LLM 시대의 가변형 소프트웨어
게시일: 2025년 1월 25일 | 원문 작성일: 2023년 3월 25일 | 저자: Geoffrey Litt | 원문 보기

역자 주: 이 글은 ChatGPT가 출시된 지 불과 4개월 후인 2023년 3월에 작성됐어요. GPT-4가 막 공개되고 ChatGPT 플러그인이 처음 발표되던 시점이죠. 그로부터 2년이 지난 지금, Claude Code, Cursor, Windsurf 같은 AI 코딩 도구들이 일상이 된 시점에서 이 글을 읽으면 저자의 예측이 얼마나 정확했는지 - 그리고 어떤 부분이 예상과 달랐는지 - 흥미롭게 비교해볼 수 있어요. 참고로, 저자는 이 아이디어를 발전시켜 2025년에 Ink & Switch에서 더 완성된 에세이를 발표했어요. 이 번역은 그 초기 버전이에요.
핵심 요약
- 엔드유저 프로그래밍의 새 시대: LLM 덕분에 일반 사용자도 자연어로 소프트웨어를 만들고 수정할 수 있는 시대가 열리고 있어요
- 챗봇의 한계: 챗 인터페이스는 유연하지만, 직접 조작 UI가 제공하는 빠른 피드백과 플로우 상태를 대체할 수 없어요
- 하이브리드 모델: 직접 조작 UI를 사용하면서 LLM이 “로컬 개발자”로서 도구 커스터마이징을 도와주는 방식이 이상적이에요
- 컴퓨테이셔널 미디어: 스프레드시트처럼 사용자가 직접 편집할 수 있는 열린 미디어가 LLM 시대에 더 중요해질 거예요
대형 언어 모델(LLM)에게 격동의 몇 주였어요. OpenAI가 코딩을 포함한 다양한 역량에서 인상적인 발전을 보여주는 GPT-4를 출시했고, Microsoft Research는 GPT-4가 거의 프롬프트 없이도 3D 비디오 게임 같은 상당히 정교한 코드를 생성할 수 있다는 논문을 발표했어요. OpenAI는 또한 ChatGPT 플러그인을 출시했는데, 이건 제가 GPT로 NBA 통계 쿼리하기에 대한 이전 포스트에서 실험해봤던 ReAct8 도구 사용 패턴의 제품화된 버전이에요.
이 모든 혼란 속에서, 많은 사람들이 당연히 궁금해하고 있어요: LLM이 소프트웨어 개발에 어떤 영향을 미칠까요?
한 가지 답은 LLM이 숙련된 전문 개발자들을 더 생산적으로 만들어줄 거라는 거예요. GitHub Copilot1이 이미 가능성을 보여줬으니 무난한 예측이죠. 개발자들 입장에서도 마음 편한 전망이에요 - 일자리 걱정 없이, 소프트웨어를 만들고 배포하는 방식도 크게 바뀌지 않을 테니까요.
하지만 저는 그게 전부가 아닐 거라고 봐요. LLM이 전문 프로그래머들에게 유용한 도구가 될 거라고 확신하지만, 그 좁은 용도에만 집중하다 보면 더 큰 변화를 놓칠 수 있어요.
왜냐고요? 머지않아 모든 컴퓨터 사용자가 간단한 소프트웨어 도구를 직접 만들고, 쓰고 있는 소프트웨어에 “이렇게 바꿔줘”라고 말할 수 있게 될 거라고 생각하기 때문이에요. 다시 말해, LLM은 엔드유저 프로그래밍2을 획기적으로 바꿀 거예요. 엔드유저 프로그래밍이란, 일반인들이 복잡한 프로그래밍을 배우지 않고도 컴퓨터의 힘을 온전히 활용하는 걸 말해요. 지금까지 이 비전의 가장 큰 걸림돌은 “머릿속 아이디어를 실행 가능한 코드로 바꾸는 과정”이었는데, LLM이 바로 그 병목을 뚫어주고 있어요.
이 가설이 정말로 실현된다면, 사람들이 소프트웨어를 사용하는 방식에 놀라운 변화가 시작될 수 있어요:
- 일회용 스크립트: 일반인들이 AI에게 “이 데이터 분석해줘”, “이 영상 편집해줘”, “이 반복 작업 자동화해줘” 같은 스크립트를 하루에도 수십 번씩 만들어서 실행시켜요.
- 일회용 GUI: 딱 하나의 작업을 위한 GUI 앱을 통째로 만들어요 - 필요한 기능만, 군더더기 없이.
- 사지 말고 만들어: 기업들이 SaaS를 사는 대신 필요에 맞는 소프트웨어를 직접 만들어요. 맞춤 소프트웨어를 만드는 비용이 확 낮아졌으니까요.
- 모딩/확장: 쓰던 소프트웨어에 기능을 추가하거나 내 방식대로 고치는 게 쉬워지면서, 소비자와 기업 모두 그런 기능을 당연히 요구하게 돼요.
- 재조합: 마음에 드는 여러 앱에서 좋은 부분만 뽑아서 섞은 나만의 하이브리드 앱을 만들어요.
이 변화들은 단순히 소프트웨어를 더 빨리 만드는 수준이 아니에요. 소프트웨어를 언제, 누가, 왜 만드는지 자체가 달라지는 거예요.
LLM + 가변형 소프트웨어: 시리즈
휴, 얘기할 게 정말 많네요.
이 글을 시작으로, LLM이 소프트웨어의 생성과 배포에 어떤 변화를 가져올지 깊이 파헤쳐 볼 거예요. 더 나아가 사람들이 소프트웨어를 사용하는 방식 전반도 다룰 거예요. 앞으로 다룰 질문들은 이런 것들이에요:
- 상호작용 모델: 어떤 상호작용 방식이 어떤 작업에 맞을까요? 언제 챗봇이 좋고, 언제 일회용 스크립트가 좋고, 언제 맞춤 GUI가 좋을까요?
- 소프트웨어 커스터마이징: LLM이 어떻게 사용자가 뜯고, 조립하고, 확장할 수 있는 가변형 소프트웨어를 가능하게 할까요?
- 의도 명세: 엔드유저가 LLM에게 원하는 걸 어떻게 전달할까요?
- 퍼지 번역기: LLM이 데이터를 유연하게 변환하는 능력이 이전에는 불가능했던 공유 데이터 기반을 어떻게 가능하게 할까요?
- 사용자 역량 강화: LLM 시대에 “역량 강화/주체성” 대 “위임/자동화” 사이의 균형을 어떻게 잡아야 할까요?
이 아이디어들에 대한 향후 포스트를 받아보고 싶으시면, 이메일 뉴스레터에 가입하시거나 RSS를 구독하세요. 포스트는 꽤 드물게, 최대 월 1회 정도 나올 거예요.
• • •
챗봇을 쓸 때와 쓰지 않을 때?
오늘은 기본적인 질문으로 시작할게요: LLM 시대에 사용자 상호작용 방식은 어떻게 바뀔까요? 특히, 어떤 작업들이 챗봇으로 대체될 수 있을까요? 엔드유저의 역량을 강화하는 방법을 생각할 때, 이 질문에 대한 답이 매우 중요해요.
이 글이 어디로 가는지 미리 말씀드릴게요: ChatGPT가 Siri보다 훨씬 뛰어나지만, 챗 UI로는 잘 안 되는 작업들이 많고, 그런 작업에는 여전히 그래픽 인터페이스가 필요하다는 주장을 할 거예요. 그런 다음 LLM이 UI를 만들어주는 하이브리드 방식에 대해 얘기할게요.
결국, 제가 흥미롭게 생각하는 지점에 도달할 거예요: 사용자가 직접 배우고 만들어갈 수 있는 열린 컴퓨테이셔널 미디어, 그리고 그 안에서 협력자 역할을 하는 LLM. 그 지점에 가면 아래의 이상한 다이어그램도 이해가 될 거예요:
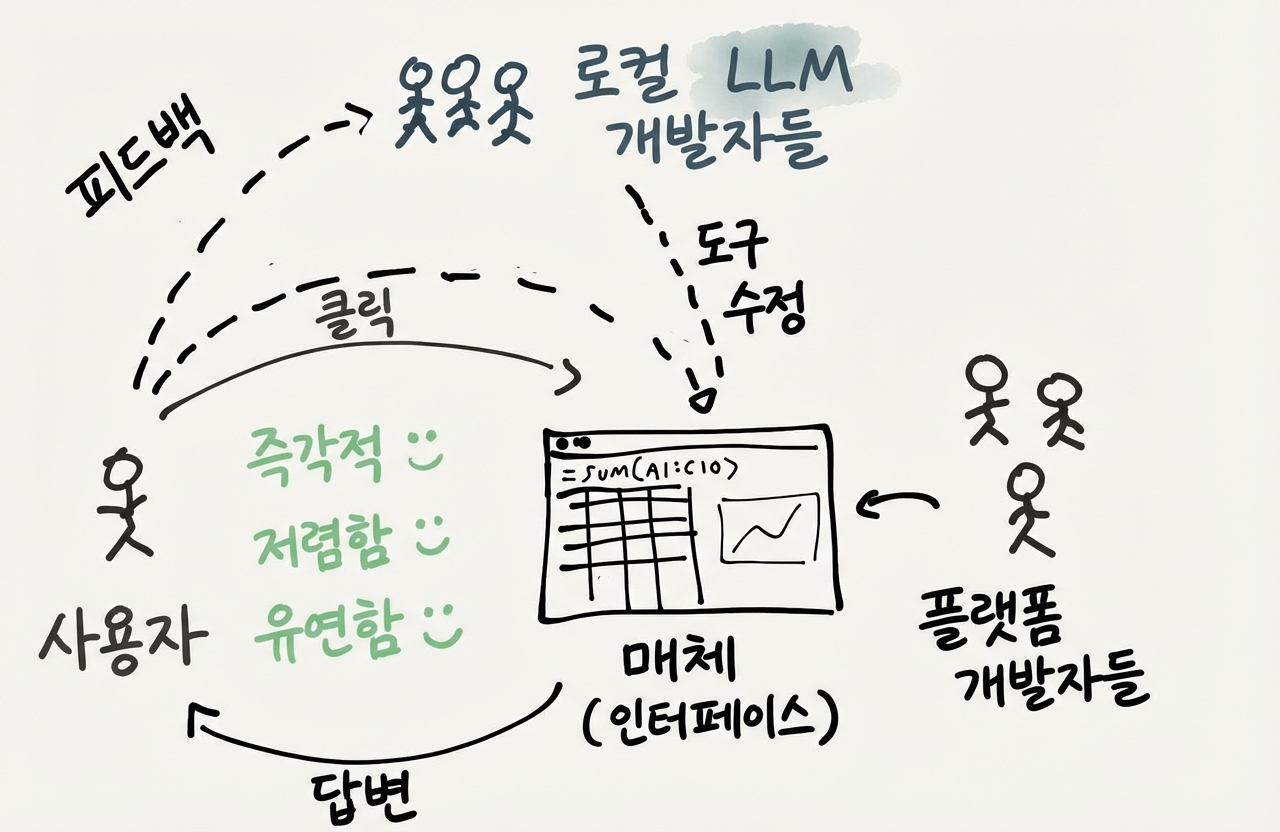
들어가기 전에 한 가지: 추측과 불확실성이 많을 거예요. 이 변화가 얼마나 빨리 일어날지는 저도 전혀 몰라요. 이 글의 목적은 현재 AI에서 합리적으로 예상할 수 있는 것들이 컴퓨터와의 새로운 상호작용을 어떻게 가능하게 할지 상상하고, 이 기술로 엔드유저의 역량을 최대한 키우려면 어떻게 해야 할지 생각해보는 거예요.
프로그래밍 병목 열기
LLM이 왜 사용자들에게 컴퓨팅의 힘을 부여하는 데 중요할까요?
수십 년 동안 컴퓨팅의 선구자들은 엔드유저 프로그래밍이라는 비전을 품어왔어요. 일반인들이 프로그래머들이 만들어 놓은 앱만 쓰는 게 아니라, 컴퓨터의 진짜 힘을 직접 활용하는 것 말이에요. Alan Kay가 1984년에 썼듯이: “우리는 이제 이전에 문서를 편집했던 것처럼 우리의 도구를 편집하고 싶어요.”
이 아이디어에는 많은 표현이 있어요. 여러분이 사용해 봤을 수 있는 엔드유저 프로그래밍 시스템의 현대적 예시로는 스프레드시트, Airtable, Glide, 또는 iOS Shortcuts가 있어요. 오래된 예시로는 HyperCard3, Smalltalk4, Yahoo Pipes5가 있고요. (역사적 심층 분석은 Ink & Switch6의 제 동료들이 쓴 훌륭한 개요를 참조하세요)
이런 시도들 중 일부는 꽤 성공했지만, 근본적인 한계가 있었어요: 대략적인 아이디어를 실행 가능한 코드로 바꾸는 걸 도와주기가 정말 어려웠거든요. 시스템 설계자들은 온갖 방법을 시도했어요 - 아주 고수준의 언어, 친절한 비주얼 에디터, 더 나은 문법, 단계별 복잡도, 예시에서 코드를 자동 생성하기 등. 하지만 어느 정도 복잡해지면 이런 기법들로도 벽에 부딪혔어요.
제 작업에서 프로그래밍 병목의 예시를 보여드릴게요. 몇 년 전, 저는 Wildcard7라는 엔드유저 프로그래밍 시스템을 만들었어요. 스프레드시트 인터페이스로 어떤 웹사이트든 커스터마이징할 수 있게 해주는 거였죠. 아래 짧은 데모를 보시면, 사용자가 Hacker News 기사들을 다른 순서로 정렬하고, 각 기사에 읽기 시간을 추가하는 게 보여요 - 웹페이지와 연동된 스프레드시트를 조작하는 것만으로요.
멋진 데모죠?
하지만 자세히 보면, 이 시스템에는 두 가지 프로그래밍 병목이 있어요. 첫째, 사용자가 계산을 위해 스프레드시트 수식을 직접 작성해야 해요. 본격적인 프로그래밍 언어보다는 훨씬 쉽지만, 그래도 처음 쓰려면 진입 장벽이 있죠. 둘째, 이면에서 Wildcard는 스프레드시트를 웹사이트에 연결하기 위해 사이트별 스크래핑 코드(아래 발췌)가 필요해요. 이론적으로는 개발자들이 이런 어댑터를 만들어서 공유할 수 있지만, 그것도 만만찮은 작업이에요.

이제 LLM이 있으니, 이런 프로그래밍 병목은 더 이상 문제가 아니에요. 자연어로 설명한 걸 웹 스크래핑 코드나 스프레드시트 수식으로 바꾸는 건, 지금 LLM이 이미 잘하는 일이거든요. LLM이 스크래핑 코드와 수식 생성을 도와주면, 아무도 직접 코드를 안 짜도 위 데모를 구현할 수 있어요. 제가 Wildcard를 만들 때만 해도 이런 프로그램 합성은 꿈 같은 얘기였는데, 지금은 빠르게 현실이 되고 있어요.
하지만 이 예시는 더 깊은 질문을 던져요. LLM이 웹사이트를 알아서 수정해준다면, Wildcard UI가 왜 필요하죠? 그냥 ChatGPT한테 “웹사이트 다시 정렬하고 읽기 시간 추가해줘”라고 하면 되지 않나요?
저는 답이 그렇게 단순하지 않다고 봐요. 스프레드시트로 웹사이트의 데이터를 보는 데는 큰 가치가 있어요. 직접 보고 조작할 수 있으니까요. 테이블에서 클릭하고 열 헤더로 정렬하는 게 “X 열로 정렬해줘”라고 타이핑하는 것보다 훨씬 빠르고 직관적이에요. 스프레드시트 수식을 직접 보고 편집할 수 있으면 사용자가 더 많은 통제권을 갖게 되고요.
여기서 핵심은 사용자 인터페이스가 여전히 중요하다는 거예요. 수십 년간 쌓인 상호작용 디자인을 버리지 않으면서도, LLM이 소프트웨어 커스터마이징과 구축을 도와 사용자 역량을 키우는 역할을 할 수 있어요.
다음으로 사용자 인터페이스 대 챗봇에 대한 이 질문을 더 깊이 파고들 거예요. 하지만 먼저 잠깐 옆길로 새서 물어볼게요: GPT가 정말 코딩을 할 수 있을까요?
진짜 코딩이 가능할까요?
오늘날 GPT-4의 코딩 능력은 얼마나 좋을까요? 일반적인 용어로 요약하기 어려워요. 현재 능력을 이해하는 가장 좋은 방법은 많은 긍정적, 부정적 예시를 보면서 어떤 퍼지한 직관을 개발하고, 이상적으로는 직접 시도해 보는 거예요.
인상적인 사례는 얼마든지 있어요. 저도 GPT-4로 데이터 처리용 일회성 Python 코드를 성공적으로 짰고, 아내가 ChatGPT로 웹사이트에서 데이터를 스크래핑하는 Python 코드를 작성하는 걸 봤어요. Microsoft Research의 최근 논문에 따르면 GPT-4는 아무런 예시 없이(제로샷 프롬프트) 브라우저에서 돌아가는 정교한 3D 게임을 만들어냈어요(아래 그림).

실패 사례도 마찬가지로 쉽게 찾을 수 있어요. 제 경험상, GPT-4는 비교적 간단한 알고리즘 문제에서도 헤매곤 해요. 며칠 전 간단한 비디오 편집용 React 앱을 만들어보려 했는데, 90%까지는 갔지만 드래그/리사이즈 같은 인터랙션 몇 개를 끝내 제대로 못 만들었어요. 아직 완벽과는 거리가 멀죠. 전반적으로 GPT-4는 타이핑이 엄청 빠르고 라이브러리도 많이 아는데, 덜렁대고 쉽게 헷갈리는 주니어 개발자 같은 느낌이에요.
여러분의 관점에 따라, 이 요약이 기적적으로 보일 수도 있고 실망스럽게 보일 수도 있어요. 회의적이시라면, 저에게는 즉시 명확하지 않았던 낙관의 이유 몇 가지를 말씀드리고 싶어요.
첫째, LLM과 일할 때 반복 작업은 당연한 거예요. 코드가 처음에 안 돌아가면 에러 메시지를 붙여넣거나 뭐가 잘못됐는지 설명하면 GPT가 고쳐줘요. 예를 들어, 코드를 못 짜는 디자이너가 여러 번 반복해서 비디오 게임을 만드는 이 Twitter 스레드를 보세요. GPT-4 개발자 라이브스트림에서도 에러 메시지로 반복하는 예시들이 나왔어요. 생각해보면 사람도 코드 짤 때 똑같아요 - 처음부터 되는 법이 없잖아요.
AI에 회의적인 프로그래머들 사이에서 자주 나오는 농담이 있어요: “좋아, 이제 코드 안 짜도 되겠네, 그냥 컴퓨터가 뭘 해야 하는지 정확하고 정밀하게 명세만 쓰면 되니까…” (암시: 잠깐, 그게 코드잖아!) 저는 이 관점이 나중에 근시안적이었다고 평가받을 거라고 봐요. LLM은 사용자와 대화하면서 명세를 구체화하고, 상식을 활용해서 빠진 부분을 알아서 채울 수 있어요. 물론 쉬운 문제는 아니지만, 이 방향으로 발전이 있을 거예요. 실제로 저도 GPT-4한테 제 명세에 대해 확인 질문을 하도록 시켜서 효과를 본 적이 있어요.
또 다른 중요한 점: GPT-4는 GPT-3보다 코딩이 훨씬 나아요 - MSR 논문과 제 경험 모두 그래요. 발전 속도가 가파르거든요. 아직 정체기가 아니라면, 다음 세대 모델은 또 크게 좋아질 가능성이 높아요.
코딩 난이도는 맥락에 따라 다르고, 전문 소프트웨어 엔지니어링과 엔드유저 프로그래밍 사이에 차이가 있을 거예요. 한편으로는, 엔드유저 프로그래밍이 전문 코딩보다 쉬울 수 있어요. 많은 작업이 라이브러리들을 이어 붙이는 간단한 코딩으로 해결되고, 새로운 알고리즘을 발명할 필요가 없으니까요.
반면에, 초보 엔드유저가 과정을 이끌 때는 실패의 결과가 더 심각해요. 숙련된 프로그래머는 LLM의 엉뚱한 제안을 웃어넘기고, 직접 코드를 짜거나, 자기 실력으로 LLM과 함께 디버깅할 수 있어요. 하지만 엔드유저는 혼란스러워하거나 애초에 문제가 있는지도 모를 수 있어요. 이건 진짜 문제지만, 해결 불가능하다고 보진 않아요. 엔드유저들은 이미 지저분하고 버그 많은 스프레드시트를 만들면서도 어떻게든 해내고 있잖아요 - 정확성을 중시하는 전문 개발자 눈에는 거슬리거나 심지어 문제라고 느낄 수 있겠지만요.
챗은 본질적으로 제한된 상호작용이에요
자, 이런 준비 작업은 됐으니, 이 글의 본론으로 넘어갈게요: 이 새로운 컴퓨팅 시대에 상호작용 방식은 어떻게 바뀔까요? 먼저 상호작용 방식으로서 챗을 평가해볼게요. 컴퓨팅의 미래는 그냥 자연어로 컴퓨터와 대화하는 걸까요?
이 질문을 명확히 생각하려면, 챗봇이 답답한 이유가 두 가지라는 걸 알아야 해요. 첫째, 챗봇이 할 줄 아는 게 별로 없어서 (Siri 생각해보세요) 원하는 걸 못 해줄 때 짜증나요. 하지만 더 근본적으로, 챗은 봇이 아무리 뛰어나도 본질적으로 제한된 상호작용 방식이에요.
왜 그런지 구체적인 예시로 보여드릴게요. 이번 주 ChatGPT 플러그인 출시 때 OpenAI의 Greg Brockman이 올린 트윗이에요. 자연어로 ChatGPT에게 비디오의 처음 5초를 잘라달라고 해요:
한편으로, 컴퓨터가 어떻게 돌아가는지 아는 사람한테는 정말 인상적인 데모예요. 여기서 열리는 가능성들이 기대되죠.
그런데… 다른 한편으로, 이건 좀 바보 같은 데모이기도 해요. 우리한테는 이미 비디오를 자르는 직접 조작 UI가 있거든요. iPhone의 비디오 자르기 UI를 생각해보세요. 정확히 어디서 자를지 바로 보면서 세밀하게 조절할 수 있어요. 챗으로 “사실 4.8초만 잘라줘”라고 왔다 갔다 하는 것보다 훨씬 낫죠!

물론 Greg의 데모 포인트가 비디오 자르기 자체가 아니라 넓은 가능성을 보여주려는 거였다는 건 알아요. 하지만 여기서 주목할 게 있어요: 챗 인터페이스는 느리고 부정확할 뿐 아니라, 내가 뭘 원하는지 의식적으로 생각해서 말로 표현해야 해요.
좋은 도구 - 망치, 붓, 스키, 자동차 핸들 - 를 쓸 때, 우리는 도구와 무의식적으로 하나가 돼요. 플로우 상태에 빠지고, 몸이 기억하는 대로 움직이고, 세밀하게 제어하고, 때로는 창의적이거나 예술적인 결과물을 만들기도 하죠. 챗은 봇이 아무리 뛰어나도 자동차 운전 같은 느낌을 줄 수 없어요. 1986년 책 Understanding Computers and Cognition9에서 Terry Winograd와 Fernando Flores10가 이 점을 이렇게 설명해요:
자동차를 운전할 때, 조작은 보통 투명해요. “저 커브 돌려면 핸들을 얼마나 돌려야 하지?”라고 생각하지 않아요. 사실 (뭔가 방해하지 않는 한) 핸들을 쓰고 있다는 것조차 의식하지 못해요… 자동차 디자인의 오랜 진화가 이런 ‘손에 딱 맞는 느낌(readiness-to-hand)‘11을 만들어냈어요. 이건 자동차가 사람처럼 대화해서 얻어지는 게 아니라, 운전자의 의도와 도로 위 움직임 사이를 자연스럽게 연결해서 얻어지는 거예요.
컨설턴트 vs 앱
챗 대 직접 조작 질문을 좀 더 넓게 봐볼게요. 한 가지 방법은 Slack으로 인간 컨설턴트 팀과 일하는 것과, 그냥 앱을 써서 직접 일을 처리하는 것을 비교해보는 거예요. 그런 다음 LLM이 여기에 어떻게 들어맞는지 볼 거예요.
다음 분기 매출 예측 같은 비즈니스 지표가 필요하다고 상상해보세요. 어떻게 하시겠어요?
한 가지 방법은 숙련된 비즈니스 분석가 팀에게 물어보는 거예요. 질문을 메시지로 보내면 되죠. 분석가들이 바쁘니까 답을 받는 데 몇 시간 걸리고, 사람 시간에 돈을 내니까 비싸요. 간단한 작업에는 과잉 같지만, 핵심 장점은 유연성이에요 - 컨설턴트들이 다양한 지식과 능력을 갖추고 있어서 여러 종류의 요청을 처리할 수 있으니까요.
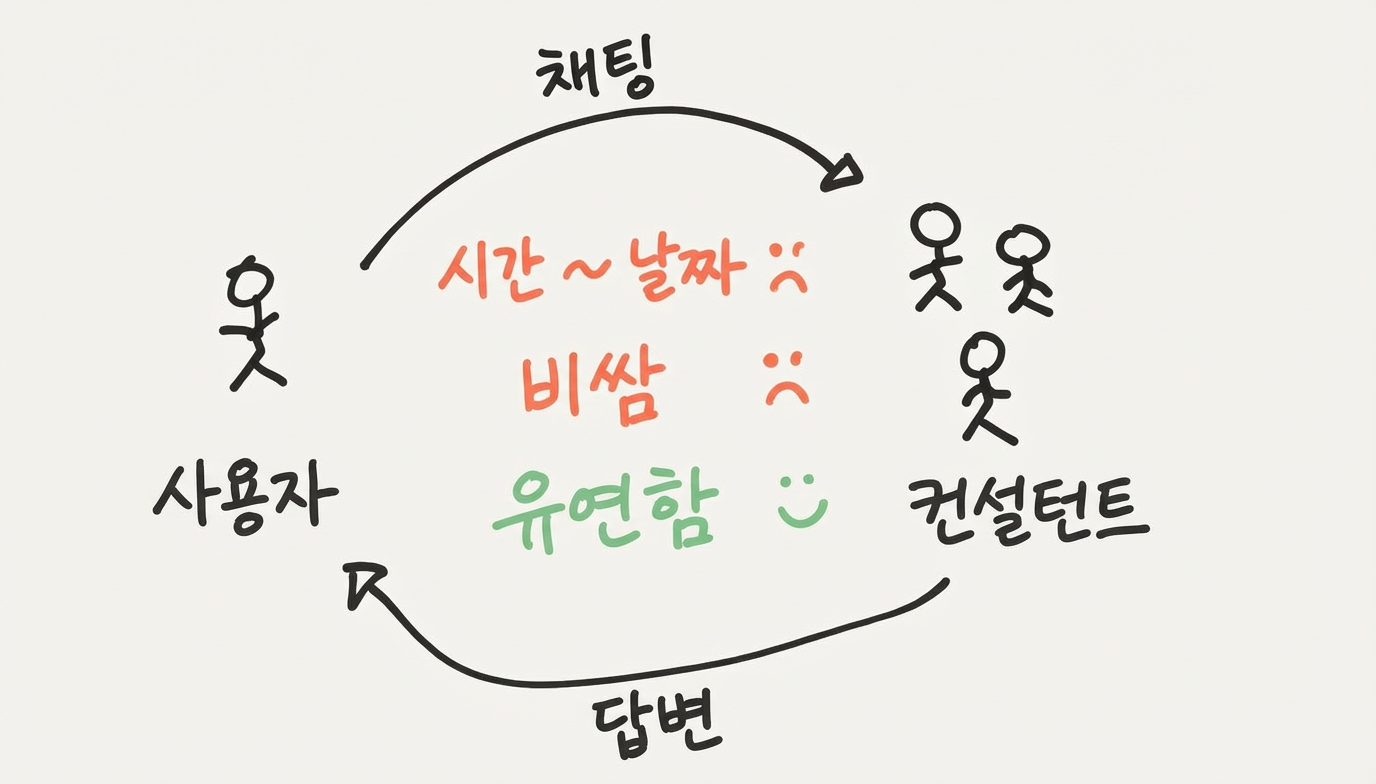
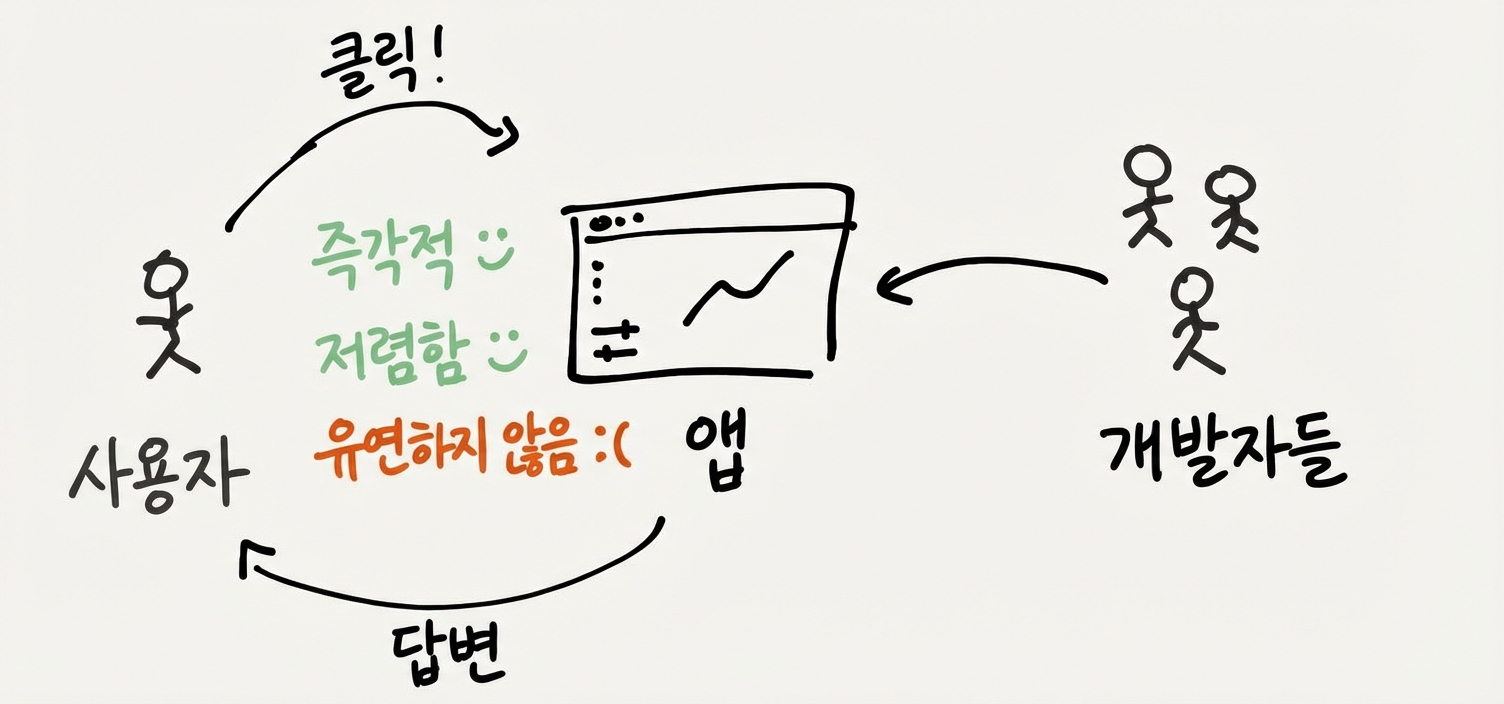
반대로, 대시보드에서 직접 클릭하며 둘러볼 수 있는 셀프서비스 분석 플랫폼을 쓸 수도 있어요. 이게 되면, 분석가한테 물어보는 것보다 훨씬 빠르고 저렴해요. 대시보드에서 정렬, 필터링, 확대 같은 직접 조작을 할 수 있거든요. 문제를 빠르게 직접 파악할 수 있어요.
그럼 단점은 뭘까요? 앱을 쓰는 건 맞춤형 컨설턴트와 일하는 것보다 덜 유연해요. 이 분석 플랫폼이 지원 안 하는 작업을 하고 싶은 순간, 다른 사람한테 도움을 구하거나 다른 도구로 갈아타야 해요. 플랫폼 개발자들한테 이메일을 보내볼 수 있지만, 보통 답장도 안 와요. 개발자들과 실질적인 피드백 루프가 없는 거죠. 소프트웨어가 더 유연했으면 하고 바라게 되는 순간이에요.
이제 그 기준선 비교가 확립됐으니, LLM이 어떻게 들어맞을지 상상해볼게요.
이제 같은 수준의 유연성을 유지하면서 인간 분석가 팀을 ChatGPT로 대체할 수 있다고 가정해볼게요. (지금 모델로는 안 되지만, 점점 그렇게 될 거예요.) 그러면 뭐가 달라질까요? 일단 LLM은 사람보다 비용이 훨씬 싸요. 커피 브레이크도 안 가니까 응답도 훨씬 빨라요. 이건 큰 장점이에요. 하지만 여전히, 대화를 주고받는 데 의식적으로 생각하는 시간이 초 단위, 분 단위로 걸려요 - GUI나 핸들로 조작하는 것보다 훨씬 느리죠.
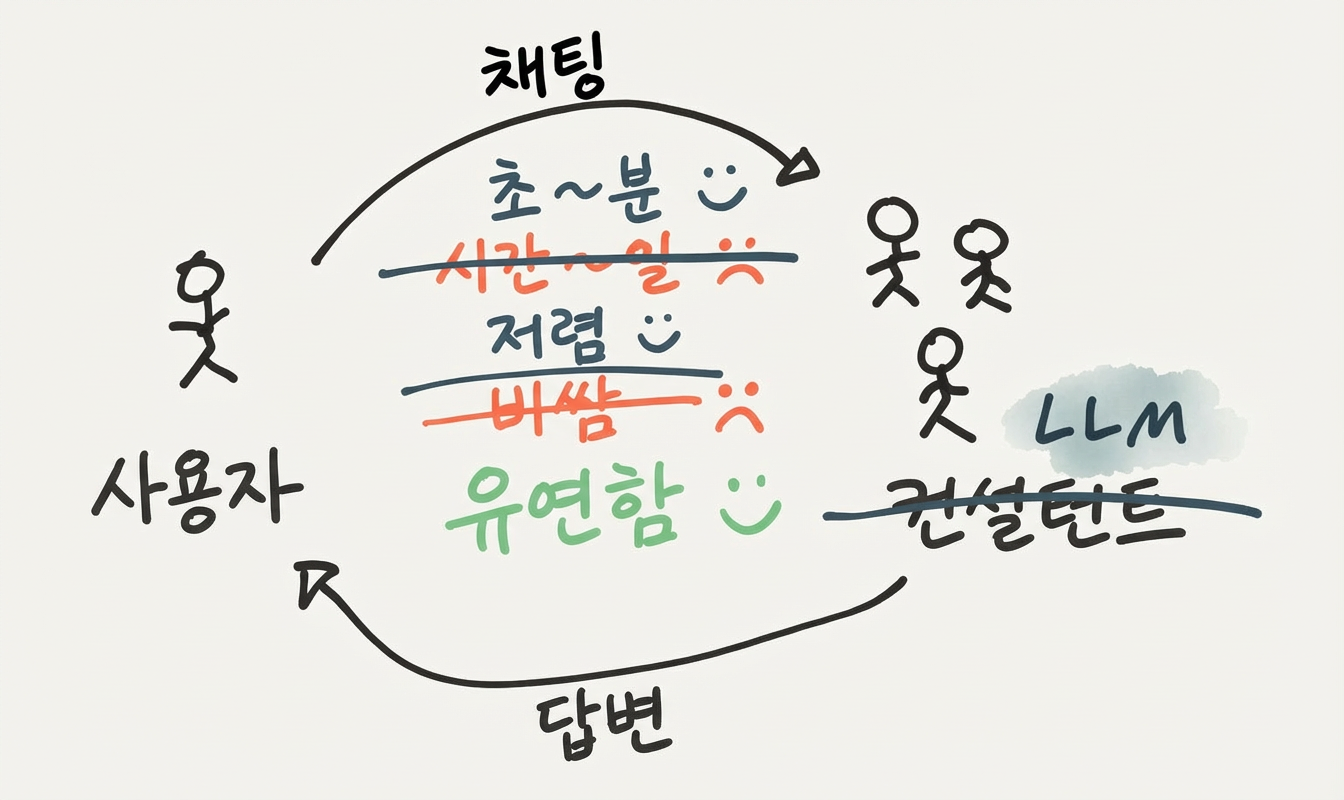
다음으로, 앱 모델에 LLM을 적용해볼게요. 인터랙티브 분석 앱으로 시작하되, 이번에는 LLM 개발자 팀이 대기하고 있다면 어떨까요? 우선 LLM한테 앱 사용법을 물어볼 수 있어요 - 문서 읽는 것보다 쉬울 수 있죠.
하지만 더 중요한 건, LLM 개발자들이 앱을 직접 업데이트해줄 수 있다는 거예요. 새 기능이 필요하다고 피드백을 주면, 요청이 무한 대기열에 묻히지 않아요. LLM이 즉시 응답하고, 기능 구현을 위해 대화를 주고받을 거예요. 새 기능을 모두한테 배포할 필요도 없어요 - 우리 팀에만 켜면 되니까요. 중앙의 인간 개발자 팀에 의존하지 않으니까 이게 이제 경제적으로 가능해져요.
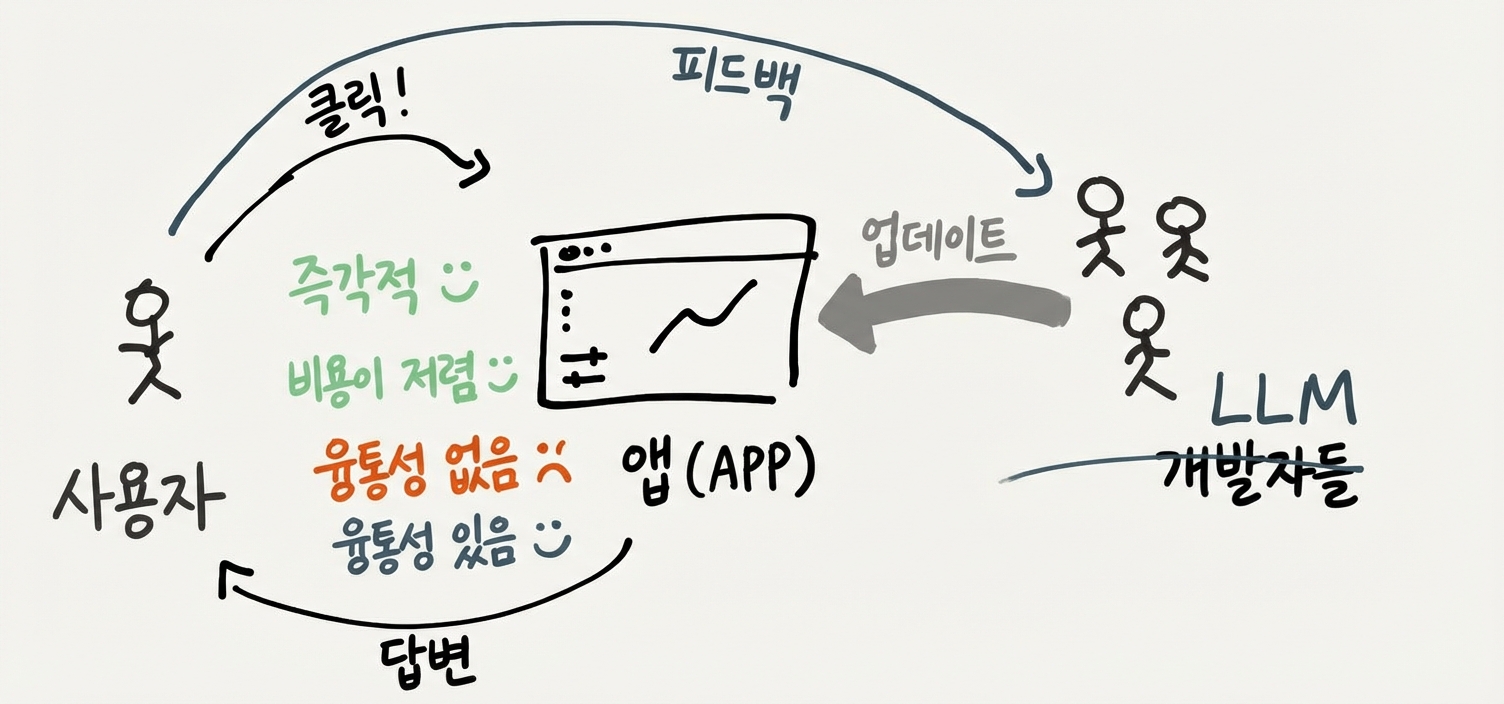
물론 아직은 대략적인 비전일 뿐이에요. 이 모델을 어떻게 실현할지 세부 사항은 많이 빠져 있어요. 현재 소프트웨어가 만들어지는 방식 때문에 이런 즉석 커스터마이징이 꽤 어렵거든요.
하지만 중요한 건, 이제 상호작용에 두 개의 루프가 생겼다는 거예요. 내부 루프에서는 빠른 직접 조작 인터페이스를 써서 도구와 하나가 될 수 있어요. 외부 루프에서는 기존 앱의 한계에 부딪히면 LLM 개발자들한테 피드백을 주고 새 기능을 만들 수 있어요. UI의 장점은 유지하면서 유연성을 더하는 거죠.
앱에서 컴퓨테이셔널 미디어로
이 이중 상호작용 루프가 뭔가 떠오르시나요?
스프레드시트가 어떻게 작동하는지 생각해보세요. 스프레드시트에 재무 모델이 있다면, 셀 숫자를 바꿔서 시나리오를 평가할 수 있어요 - 직접 조작의 내부 루프가 작동하는 거죠.
하지만 수식도 편집할 수 있어요! 스프레드시트는 특정 작업에만 쓰는 “앱”이 아니에요. 다양한 작업을 유연하게 표현할 수 있는 범용 컴퓨테이셔널 미디어에 가까워요. 스프레드시트를 만든 “플랫폼 개발자들”이 여러 도구를 만드는 데 쓸 수 있는 범용 구성 요소를 제공한 거예요.
스프레드시트 상호작용의 이중 루프를 이렇게 그릴 수 있어요. 스프레드시트에서 숫자를 편집할 수 있지만, 수식도 편집할 수 있고, 그건 도구를 편집하는 거예요:
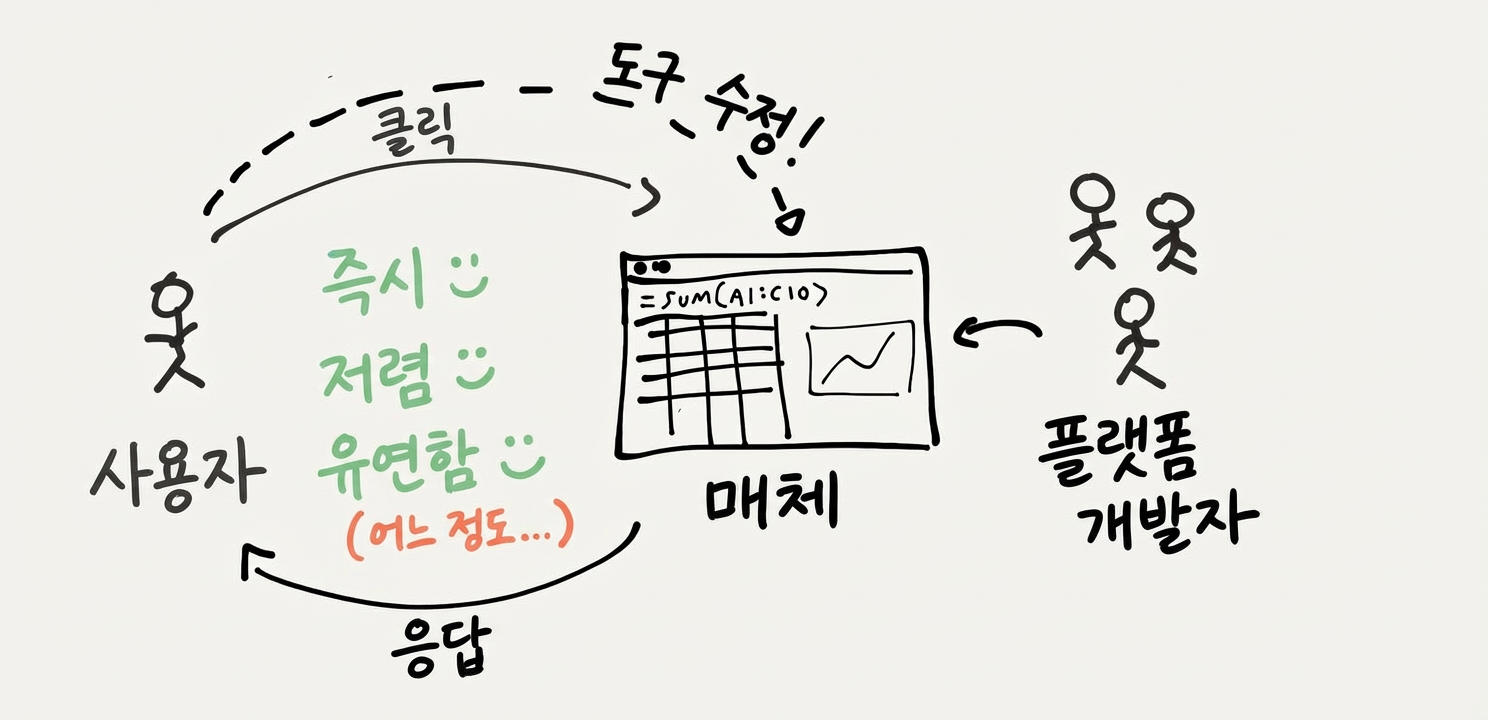
지금까지 위 다이어그램에서 스프레드시트를 “약간” 유연하다고 표시했어요. 왜냐고요? 혼자 스프레드시트를 쓰다 보면 내 지식의 한계에 금방 부딪히거든요. 실제로 스프레드시트는 이것보다 훨씬 유연해요. 이 다이어그램이 스프레드시트 사용의 핵심 요소를 놓치고 있기 때문이에요: 바로 협업.
로컬 개발자들과의 협업
대부분의 팀에는 도메인 전문가와 기술 전문가가 섞여 있고, 함께 스프레드시트를 만들어요. 중요한 건, 스프레드시트를 함께 만드는 사람들은 일반적인 “개발자”와 “엔드유저” 관계와는 매우 다르다는 거예요. Bonnie Nardi와 James Miller가 협업 스프레드시트 개발에 대한 1990년 논문에서 이렇게 설명해요. 재무를 아는 CFO Betty와 스프레드시트 프로그래밍 전문가 Buzz를 예로 들면서요:
Betty와 Buzz는 전형적인 엔드유저/개발자 쌍처럼 보여요. 그래서 그들의 스프레드시트 개발도 전형적일 거라고 상상하기 쉬워요: Betty가 도메인 지식으로 스프레드시트가 뭘 해야 하는지 정의하고, Buzz가 구현하는 거죠.
하지만 그렇지 않아요. 그들의 협업은 두 가지 중요한 점에서 달라요:
(1) Betty가 Buzz 도움 없이 기본 스프레드시트를 직접 만들어요. 파라미터, 데이터 값, 수식을 자기 모델에 직접 프로그래밍해요. UI 디자인과 구현도 Betty가 전적으로 맡아요. 색상, 음영, 폰트, 테두리, 빈 셀을 활용해서 정보를 구조화하고 강조하죠.
(2) Buzz가 그래프나 복잡한 수식 같은 어려운 부분을 도와줄 때, 그의 작업은 Betty의 기존 작업 위에 덧붙여져요. Buzz는 Betty의 기본 스프레드시트에 작고 고급인 코드 조각을 추가해요. Betty가 메인 개발자이고 Buzz는 컨설턴트로서 보조 역할을 하는 거죠.
이건 시스템 설계와 구현 책임의 중요한 전환이에요. 비프로그래머가 스프레드시트 개발 대부분을 책임지고, 기존 프로그래밍으로는 시도하지 않았을 대규모 애플리케이션을 만들어요. 재귀 함수나 중첩 루프를 영영 안 배울 수 있지만, 스프레드시트로는 엄청나게 생산적일 수 있어요. 초보 스프레드시트 사용자들이 자기 스프레드시트에 빠져들면서, 고급 기법이 필요할 때 경험 많은 사용자한테 도움을 구하게 돼요.
그래서 스프레드시트 사용에 대한 더 정확한 다이어그램에는 Buzz 같은 “로컬 개발자”가 포함돼요. 사용자가 도구를 만들 때 도움받을 수 있는 또 다른 외부 루프죠. 같은 팀에 있으니까, 외부 앱이나 플랫폼 개발자한테 요청하는 것보다 도움받기가 훨씬 쉬워요. 그리고 가장 중요한 건, 시간이 지나면서 사용자가 개발 과정에 참여하기 때문에 스프레드시트 기능을 점점 더 많이 스스로 배우게 된다는 거예요.
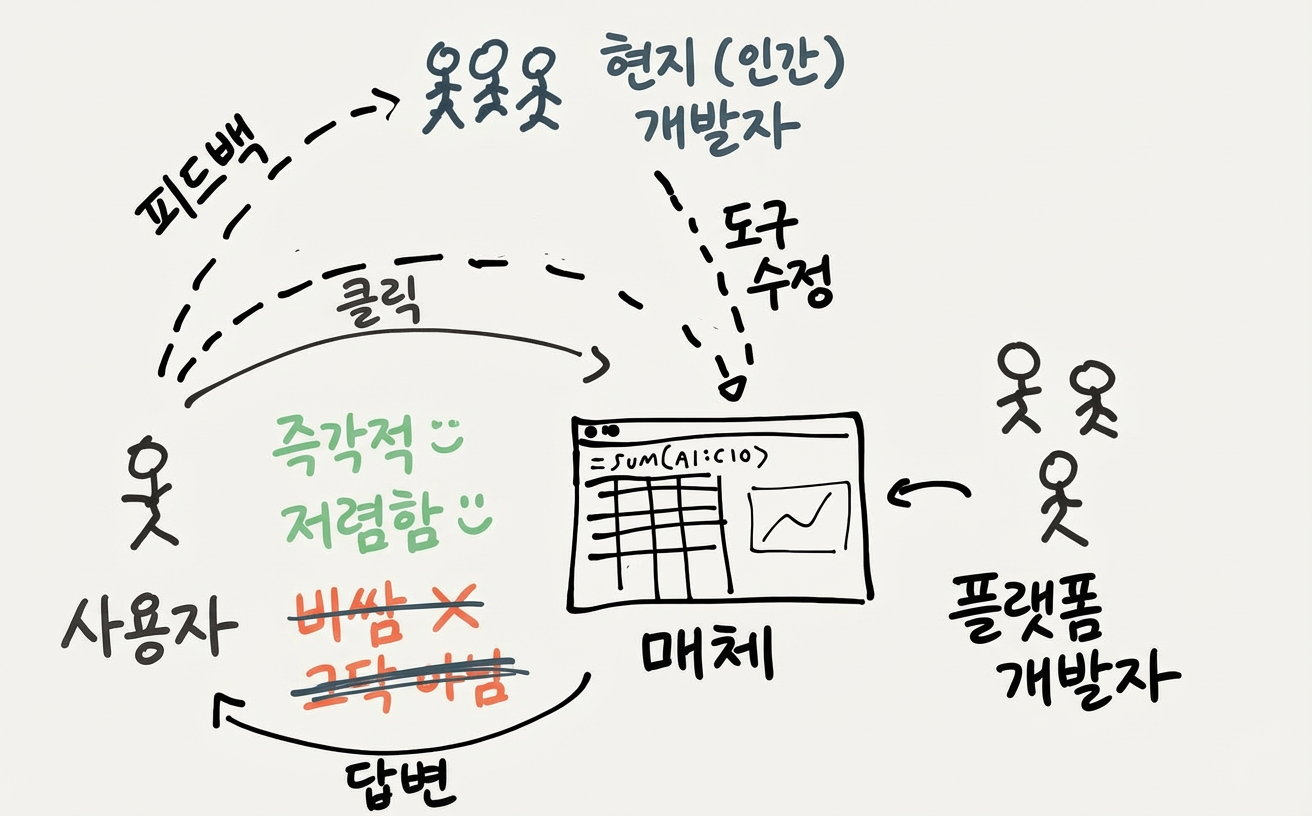
일반적으로 로컬 개발자는 스프레드시트를 더 유연하게 만들어주지만, 인간 기술 전문가가 필요하니까 비용도 생겨요. 로컬 스프레드시트 전문가가 가까이 없다면 - 아마 그런 사람을 고용할 여유가 없어서? - 복잡한 스프레드시트 프로그래밍은 구글링에 의존하게 돼요…
그런 경우, LLM이 로컬 개발자 역할을 한다면 어떨까요? 사용자가 스프레드시트 생성을 주도하면서, 필요할 때만 수식에 대한 기술적 도움을 받는 거예요. LLM이 완성된 솔루션만 던져주는 게 아니라, 사용자가 다음에는 직접 만들 수 있도록 가르쳐주는 거예요.
이 그림이 보여주는 세계가 꽤 매력적이에요. 직접 조작의 힘을 온전히 활용하는 내부 루프가 있어요. 열린 미디어 안에서 사용자가 도구를 더 깊이 편집할 수 있는 외부 루프도 있어요. 도구 편집에 AI 도움을 받으면서, 미디어에서 일하는 자기 능력도 키울 수 있어요. 시간이 지나면서 수식 기초나 VLOOKUP 작동 원리 같은 걸 배우게 돼요. 이런 구조적 지식은 도구로 뭘 할 수 있을지 떠올리는 데 도움이 되고, LLM이 만든 결과물을 검토하는 데도 도움이 돼요.
ChatGPT 세계에서는 사용자가 AI 내부 작동 원리를 모른 채 AI에 완전히 의존하게 돼요. 반면 AI가 어시스턴트로 붙은 컴퓨테이셔널 미디어에서는, 사용자가 미디어에 익숙해지면서 AI 의존도가 시간이 지남에 따라 자연스럽게 줄어들어요.
이 다이어그램이 마음에 드신다면, 흥미로운 기회가 보일 거예요. 지금까지 열린 컴퓨테이셔널 미디어 디자인은 프로그래밍 병목 문제에 막혀 있었어요. LLM은 자연어를 코드로 바꾸는 더 유연한 방법을 제공하는 것 같고, 그래서 이런 질문이 떠올라요: 이 새로운 상황에 잘 맞는 강력한 컴퓨테이셔널 미디어는 어떤 모습일까요?
즉석 UI 데모들
업데이트 3/31: 이 에세이를 처음 게시한 후 며칠 동안, 이 공간의 아이디어를 탐구하는 사람들의 멋진 데모 몇 가지를 Twitter에서 찾았어요; 여기에 추가했어요.좋아요, 다이어그램은 그만하고, 즉석 UI 생성이 실제로 쓸 때 어떤 느낌일까요?
여기 Sean Grove가 인터랙티브 테이블 뷰, 위도/경도를 보여주는 지도 뷰, 간단한 비디오 편집 UI를 즉석에서 생성하는 걸 시연해요:
그리고 여기 Vasek Mlejnsky가 서버 요청을 제출하는 폼을 만들 수 있는 IDE를 보여주는 게 있어요:
마지막으로, 제가 만든 목업 비디오예요. GPT가 질문에 인터랙티브 스프레드시트로 답해요. 숫자를 조정하면 즉각적인 피드백을 받을 수 있어요. 기저 수식을 확인하고 모델한테 설명해달라고 해서 스프레드시트 지식을 늘릴 수도 있어요. (GPT가 실제로 이 스프레드시트 데이터를 생성했고, 저는 원본 데이터를 Excel에 복사해서 인터랙티브 요소를 보여준 거예요.)
이 데모들이 즉석 UI의 가능성을 잘 보여주지만, 아직 갈 길이 멀어요. 특히 어려운 점: 괜찮은 UI는 보통 한 번에 완성되지 않아요. 사용자와 반복적으로 다듬어야 해요. 제 경험상 이 반복 과정이 아직은 꽤 거칠어요.
다음 시간: 확장 가능한 소프트웨어
지금은 여기까지예요. 아직 다루지 못한 질문이 많이 남아 있어요.
다음에는 LLM을 쓰는 사람들이 GUI 앱을 확장 가능하고 조합 가능하게 만드는 데 필요한 아키텍처적 기반에 대해 다룰 계획이에요.
관심이 있으시면, 이메일 뉴스레터에 가입하시거나 RSS를 구독하세요.
• • •
관련 자료
• • •
역자 주
- GitHub Copilot: GitHub과 OpenAI가 공동 개발한 AI 코딩 어시스턴트. 코드 에디터에서 실시간으로 코드를 제안해주며, GPT 모델을 기반으로 작동해요. 2021년 출시 이후 전문 개발자들 사이에서 널리 사용되고 있어요. ↩
- 엔드유저 프로그래밍(End-User Programming): 전문 개발자가 아닌 일반 사용자가 자신의 필요에 맞게 소프트웨어를 만들거나 수정하는 것을 말해요. 스프레드시트 수식 작성, 매크로 녹화, 노코드 도구 사용 등이 대표적인 예시예요. ↩
- HyperCard: 1987년 Apple이 출시한 선구적인 하이퍼미디어 시스템. 프로그래밍을 모르는 사람도 ‘카드’ 형태의 인터랙티브 콘텐츠를 만들 수 있었어요. 웹 브라우저의 개념적 선조로 여겨지며, 많은 초기 멀티미디어 CD-ROM이 이 도구로 제작됐어요. ↩
- Smalltalk: 1970년대 Xerox PARC에서 개발된 객체지향 프로그래밍 언어이자 개발 환경. 현대 GUI, 객체지향 프로그래밍, IDE의 많은 개념을 처음 도입했어요. 특히 코드와 실행 환경이 하나로 통합되어 있어서 실시간으로 프로그램을 수정하고 실험할 수 있었어요. ↩
- Yahoo Pipes: 2007년 Yahoo가 출시한 웹 기반 데이터 매시업 도구. 시각적 프로그래밍 인터페이스로 RSS 피드, 웹 데이터 등을 조합하고 변환할 수 있었어요. 엔드유저 프로그래밍의 대표적 사례였지만, 2015년 서비스가 종료됐어요. ↩
- Ink & Switch: 소프트웨어의 미래를 연구하는 독립 연구소. 로컬 퍼스트 소프트웨어, 엔드유저 프로그래밍, 가변형 소프트웨어 등 사용자 주권을 강화하는 컴퓨팅을 탐구해요. 이 글의 저자 Geoffrey Litt가 소속된 곳이에요. ↩
- Wildcard: 저자 Geoffrey Litt가 박사 과정에서 개발한 연구 프로젝트. 브라우저 확장 프로그램 형태로, 웹사이트의 데이터를 스프레드시트처럼 보고 수정할 수 있게 해줘요. 엔드유저가 코딩 없이 웹사이트를 커스터마이징할 수 있다는 가능성을 보여줬어요. ↩
- ReAct: “Reasoning and Acting”의 약자로, LLM이 추론과 행동을 번갈아 수행하는 프롬프팅 기법이에요. 모델이 생각 과정을 말로 표현하면서 외부 도구(검색, 계산기 등)를 호출하고, 그 결과를 바탕으로 다음 단계를 결정해요. 2022년 논문에서 제안됐어요. ↩
- Understanding Computers and Cognition: Terry Winograd와 Fernando Flores가 1986년 출간한 책. 컴퓨터와 인간 인지에 대한 기존 AI 연구의 한계를 비판하고, 하이데거 철학을 바탕으로 인간-컴퓨터 상호작용의 새로운 관점을 제시했어요. HCI 분야의 고전으로 꼽혀요. ↩
- Terry Winograd & Fernando Flores: Winograd는 스탠퍼드대 컴퓨터과학 교수로, 초기 자연어 처리 시스템 SHRDLU로 유명해요. Google 창업자 Larry Page의 박사 지도교수이기도 해요. Flores는 칠레 출신 철학자이자 정치인으로, 이메일 시스템 개발에도 참여했어요. ↩
- 손에 딱 맞는 느낌(readiness-to-hand): 독일 철학자 Martin Heidegger가 존재와 시간(1927)에서 제시한 개념 ‘Zuhandenheit’의 번역. 도구를 사용할 때 도구 자체를 의식하지 않고 목적에만 집중하는 상태를 말해요. 망치질할 때 망치가 아니라 못을 박는 행위에 집중하는 것처럼요. ↩
저자 소개: Geoffrey Litt는 Ink & Switch에서 연구원으로 일하며, 가변형 소프트웨어와 엔드유저 프로그래밍을 연구하고 있어요.
원문: Malleable software in the age of LLMs - Geoffrey Litt (2023년 3월)
생성: Claude (Anthropic)