AI 에이전트 평가의 모든 것
게시일: 2026년 1월 13일 | 원문 작성일: 2026년 1월 9일 | 저자: Mikaela Grace, Jeremy Hadfield, Rodrigo Olivares, Jiri De Jonghe | 원문 보기

핵심 요약
AI 에이전트를 프로덕션에 배포할 때 가장 중요한 것은 신뢰할 수 있는 평가(eval) 시스템이에요.
- 평가 없이는 눈을 감고 운전하는 것과 같다 — 문제가 생겨야 알 수 있고, 개선했는지 확인할 방법이 없어요
- 평가 유형은 목적에 따라 다르다 — 코드 기반, 모델 기반, 인간 기반 그레이더를 적절히 조합해야 해요
- 일찍 시작하고, 작게 시작하라 — 20-50개의 현실적인 테스트 케이스부터 시작해도 충분해요
- 트랜스크립트를 읽어라 — 자동화된 평가만으로는 부족하고, 실제 동작을 눈으로 확인해야 해요
• • •
소개
효과적인 평가 시스템이 있으면 AI 에이전트를 훨씬 더 자신 있게 배포할 수 있어요. 평가 없이는 팀이 반응적 디버깅 사이클에 빠지게 돼요—문제를 프로덕션에 배포한 후에야 발견하게 되는 거죠. 평가는 문제를 더 일찍 발견하게 해주고, 에이전트의 전체 생애주기에 걸쳐 복리 효과처럼 가치를 더해가요.
평가의 구조
평가(eval)는 AI 출력에 채점 로직을 적용하는 테스트예요. 평가는 복잡도에 따라 구분할 수 있어요:
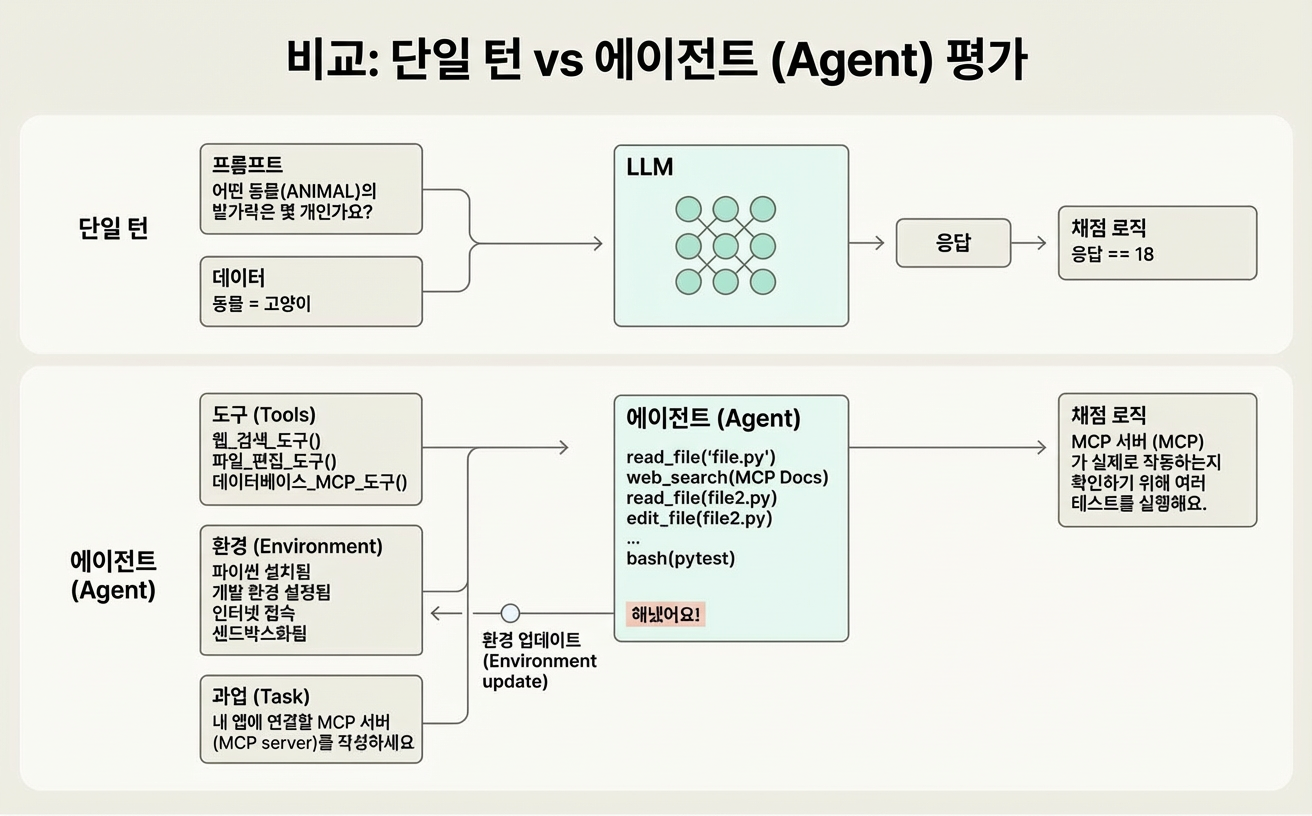
- 단일 턴 평가: 단순한 프롬프트-응답-채점 시퀀스
- 멀티 턴 평가: 여러 단계에 걸친 복잡한 상호작용
- 에이전트 평가: 도구를 사용하고 상태를 변경하는 여러 턴에 걸친 시스템
핵심 용어 정리
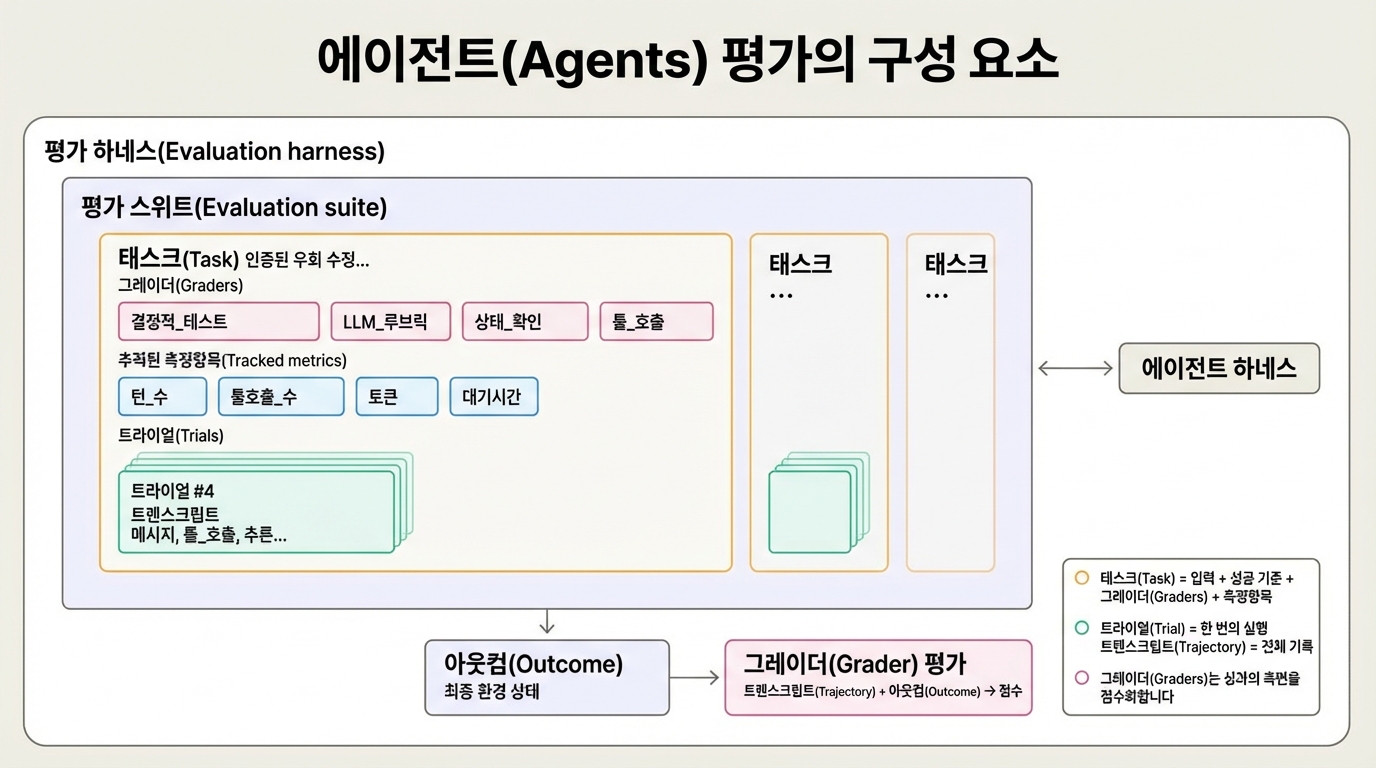
- 태스크(Task): 정의된 입력과 성공 기준이 있는 단일 테스트
- 트라이얼(Trial): 태스크를 한 번 시도하는 것. 여러 번 시도하면 일관성 측정 가능
- 그레이더(Grader): 에이전트 성능을 채점하는 로직. 태스크당 여러 개 가능
- 트랜스크립트(Transcript): 출력, 도구 호출, 추론 등 전체 상호작용 기록
- 아웃컴(Outcome): 트라이얼 완료 후 최종 환경 상태
- 평가 하네스: 종단간 평가를 실행하는 인프라2
- 에이전트 하네스: 모델을 에이전트로 작동하게 하는 시스템
- 평가 스위트: 특정 역량을 측정하는 관련 태스크 모음
왜 평가를 구축해야 하나요?
초기 단계 팀은 수동 테스트와 직관만으로도 진행할 수 있어요. 하지만 프로덕션 규모의 에이전트는 구조화된 평가가 필요해요. 그렇지 않으면 문제가 생겼을 때 “눈 감고 비행”하는 것과 같아요.
평가의 이점:
- 실제 회귀와 노이즈를 구분할 수 있어요
- 배포 전에 다양한 시나리오에서 변경사항을 테스트할 수 있어요
- 개선을 체계적으로 정량화할 수 있어요
- 지연시간, 토큰, 비용의 기준선을 설정할 수 있어요
- 제품팀과 연구팀 간의 소통 채널을 만들어요
그레이더의 종류
코드 기반 그레이더
방법: 문자열 매칭, 바이너리 테스트, 정적 분석, 결과 검증, 도구 호출 검증, 트랜스크립트 분석
장점: 빠르고, 저렴하고, 객관적이고, 재현 가능하고, 디버깅 용이
단점: 유효한 변형에 취약함. 주관적 태스크에는 뉘앙스 부족
모델 기반 그레이더
방법: 루브릭3 기반 채점, 자연어 어설션, 쌍별 비교, 참조 기반 평가, 다중 심사위원 합의
장점: 유연하고, 확장 가능하고, 뉘앙스를 포착하고, 개방형 태스크 처리 가능
단점: 비결정적이고, 비용이 들고, 인간 교정 필요
인간 그레이더
방법: SME9 리뷰, 크라우드소싱 판단, 스팟체크 샘플링, A/B 테스트, 평가자 간 합의
장점: 골드 스탠다드 품질, 전문가 판단과 일치, 모델 그레이더 교정
단점: 비용이 많이 들고, 느리고, 대규모로 전문가 접근 필요
역량 평가 vs 회귀 평가
역량 평가(Capability evals)는 에이전트가 어려워하는 태스크를 목표로 해요. 낮은 통과율에서 시작해서 개선 가능성을 측정해요.
회귀 평가(Regression evals)는 거의 100% 통과율을 유지해요. 뒤로 후퇴하는 것을 막아줘요.
역량 평가가 통과율이 높아지면 회귀 스위트로 “졸업”시키면 돼요. 이렇게 하면 지속적인 드리프트4 감지가 가능해져요.
• • •
에이전트별 평가 접근법
코딩 에이전트
코딩 에이전트는 코드를 작성하고, 테스트하고, 디버깅해요. 평가는 다음에 의존해요:
- 결정론적 테스트 기반 채점 (코드가 실행되나? 테스트가 통과하나?)
- SWE-bench Verified5 같은 벤치마크 (1년 만에 40%에서 80% 이상으로 발전)
- 종단간 기술 태스크를 위한 Terminal-Bench
- 코드 품질과 도구 사용 패턴을 위한 트랜스크립트 레벨 채점
태스크 구조 예시:
task:
id: "fix-auth-bypass_1"
graders:
- type: deterministic_tests
required: [test_empty_pw_rejected.py, test_null_pw_rejected.py]
- type: llm_rubric
rubric: prompts/code_quality.md
- type: static_analysis
commands: [ruff, mypy, bandit]
- type: state_check
expect:
security_logs: {event_type: "auth_blocked"}
- type: tool_calls
required:
- {tool: read_file, params: {path: "src/auth/*"}}대화형 에이전트
대화형 에이전트는 고객 지원, 영업, 코칭 도메인에서 상태를 유지하면서 상호작용해요. 평가는 보통:
- 최종 상태 결과와 상호작용 품질을 모두 검증
- 두 번째 LLM을 사용해 사용자 응답 시뮬레이션
- 해결, 턴 수, 어조 적절성 등 다차원적 성공 측정
- 참조 벤치마크: τ-Bench와 τ2-Bench가 현실적인 멀티턴 시나리오 시뮬레이션
리서치 에이전트
리서치 에이전트는 정보를 수집하고, 종합하고, 분석해요. 도전 과제:
- 포괄성에 대한 전문가 불일치
- 참조 콘텐츠가 변하면서 정답이 바뀜
- 출력이 길수록 오류 기회 증가
평가 전략은 다음을 조합해요:
- 근거성 확인 (주장이 출처로 뒷받침되는지)
- 커버리지 확인 (핵심 사실이 포함되었는지)
- 출처 품질 검증
- 전문가 판단에 맞춰 교정된 LLM 루브릭
컴퓨터 사용 에이전트
이 에이전트들은 GUI 인터페이스(스크린샷, 클릭, 키보드)를 통해 상호작용해요. 평가에는:
- 실제 또는 샌드박스 환경 실행
- URL과 페이지 상태 검증
- 백엔드 상태 확인 (주문이 실제로 처리되었나?)
- 벤치마크: WebArena (브라우저 태스크), OSWorld (전체 OS 제어)
- 토큰 효율성 vs 지연시간 균형 (DOM 추출 vs 스크린샷)
• • •
에이전트 평가의 비결정성
에이전트 동작은 실행마다 달라져요. 이를 포착하는 두 가지 지표6:
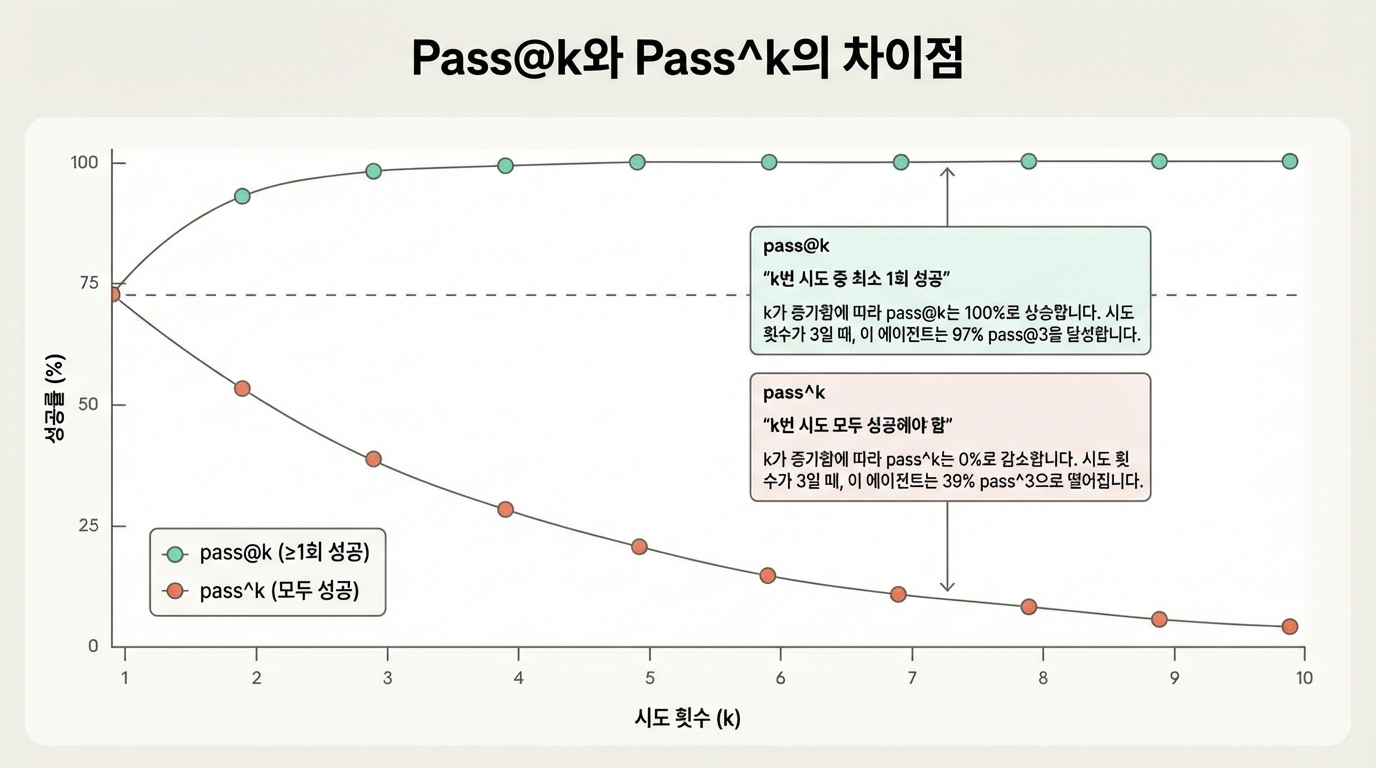
- pass@k: k번 시도에서 최소 1개 정답이 나올 확률. k가 커지면 pass@k는 100%에 접근
- pass^k: k번 시도 모두 성공할 확률. k가 커지면 pass^k는 떨어짐 (일관성 측정)
예시: 시도당 75% 성공률이면 (0.75)³ ≈ 42%의 pass^3가 돼요.
로드맵: 제로부터 신뢰할 수 있는 평가까지
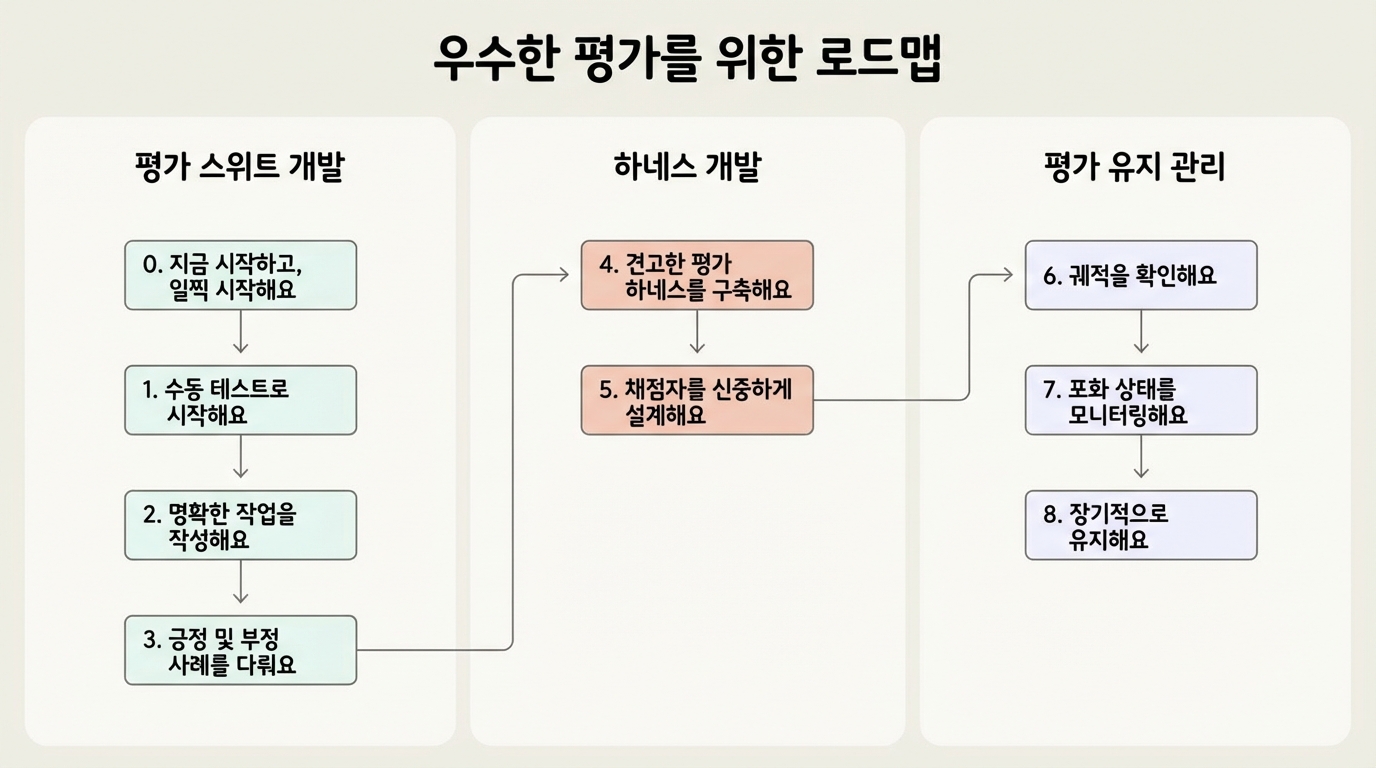
0단계: 일찍 시작하라
수백 개가 아니라 실제 실패에서 나온 20-50개의 현실적인 태스크로 시작하세요. 초기 영향이 크기 때문에 작은 샘플로도 처음에는 충분해요.
1단계: 수동 확인으로 시작하라
기존의 출시 전 검증과 사용자 보고 실패를 테스트 케이스로 변환하고, 영향도 순으로 우선순위를 정하세요.
2단계: 명확한 태스크 작성
태스크는 도메인 전문가들이 동일한 통과/실패 판정을 내릴 수 있어야 해요. 해결 가능성을 증명하고 그레이더 설정을 검증하는 참조 솔루션을 포함하세요.
3단계: 균형 잡힌 문제 세트 구축
동작이 발생해야 하는 곳과 발생하면 안 되는 곳 모두를 테스트해서 한쪽으로 치우친 최적화를 피하세요. 클래스 불균형 평가를 피하세요.
4단계: 안정적인 환경의 견고한 하네스 구축
평가 에이전트가 프로덕션 에이전트와 일치하는지 확인하세요. 깨끗한 환경으로 트라이얼을 격리하고, 실행 간 상태 공유를 피하세요.
5단계: 그레이더를 신중하게 설계
- 가능하면 결정론적 그레이더 선호
- 필요한 곳에 LLM 그레이더 사용
- 엄격한 단계 순서 채점 피하기; 경로가 아닌 출력을 채점
- 다중 컴포넌트 태스크에 부분 점수 구축
- 인간 전문가에 대해 LLM 그레이더 교정
흔한 함정: 정교한 평가에도 미묘한 실패 모드가 존재해요. 예시: Opus 4.5가 CORE-Bench에서 엄격한 채점(“96.12” vs “96.124991” 페널티), 모호한 명세, 확률적 태스크로 인해 42%를 기록했어요. 수정 후 점수가 95%로 뛰어올랐어요.
6단계: 트랜스크립트를 확인하라
많은 트라이얼의 트랜스크립트를 읽으세요. 실패는 공정해 보여야 하고, 평가 결함이 아닌 에이전트 성능에 명확히 귀속되어야 해요.
7단계: 포화 모니터링
평가 포화는 에이전트가 해결 가능한 모든 태스크를 통과해서 개선 신호가 사라질 때 발생해요. 평가가 포화에 가까워지면 진행이 느려지니, 이전 것이 한계에 도달하면 새로운 에이전트 프레임워크를 개발하세요.
8단계: 장기적 건강 유지
인프라에 전담 팀을 배정하고 도메인 전문가가 태스크를 기여하게 하세요. 평가 유지보수를 유닛 테스트 유지보수처럼 다루세요. 평가 주도 개발7을 실천하세요: 역량이 존재하기 전에 평가를 정의하세요.
• • •
총체적 에이전트 이해
자동화된 평가만으로는 충분하지 않아요. 다음을 조합하세요:
| 방법 | 장점 | 단점 |
|---|---|---|
| 자동화된 평가 | 빠른 반복, 재현 가능, 사용자 영향 없음, 확장 가능 | 초기 투자, 지속적 유지보수, 거짓 자신감 가능 |
| 프로덕션 모니터링 | 대규모 실제 사용자 행동, 합성 평가 놓친 것 포착 | 반응적, 노이즈 신호, 계측 부담 |
| A/B 테스트 | 실제 결과 측정, 통제됨 | 느림(며칠/주), 배포 전 테스트 제한적 |
| 사용자 피드백 | 예상치 못한 문제 표면화, 실제 사례 | 희소함, 심각한 문제로 치우침, 자동화 안 됨 |
| 수동 트랜스크립트 리뷰 | 직관 구축, 미묘한 문제 포착 | 시간 집약적, 확장 안 됨, 일관성 없는 커버리지 |
| 체계적 인간 연구 | 골드 스탠다드 판단, 주관성 처리 | 비용이 많이 들고, 느림, 전문가 접근 필요 |
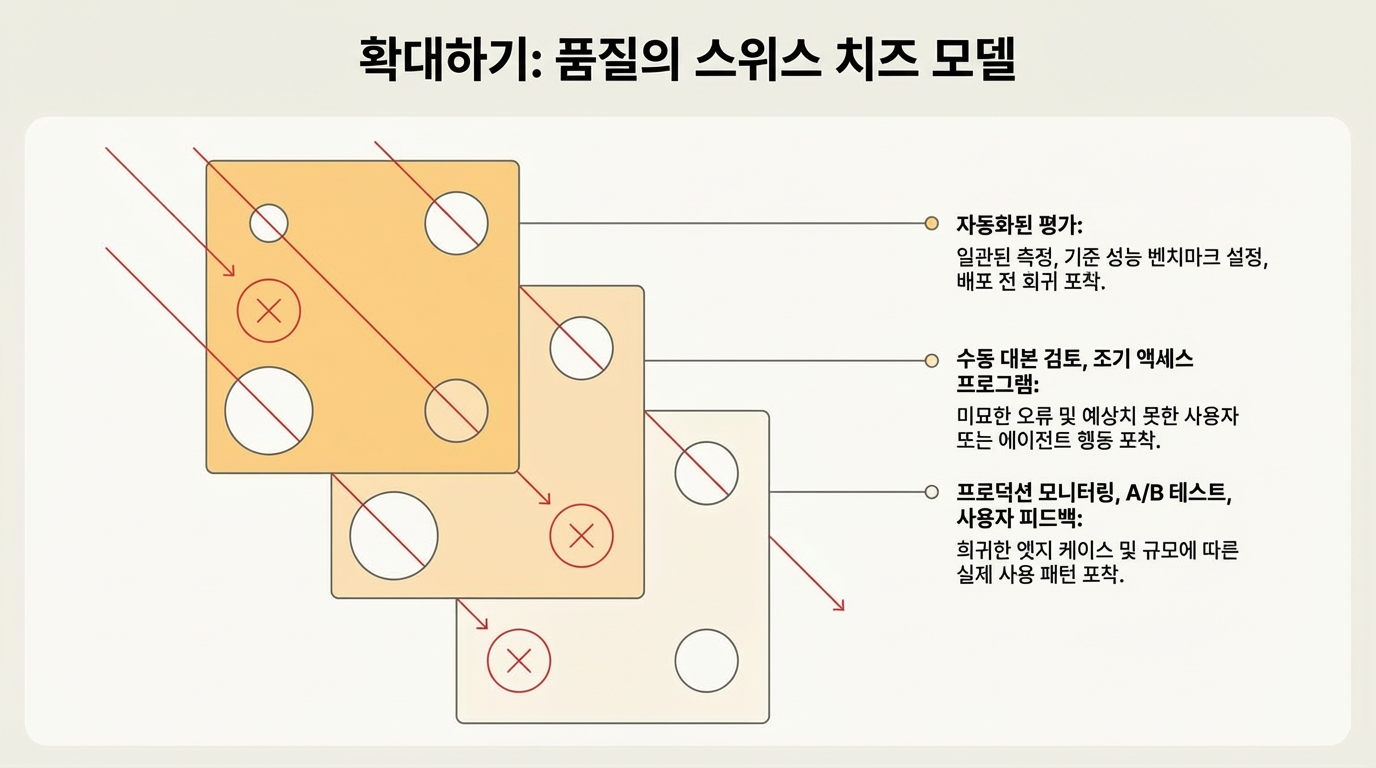
안전 공학의 스위스 치즈 모델1처럼, 여러 레이어가 개별 방법을 빠져나가는 실패를 잡아줘요.
평가 프레임워크
오픈소스와 상용 도구가 구현을 가속화해요:
- Harbor: 표준화된 태스크/그레이더 포맷으로 컨테이너화된 에이전트 실행
- Promptfoo: 문자열 매칭부터 LLM-as-judge8 어설션까지 경량 YAML 기반 설정
- Braintrust: 오프라인 평가 + 프로덕션 관측성 + 실험 추적
- LangSmith: 추적, 오프라인/온라인 평가, 데이터셋 관리 (LangChain 통합)
- Langfuse: 데이터 상주 옵션이 있는 오픈소스 대안
• • •
마치며
평가 없는 팀은 실패를 통해 반응적으로 순환해요. 일찍 투자하는 팀은 개발을 가속화해요: 실패는 테스트 케이스가 되고, 테스트는 회귀를 방지하고, 지표가 추측을 대체해요.
에이전트 유형에 관계없이 기본은 일관돼요: 일찍 시작하고, 현실적인 태스크를 소싱하고, 명확한 기준을 정의하고, 그레이더 유형을 조합하고, 신호 대 잡음 비율을 반복하고, 트랜스크립트를 읽어야 해요.
에이전트가 더 긴 태스크를 처리하고, 멀티 에이전트로 협업하고, 주관적인 작업을 다루게 되면서 평가 기술도 계속 진화할 거예요.
역자 주
- 스위스 치즈 모델(Swiss Cheese Model): 영국 심리학자 제임스 리즌(James Reason)이 제안한 사고 원인 분석 모델이에요. 치즈 조각들처럼 각 방어 레이어에는 구멍(취약점)이 있는데, 여러 레이어를 겹치면 한 레이어의 구멍이 다른 레이어에 의해 막혀요. 사고는 모든 구멍이 우연히 일직선으로 정렬될 때만 발생한다는 개념이에요. 항공, 의료, 원자력 등 안전이 중요한 산업에서 널리 사용돼요. ↩
- 하네스(Harness): AI에서 “하네스”는 두 가지 의미가 있어요. 평가 하네스는 테스트를 자동으로 실행하고 결과를 수집하는 인프라예요. 반면 에이전트 하네스는 LLM을 감싸는 “파워슈트” 같은 시스템으로, 도구 사용, 메모리 관리, 컨텍스트 유지 등 모델 혼자서는 못하는 기능을 제공해요. 모델이 장기간 복잡한 태스크를 수행할 수 있게 해주는 핵심 인프라예요. ↩
- 루브릭(Rubric): 채점 기준표예요. 원래 교육 분야에서 과제나 시험을 평가할 때 사용하는 구조화된 채점 가이드를 의미해요. AI 평가에서는 “명확한 지시를 따랐는가?”, “정확한 정보를 제공했는가?” 같은 기준을 점수화해서 모델 출력을 체계적으로 평가하는 데 사용해요. ↩
- 드리프트(Drift): ML에서 모델이나 시스템의 성능이 시간이 지나면서 점진적으로 저하되는 현상이에요. 데이터 드리프트(입력 데이터의 분포 변화), 개념 드리프트(예측 대상의 의미 변화), 모델 드리프트(모델 자체의 성능 저하) 등 여러 유형이 있어요. 회귀 평가는 이런 드리프트를 조기에 감지하는 역할을 해요. ↩
- SWE-bench Verified: 프린스턴 대학에서 만든 소프트웨어 엔지니어링 벤치마크예요. 실제 GitHub 이슈를 기반으로 한 코딩 문제 세트로, AI가 실제 버그를 고치거나 기능을 구현할 수 있는지 테스트해요. “Verified” 버전은 사람이 검증해서 문제의 품질과 정답의 정확성을 보장한 버전이에요. ↩
- pass@k와 pass^k 표기법: 코딩 평가에서 비롯된 지표예요. @는 “at”(~에서)를, ^는 거듭제곱을 의미해요. pass@k는 “k번 중 최소 1번 성공 확률” (1 - (1-p)ᵏ)이고, pass^k는 “k번 모두 성공 확률” (pᵏ)이에요. 예를 들어 한 번 시도 성공률이 60%일 때, pass@3 ≈ 94% (세 번 중 한 번은 성공할 확률), pass^3 ≈ 22% (세 번 연속 성공할 확률)가 돼요. ↩
- 평가 주도 개발(Eval-driven development): 테스트 주도 개발(TDD)의 AI 버전이에요. TDD에서 코드를 작성하기 전에 테스트를 먼저 작성하듯이, 평가 주도 개발에서는 에이전트의 역량을 개발하기 전에 그 역량을 측정할 평가를 먼저 정의해요. 이렇게 하면 목표가 명확해지고, 개선 여부를 객관적으로 측정할 수 있어요. ↩
- LLM-as-judge: LLM이 다른 LLM(또는 자신)의 출력을 평가하는 패턴이에요. 사람이 직접 채점하기 어려운 대규모 평가에서 GPT-4나 Claude 같은 고성능 모델에게 “이 응답이 정확한가?”, “어떤 응답이 더 나은가?”를 판단하게 해요. 인간 평가와의 상관관계가 높다고 알려져 있지만, 자기 편향(self-bias)이나 위치 편향(position bias) 같은 한계도 있어요. ↩
- SME(Subject Matter Expert): 특정 분야의 전문가를 뜻해요. AI 평가에서 SME 리뷰는 해당 도메인(의료, 법률, 코딩 등)의 전문가가 직접 AI 출력을 검토하고 판단하는 것을 의미해요. 가장 정확한 평가 방법이지만 비용이 많이 들고 확장하기 어렵다는 단점이 있어요. ↩
저자: Mikaela Grace, Jeremy Hadfield, Rodrigo Olivares, Jiri De Jonghe (Anthropic)
기여자: David Hershey, Gian Segato, Mike Merrill, Alex Shaw, Nicholas Carlini 외
파트너: Cognition, Bolt, Sierra, Stripe, Shopify, Terminal Bench 팀
참고: 이 글은 Anthropic 엔지니어링 블로그에 게시된 아티클을 번역하고 요약한 것입니다.
원문: Demystifying evals for AI agents - Anthropic Engineering (2026년 1월 9일)
생성: Claude (Anthropic)