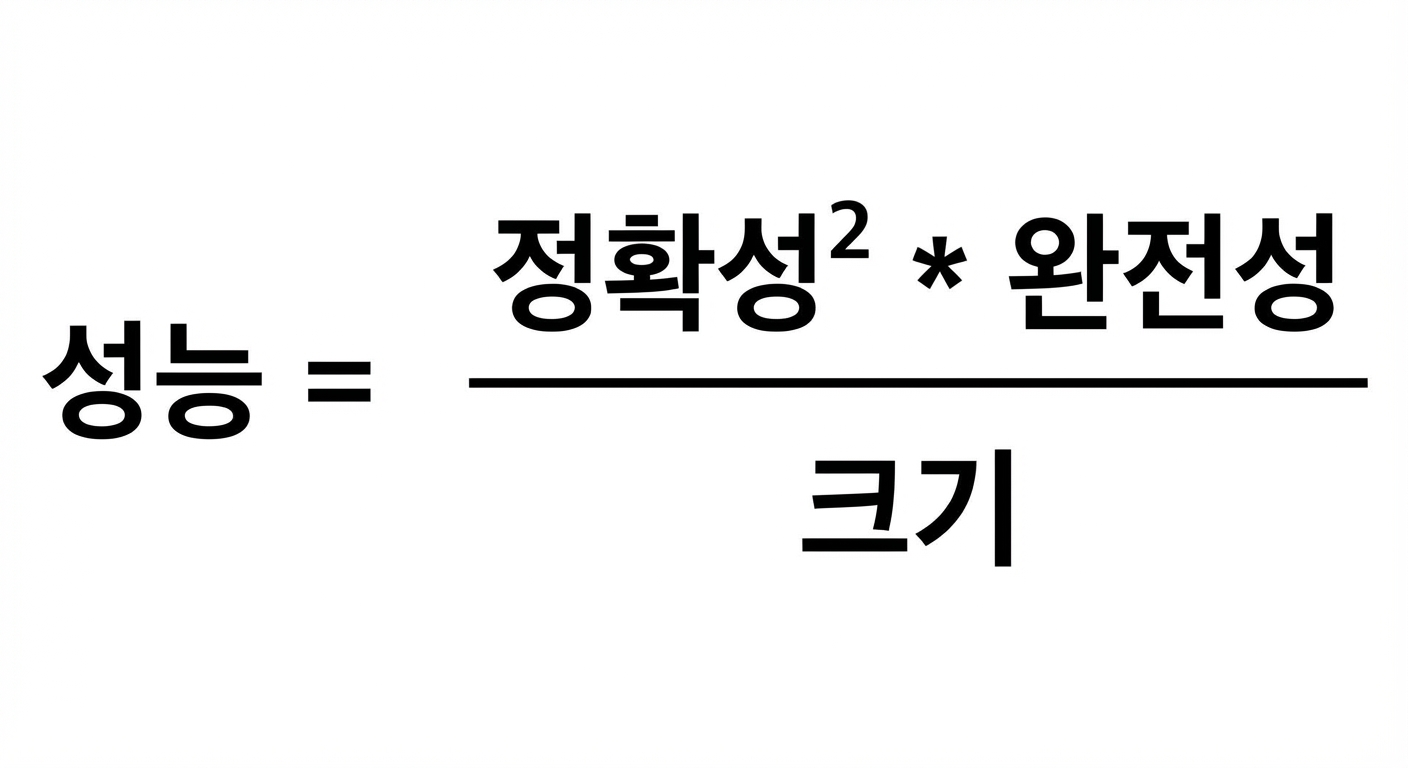
컨텍스트 창을 최적화해야 하는 항목:
- 정확성
- 완전성
- 크기
- 궤적
다르게 말하면, 컨텍스트 창에 일어날 수 있는 최악의 일들 순서대로:
- 잘못된 정보
- 누락된 정보
- 너무 많은 노이즈(noise)
Geoff Huntley의 말처럼:
“핵심은 우리가 쓸 수 있는 컨텍스트 창이 약 170K밖에 안 된다는 거예요. 그래서 가능한 한 아껴 쓰는 게 필수적이에요. 컨텍스트 창을 많이 쓸수록 결과는 나빠지거든요.”
Geoff가 이 엔지니어링 제약에 대한 해결책으로 제시하는 건 “소프트웨어 엔지니어로서의 랄프 위검(Ralph Wiggum)“1이라는 기법이에요. 기본적으로 간단한 프롬프트로 에이전트를 무한 루프에서 돌리는 거예요.
while :; do
cat PROMPT.md | npx --yes @sourcegraph/amp
doneRalph나 PROMPT.md에 대해 더 알고 싶다면 Geoff의 글을 확인하거나, 지난 주말 YC 에이전트 해커톤에서 @simonfarshid, @lantos1618, @AVGVSTVS96와 제가 만든 프로젝트를 살펴보세요. 하룻밤 만에 BrowserUse를 TypeScript로 포팅했거든요(대부분은요).
Geoff는 Ralph를 컨텍스트 창 문제에 대한 “웃기게 멍청한” 해결책이라고 설명해요. 저는 전혀 멍청하다고 생각 안 하는데요.
압축으로 돌아가서: 서브에이전트 사용하기
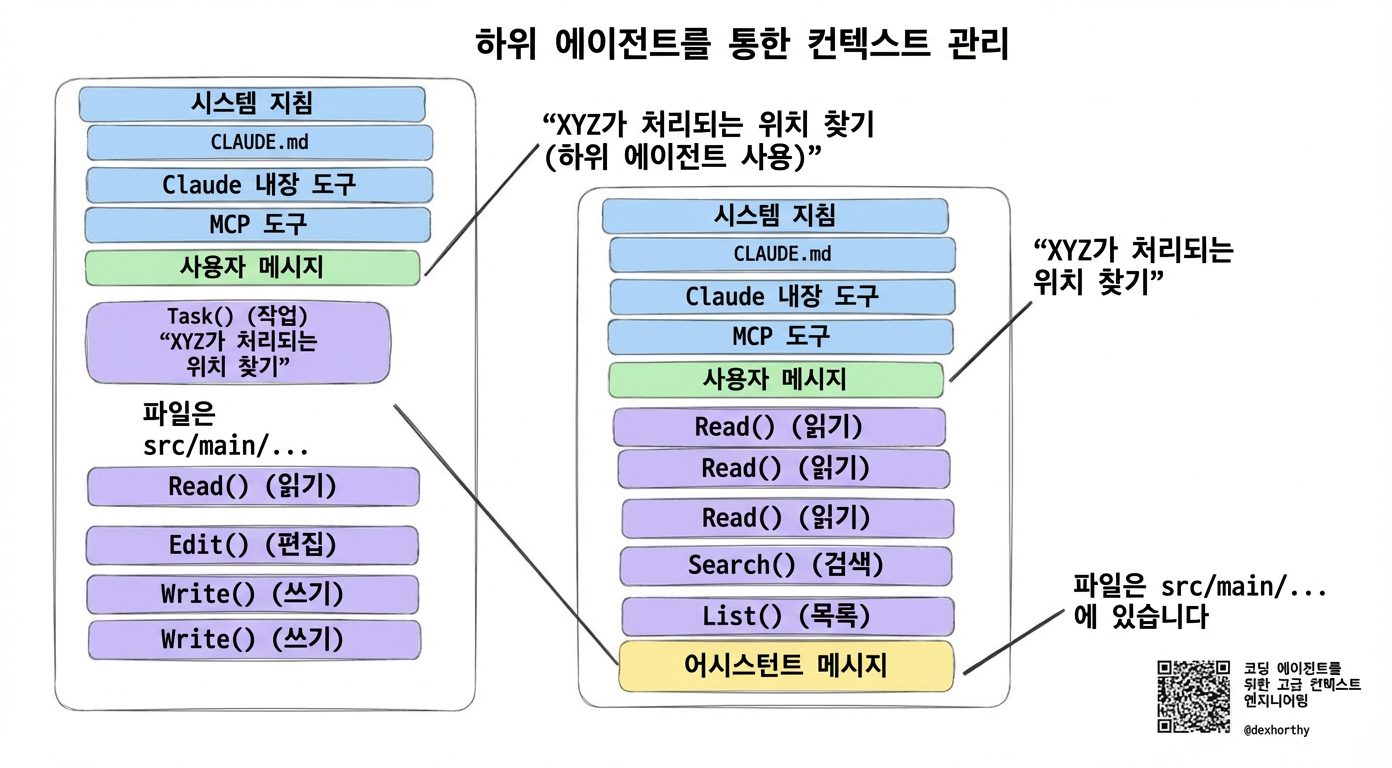
서브에이전트는 컨텍스트를 관리하는 또 다른 방법이고, 일반 서브에이전트(즉, 커스텀이 아닌)는 초기부터 Claude Code와 많은 코딩 CLI의 기능이었어요.
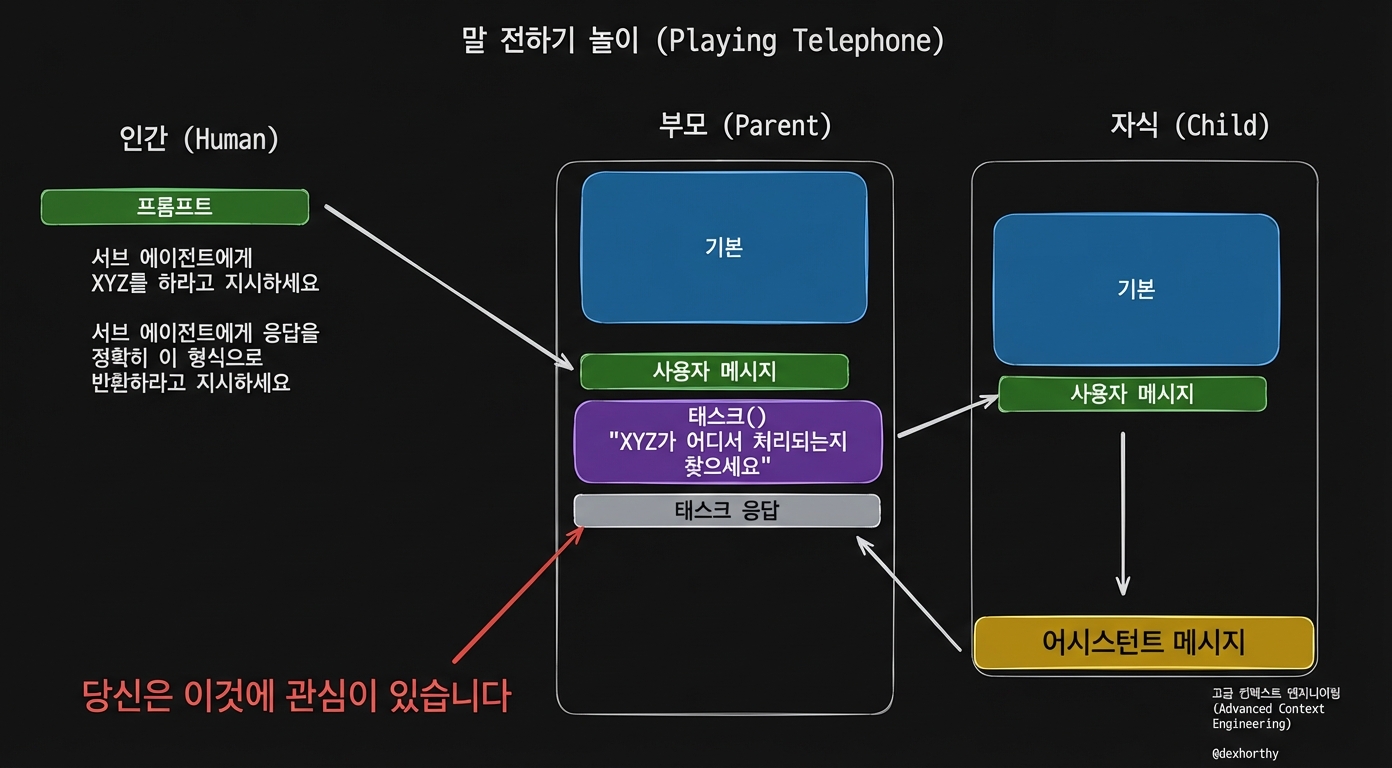
서브에이전트(subagent)는 역할극이나 의인화가 아니에요. 서브에이전트의 본질은 컨텍스트 제어(context control)예요.
서브에이전트의 가장 흔하고 직관적인 사용 사례는 별도의 컨텍스트 창에서 찾기/검색/요약을 하게 해서, 부모 에이전트가 Glob / Grep / Read 같은 호출로 컨텍스트 창을 낭비하지 않고 바로 본 작업에 들어갈 수 있게 하는 거예요.
이상적인 서브에이전트 응답은 아마 위에서 본 이상적인 애드혹 압축 결과와 비슷할 거예요. 서브에이전트가 이런 결과를 내게 하는 건 쉽지 않지만, 충분히 그만한 가치가 있어요.
더 잘 작동하는 것: 빈번한 의도적 압축
제가 이야기하고 싶은, 그리고 지난 몇 달간 도입한 기법들은 제가 “빈번한 의도적 압축(frequent intentional compaction)“이라고 부르는 것 아래 있어요.
본질적으로, 전체 워크플로우를 컨텍스트 관리 중심으로 설계하고, 컨텍스트 사용률을 40%-60% 범위로 유지하는 거예요(문제의 복잡도에 따라 달라요).2
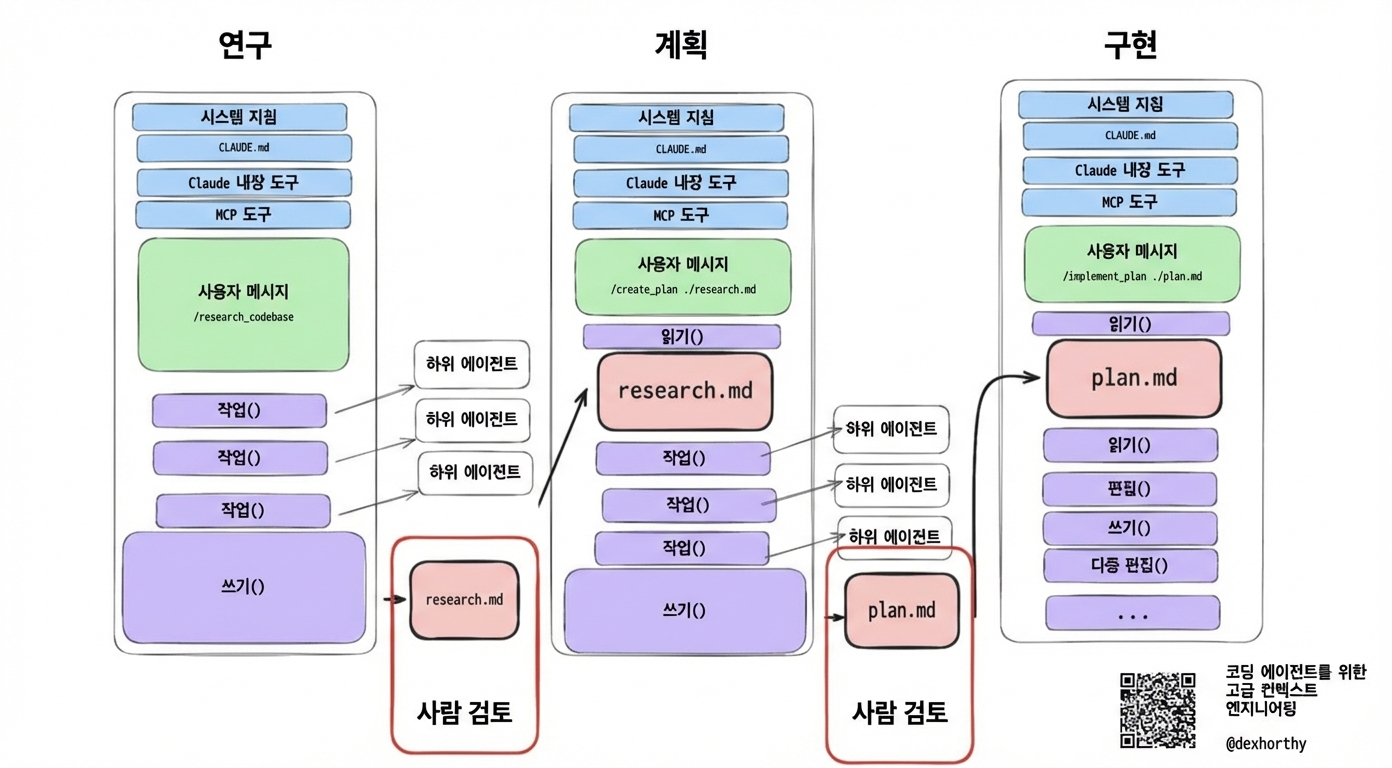
우리가 하는 방식은 세 단계 정도로 나누는 거예요.
”세 단계 정도”라고 한 이유는 때로는 리서치를 건너뛰고 바로 플래닝(planning)으로 가기도 하고, 때로는 구현할 준비가 될 때까지 여러 번 리서치를 압축해서 반복하기도 하기 때문이에요.
주어진 기능이나 버그에 대해 우리는 보통 이렇게 해요:
리서치(Research)
코드베이스, 이슈와 관련된 파일들, 정보가 어떻게 흐르는지, 그리고 아마도 문제의 잠재적 원인을 이해해요.
우리의 리서치 프롬프트예요. 현재는 커스텀 서브에이전트를 사용하지만, 다른 저장소에서는 Claude Code Task() 도구를 general-agent와 함께 사용하는 더 일반적인 버전을 써요. 일반적인 버전도 거의 비슷하게 잘 작동해요.
플랜(Plan)
이슈를 수정하기 위해 취할 정확한 단계들과, 편집해야 할 파일들과 방법을 개요로 작성해요. 각 단계의 테스트/검증 단계에 대해 매우 정확하게요.
이건 우리가 플래닝에 사용하는 프롬프트예요.
구현(Implement)
플랜을 단계별로 진행해요. 복잡한 작업에서는 각 구현 단계가 검증된 후 현재 상태를 원래 플랜 파일로 다시 압축하는 경우가 많아요.
이건 우리가 사용하는 구현 프롬프트예요.
참고로 - 깃 워크트리(git worktree)8에 대해 많이 들었다면, 워크트리에서 해야 하는 건 이 단계뿐이에요. 나머지는 보통 main에서 해요.
실전에 적용하기
저는 Vaibhav와 함께 주간 라이브 코딩 세션을 해요. 고급 AI 엔지니어링 문제에 대한 해결책을 화이트보드와 코딩으로 풀어가는 건데, 제 일주일의 하이라이트 중 하나예요.
몇 주 전, 저는 이 프로세스에 대해 더 공유하기로 했어요. 우리의 사내 기법들이 LLM과 함께 작동하는 프로그래밍 언어인 BAML의 30만 줄 Rust 코드베이스에서 버그 수정을 원샷으로 할 수 있을지 궁금했거든요. @BoundaryML 저장소에서 (인정하건대 작은) 버그를 골라서 작업을 시작했어요.
주목할 점: 저는 기껏해야 아마추어 Rust 개발자이고, BAML 코드베이스에서 작업한 적이 전혀 없었어요.
리서치
- 리서치 문서를 만들고 읽었어요. Claude가 버그는 유효하지 않고 코드베이스가 맞다고 판단했어요
- 그 리서치를 버리고 더 많은 스티어링과 함께 새 리서치를 시작했어요
- 여기 최종적으로 사용한 리서치 문서가 있어요
플랜
- 리서치가 돌아가는 동안 참을성이 없어져서, 리서치 없이 Claude가 바로 구현 플랜으로 갈 수 있는지 보려고 플랜을 시작했어요 - 여기서 볼 수 있어요
- 리서치가 끝나자, 리서치 결과를 사용하는 또 다른 구현 플랜을 시작했어요 - 여기서 볼 수 있어요
플랜 둘 다 꽤 짧지만, 내용은 상당히 달라요. 이슈를 수정하는 방식도 다르고, 테스팅 접근법도 달라요. 자세한 내용은 생략하고 말하면, 둘 다 “작동은 했겠지만” 리서치를 기반으로 만든 것이 가장 적절한 위치에서 문제를 수정했고 코드베이스 컨벤션에 맞는 테스팅을 제시했어요.
구현
이건 모두 팟캐스트 녹화 전날 밤에 일어났어요. 두 플랜을 병렬로 실행하고 밤에 두 PR을 모두 제출했어요.
다음 날 오전 10시 PT에 쇼에 나왔을 때, 리서치와 함께한 플랜의 PR은 이미 @aaron에게 승인받은 상태였어요. 그는 제가 팟캐스트용으로 뭔가 하고 있다는 것도 몰랐어요. 다른 건 닫았어요.
그래서 원래 4가지 목표 중에서:
| 목표 | 달성 |
|---|---|
| 브라운필드 코드베이스에서 작동 | ✅ (30만 줄 Rust 프로젝트) |
| 복잡한 문제 해결 | 미확인 |
| 슬롭 없음 | ✅ (PR 머지됨) |
| 멘탈 얼라인먼트 유지 | 미확인 |
복잡한 문제 해결하기
Vaibhav는 여전히 회의적이었고, 저는 더 복잡한 문제를 해결할 수 있는지 보고 싶었어요.
그래서 몇 주 후, 우리 둘은 7시간(리서치/플랜에 3시간, 구현에 4시간)을 투자해서 BAML에 취소 및 WASM 지원을 추가하는 3만 5천 줄을 배포했어요. 취소 PR은 지난주 머지됐어요. WASM은 아직 열려있지만, 브라우저의 JS 앱에서 WASM 컴파일된 Rust 런타임을 호출하는 작동하는 데모가 있어요.
취소 PR은 마무리하는 데 조금 더 손이 필요했지만, 하루 만에 놀라운 진전을 얻었어요. Vaibhav는 이 PR 각각이 BAML 팀의 시니어 엔지니어가 완료하는 데 3-5일이 걸렸을 것으로 추정했어요.
✅ 그래서 우리는 복잡한 문제도 해결할 수 있어요.
이건 마법이 아니에요
예시에서 제가 리서치 결과가 틀려서 버린 부분 기억하세요? 아니면 저와 Vaibhav가 7시간 동안 완전히 몰입해서 작업한 것? 이걸 할 때는 작업에 깊이 관여해야 해요. 그렇지 않으면 작동하지 않아요.
모든 문제를 해결해줄 마법의 프롬프트를 찾아 헤매는 사람들이 항상 있어요. 그런 거 없어요.
리서치/플랜/구현 흐름을 통한 빈번한 의도적 압축은 성능을 더 좋게 만들어요. 하지만 어려운 문제도 해결할 만큼 좋게 만드는 건 파이프라인에 레버리지 높은 사람의 리뷰를 넣는 거예요.
창피했던 순간들
몇 주 전, @blakesmith와 저는 7시간 동안 앉아서 parquet-java에서 hadoop 의존성을 제거10하려고 했어요 - 무엇이 잘못됐고 왜인지에 대한 딥다이브는 다른 글에서 할게요. 충분히 말하면 잘 안 됐어요. 요약하면 리서치 단계가 의존성 트리를 충분히 깊이 파고들지 못했고, 깊이 중첩된 hadoop 의존성을 도입하지 않고 클래스를 업스트림으로 옮길 수 있다고 가정했어요.
7시간 만에 프롬프트로 해결할 수 없는 크고 어려운 문제들이 있어요. 우리는 여전히 호기심과 설렘을 가지고 친구들, 파트너들과 한계를 밀어붙이고 있어요. 여기서 얻은 또 다른 교훈은 아마 코드베이스 전문가가 적어도 한 명은 필요하다는 거예요. 근데 그때는 우리 둘 다 아니었거든요.
인간 레버리지(Human Leverage)에 대해
이 글에서 딱 하나만 기억한다면, 이거예요:
나쁜 코드 한 줄은… 나쁜 코드 한 줄이에요.
하지만 나쁜 플랜 한 줄은 수백 줄의 나쁜 코드로 이어질 수 있어요.
그리고 나쁜 리서치 한 줄, 코드베이스가 어떻게 작동하는지나 특정 기능이 어디 있는지에 대한 오해는 수천 줄의 나쁜 코드를 만들 수 있어요.
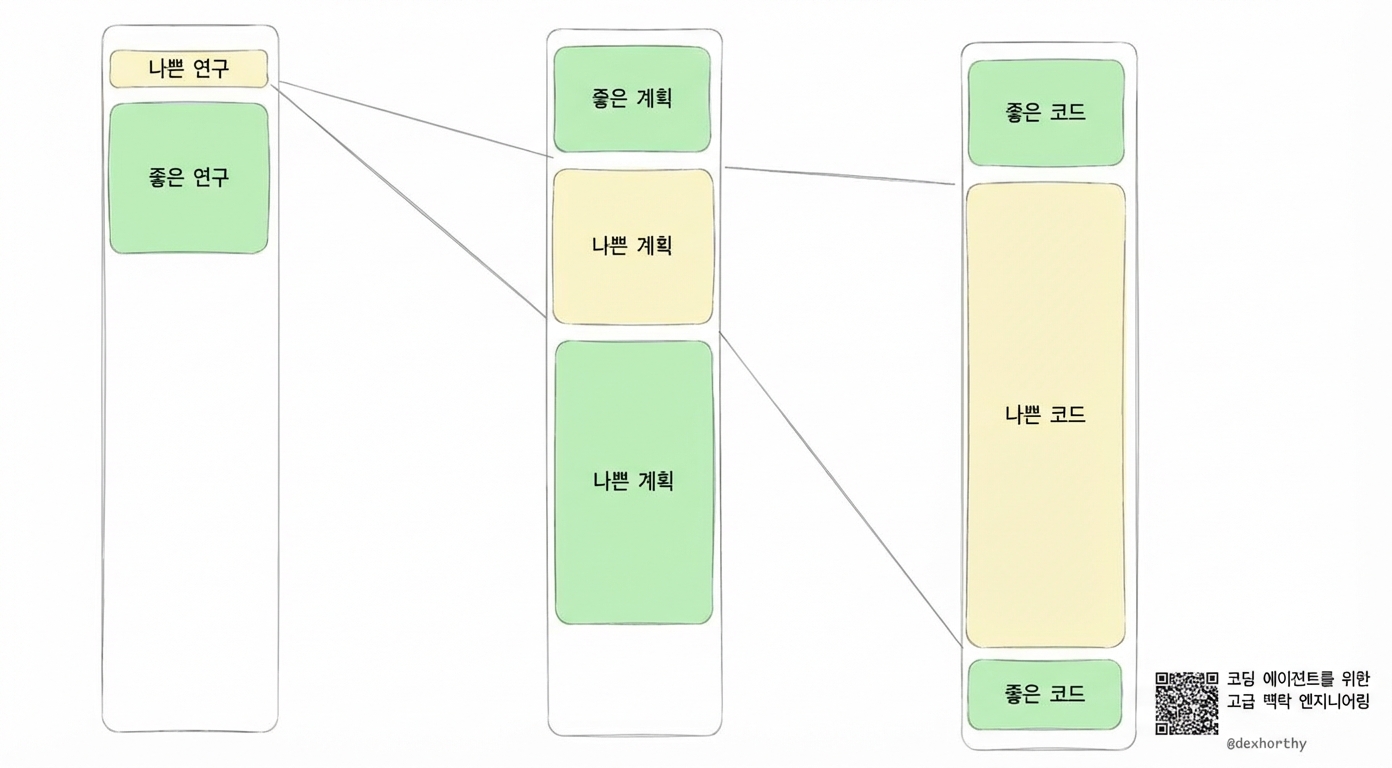
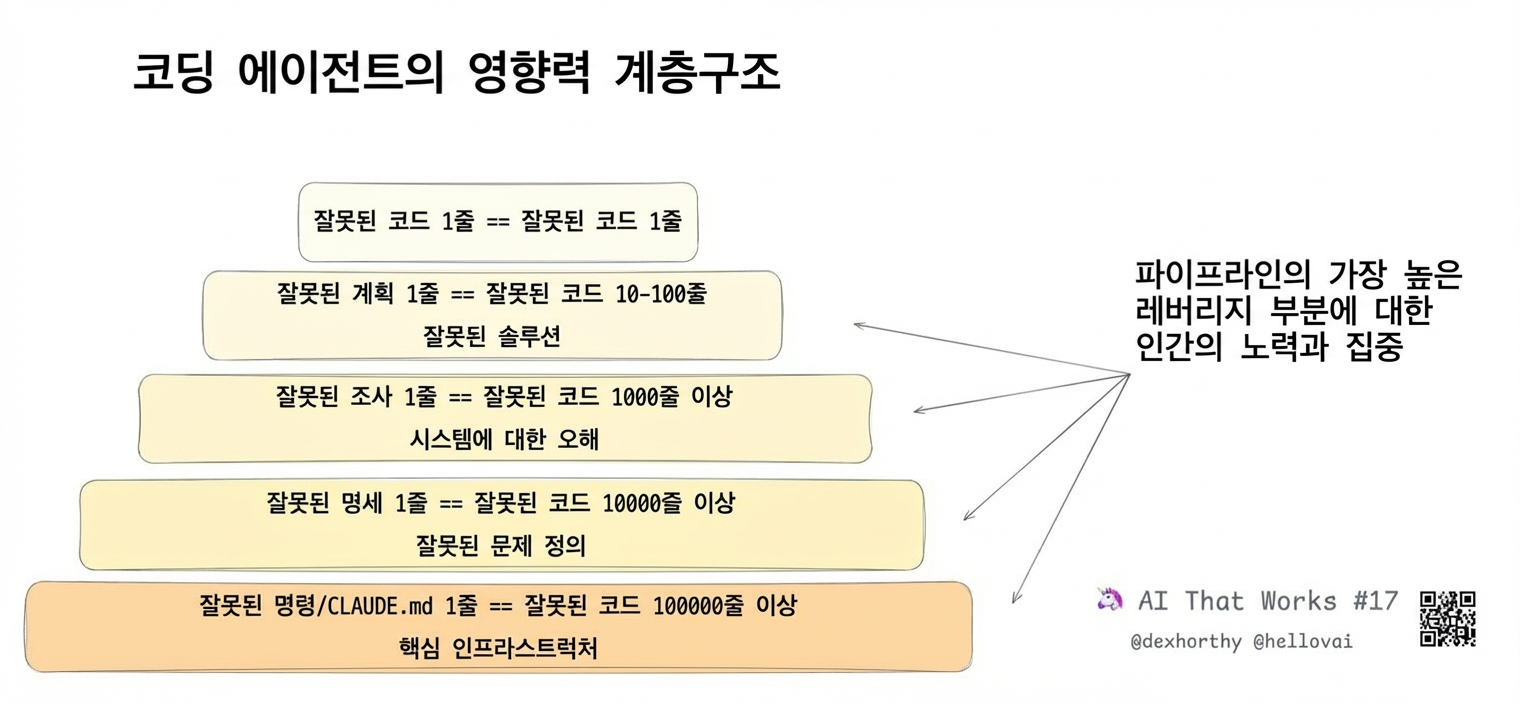
그래서 사람의 노력과 주의는 파이프라인에서 레버리지가 가장 큰 부분에 집중해야 해요.
코드를 리뷰할 때보다 리서치와 플랜을 리뷰할 때 더 큰 레버리지를 얻을 수 있어요.
코드 리뷰는 뭘 위한 건가요?
코드 리뷰가 뭘 위한 건지에 대해서는 사람마다 의견이 다양해요.
저는 Blake Smith9의 “소프트웨어 팀을 위한 코드 리뷰 필수사항”에서 제시한 관점을 선호해요. 그는 코드 리뷰에서 가장 중요한 건 멘탈 얼라인먼트(mental alignment)라고 말해요 - 팀원들이 코드가 어떻게, 왜 변하는지 다 같이 파악하고 있는 거죠.
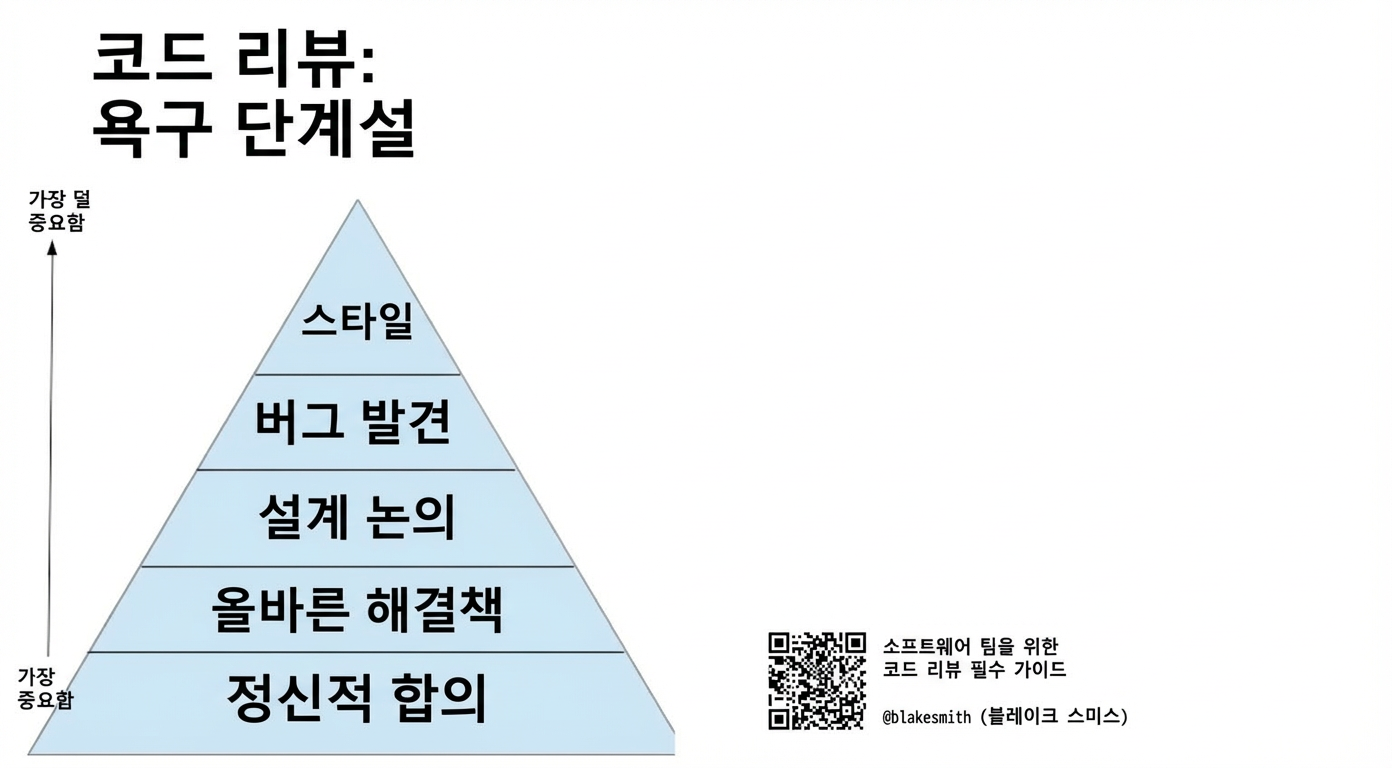
2천 줄짜리 Go PR들 기억하세요? 물론 코드가 정확하고 잘 설계되었는지도 중요했지만, 팀 내부의 불안과 좌절의 가장 큰 원인은 멘탈 얼라인먼트의 부족이었어요. 저는 우리 제품이 뭔지, 어떻게 작동하는지 점점 감을 잃어가고 있었거든요.
엄청나게 생산적인 AI 코더와 일해본 사람이라면 비슷한 경험이 있을 거예요.
사실 이게 우리에게 리서치/플랜/구현에서 가장 중요한 부분이에요. 모두가 훨씬 더 많은 코드를 배포하게 되면, 코드베이스의 훨씬 더 큰 부분이 어느 시점에서든 어떤 엔지니어에게든 낯설어질 거예요. 이건 피할 수 없는 부작용이에요.
리서치/플랜/구현이 대부분의 팀에게 맞는 접근법이라고 설득하려는 건 아니에요 - 아마 아닐 거예요. 하지만 반드시 갖춰야 할 엔지니어링 프로세스는:
- 팀원들의 이해를 일치시키는 것
- 팀원들이 코드베이스의 낯선 부분을 빠르게 배울 수 있게 하는 것
대부분의 팀에게 이건 PR과 내부 문서예요. 우리에게는 이제 스펙, 플랜, 리서치예요.
매일 2000줄의 Go 코드를 읽을 수는 없어요. 하지만 잘 작성된 200줄짜리 구현 플랜은 읽을 수 있어요.
뭔가 고장났을 때 40개가 넘는 데몬 코드 파일을 한 시간 넘게 뒤질 수 없어요(음, 할 수는 있지만 하고 싶지 않아요). 리서치 프롬프트를 적절히 유도해서 어디를 왜 봐야 하는지 핵심만 빠르게 파악할 수는 있어요.
요약
기본적으로 우리에게 필요한 모든 걸 얻었어요.
| 목표 | 달성 |
|---|---|
| 브라운필드 코드베이스에서 작동 | ✅ |
| 복잡한 문제 해결 | ✅ |
| 슬롭 없음 | ✅ |
| 멘탈 얼라인먼트 유지 | ✅ |
(아, 맞다, 참고로 우리 3인 팀은 매달 Opus에 약 $12,000(한화 약 1,600만 원) 정도 쓰고 있어요)
제가 또 다른 콧수염 기른 허풍쟁이 영업사원이라고 생각하지 않도록 솔직히 말할게요 - 이게 모든 문제에 완벽하게 작동하지는 않아요(parquet-java, 다시 도전할 거예요).
8월에 팀 전체가 2주 동안 정말 까다로운 레이스 컨디션(race condition)에서 맴돌았어요. Go에서 MCP sHTTP keepalive 문제로 토끼굴에 빠져들었고 다른 많은 막다른 길들도 있었어요.
하지만 이제 그게 예외예요. 일반적으로 이건 우리에게 잘 작동해요. 우리 인턴은 첫날 2개 PR을, 8일차에는 10개 PR을 배포했어요. 다른 사람에게도 작동할지 정말 회의적이었지만, 저와 Vaibhav는 7시간 만에 3만 5천 줄의 작동하는 BAML 코드를 배포했어요. (Vaibhav를 만나본 적 없다면, 그는 코드 설계와 품질에 관해서 제가 아는 가장 꼼꼼한 엔지니어 중 한 명이에요.)
앞으로
코딩 에이전트는 결국 상품화될 거라고 꽤 확신해요.
어려운 건 팀과 워크플로우의 변화예요. AI가 코드의 99%를 작성하는 세계에서는 협업에 관한 모든 것이 바뀔 거예요.
이걸 못 알아내면 먼저 알아낸 사람한테 한 바퀴 뒤처질 거예요. 확실해요.
OSS 메인테이너를 위해
저자는 복잡한 OSS 프로젝트 메인테이너와 직접 페어링하면서 이 기법의 한계를 배우고 싶다고 해요. 중요한 인사이트는: 이 워크플로우를 배우는 가장 좋은 방법은 1:1 직접 페어링이라는 거예요. 저자는 샌프란시스코에서 토요일 7시간 동안 함께 무언가를 만들어보자고 제안하고 있어요.
역자 주
- 랄프 위검(Ralph Wiggum): 미국 애니메이션 <심슨 가족>의 캐릭터로, 사랑스럽지만 단순하고 예측 가능한 행동을 보여요. Geoff가 이 이름을 붙인 이유는 AI가 랄프처럼 단순하고 예측 가능한 방식으로 작동할 때 오히려 제어하기 쉽다는 점을 비유한 거예요. ↩
- 역주: 40-60%를 “딱 맞는 구간”으로 오해하기 쉬운데, 사실은 “여기까지만”이라는 상한선에 가까워요. 40% 미만이라고 문제될 건 없어요—컨텍스트가 비어 있으면 에이전트가 오히려 여유 있게 작업할 수 있거든요. 문제는 60%를 넘어갈 때 시작돼요. 노이즈가 쌓이고, 추론이 흐려지고, 엉뚱한 길로 새기 쉬워져요. ↩
- Y Combinator: 실리콘밸리의 대표적인 스타트업 액셀러레이터. 에어비앤비, 드롭박스, 스트라이프, 레딧 등 유명 스타트업을 배출했어요. 3개월간 투자와 멘토링을 제공하고, 데모데이에서 투자자들에게 발표하는 프로그램이에요. ↩
- Lenny’s Podcast: 레니 라치츠키(Lenny Rachitsky)가 진행하는 제품/성장 분야 팟캐스트. 전직 에어비앤비 PM이었던 그가 테크 업계 리더들과 인터뷰하는 형식으로, 실리콘밸리에서 영향력 있는 팟캐스트 중 하나예요. ↩
- PR(Pull Request): 깃허브 등에서 코드 변경을 제안하고 리뷰받는 단위예요. 다른 개발자들이 코드를 검토하고, 승인(approve)되면 메인 코드베이스에 머지(merge)됩니다. ↩
- WASM(WebAssembly): 브라우저에서 네이티브에 가까운 속도로 코드를 실행할 수 있게 해주는 바이너리 포맷이에요. C, C++, Rust 등의 언어를 컴파일해서 웹에서 실행할 수 있게 해줍니다. ↩
- Mitchell Hashimoto: HashiCorp(Terraform, Vagrant, Consul 등 인프라 도구로 유명한 회사) 공동창업자. Ghostty는 그가 Zig 언어로 개발 중인 고성능 터미널 에뮬레이터예요. ↩
- Git worktree: 하나의 Git 저장소에서 여러 브랜치를 동시에 별도 디렉터리로 체크아웃할 수 있는 기능이에요. 한 브랜치에서 작업하면서 다른 브랜치의 코드도 참조해야 할 때 유용해요. ↩
- Blake Smith: HashiCorp 전 엔지니어로, 소프트웨어 팀 문화와 코드 리뷰에 관한 글로 알려져 있어요. 그의 블로그에서 엔지니어링 프랙티스에 대한 인사이트를 공유하고 있습니다. ↩
- Parquet/Hadoop: Apache Parquet은 빅데이터 분석에 최적화된 열 지향(columnar) 저장 포맷이고, Hadoop은 대용량 데이터를 분산 처리하기 위한 프레임워크예요. Hadoop 의존성을 제거한다는 건 더 가볍고 독립적인 라이브러리를 만들겠다는 의미입니다. ↩
• • •
저자 소개: Dex Horthy는 HumanLayer의 창업자로, AI 코딩 에이전트와 스펙 주도 개발 워크플로우를 연구하고 있습니다.
참고: 이 글은 Dex Horthy가 GitHub에 게시한 아티클을 번역하고 요약한 것입니다. 마케팅 관련 섹션은 번역에서 생략되었습니다.
원문: Advanced Context Engineering for Coding Agents - Dex Horthy, HumanLayer (2025년 8월)
생성: Claude (Anthropic)