재귀 언어 모델(RLM): LLM이 스스로 컨텍스트를 분해하고 처리하는 방법
게시일: 2026년 1월 20일 | 원문 작성일: 2025년 10월 15일 | 저자: Alex L. Zhang, Omar Khattab (MIT CSAIL) | 원문 보기
핵심 요약
LLM의 컨텍스트 창이 아무리 커져도 성능은 떨어져요. RLM은 이 문제를 모델이 직접 해결하게 해요.
- 컨텍스트 부패(Context Rot) 문제 — 컨텍스트가 길어질수록 모델 성능이 저하되는 현상. 창 크기와 별개의 문제예요.
- 재귀적 분해 — RLM은 모델이 Python REPL 환경에서 컨텍스트를 직접 분할하고 재귀적으로 처리해요.
- 114% 성능 향상 — GPT-5-mini 기반 RLM이 GPT-5를 34점 이상 앞섰어요. 비용은 비슷하고요.
- 새로운 추론 패러다임 — CoT, 에이전트 다음의 추론 시간 스케일링 방법론으로 주목받고 있어요.
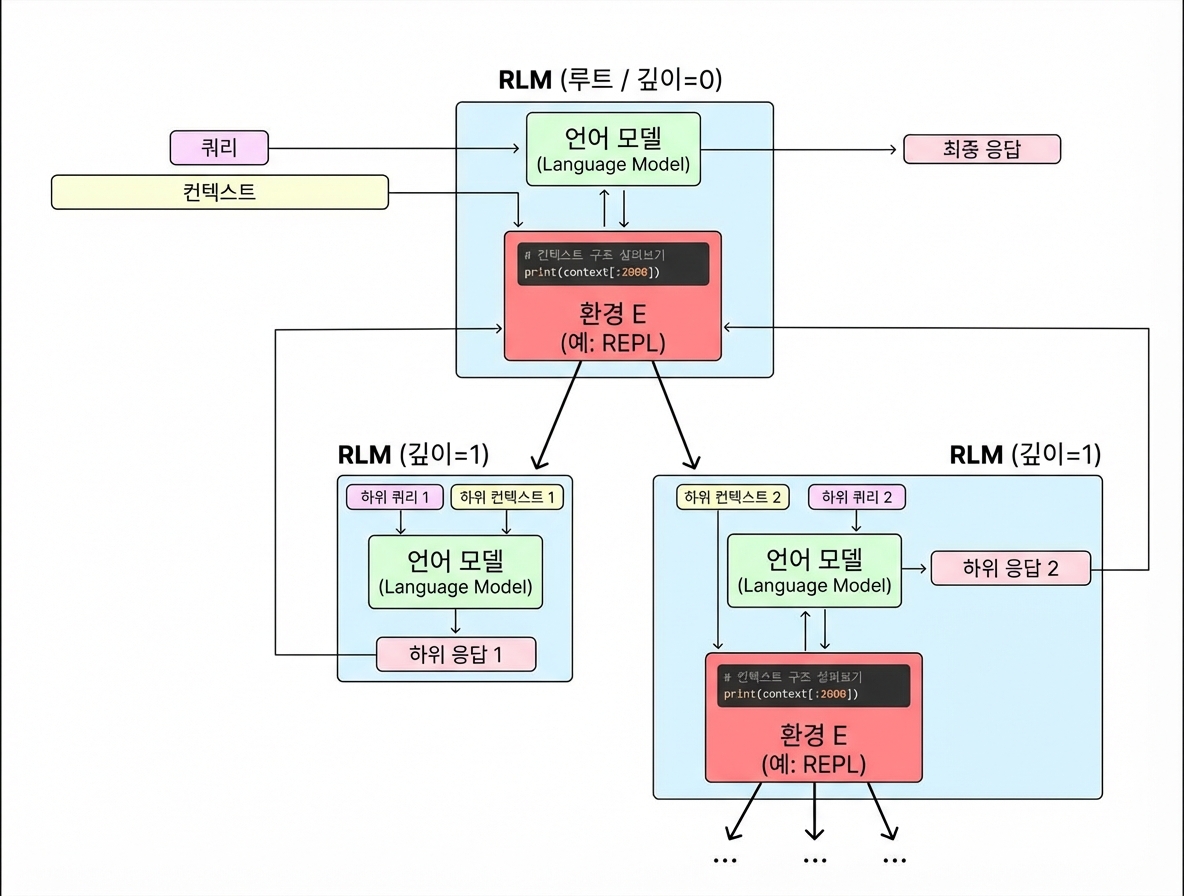
그림 1: RLM 호출은 text → text 매핑으로 작동하지만, 표준 LM 호출보다 유연하고 거의 무한한 컨텍스트 길이로 확장 가능해요.
• • •
서론: 긴 컨텍스트 연구가 왜 답답할까요?
언어 모델에는 컨텍스트 부패(Context Rot)라는 잘 알려졌지만 정확히 정의하기 어려운 현상이 있어요. Anthropic의 정의에 따르면 “컨텍스트 창의 토큰 수가 증가할수록 모델이 해당 컨텍스트에서 정보를 정확히 회상하는 능력이 감소하는” 현상이에요. 하지만 연구 커뮤니티에서는 이 정의가 완전히 맞지 않다는 걸 알아요.
예를 들어 RULER 같은 인기 있는 needle-in-the-haystack 벤치마크를 보면, 대부분의 프론티어 모델이 이미 90% 이상의 성능을 보여요 (1년 전 모델 기준으로도요!).

LM에게 어제 시작한 호박 농담을 마저 해달라고 했더니 “호박? 무슨 호박요?” 라고 하더라고요 — 컨텍스트가 완전히 부패했네요.
그런데 사람들이 알아챈 건 컨텍스트 부패가 Claude Code 히스토리가 비대해지거나, ChatGPT와 오래 대화할 때 나타나는 이상한 현상이라는 거예요. 마치 대화가 길어질수록 모델이… 멍청해지는 것 같은 느낌? 이건 잘 알려져 있지만 벤치마크로 측정하기 어려워서 논문에서 다루지 않는 실패 모드예요.
자연스러운 해결책은 이런 거예요: “만약 컨텍스트를 두 번의 모델 호출로 나누고, 세 번째 호출에서 합치면 이런 성능 저하를 피할 수 있지 않을까?” 바로 이 직관이 재귀 언어 모델의 기초가 돼요.
• • •
재귀 언어 모델(RLM)이란?
RLM의 핵심 아이디어
재귀 언어 모델(RLM)1은 모델이 무한한 길이의 입력 컨텍스트를 분해하고 재귀적으로 상호작용할 수 있게 하는 추론 전략이에요.
기존 방식에서 모델 호출은 단일 함수처럼 작동해요. 입력을 받고, 출력을 내보내고, 끝. 하지만 RLM에서는 모델이 중간 계산을 위해 자기 자신이나 다른 LM에게 하위 호출(sub-call)을 생성할 수 있어요. 동일한 API 인터페이스를 유지하면서요.
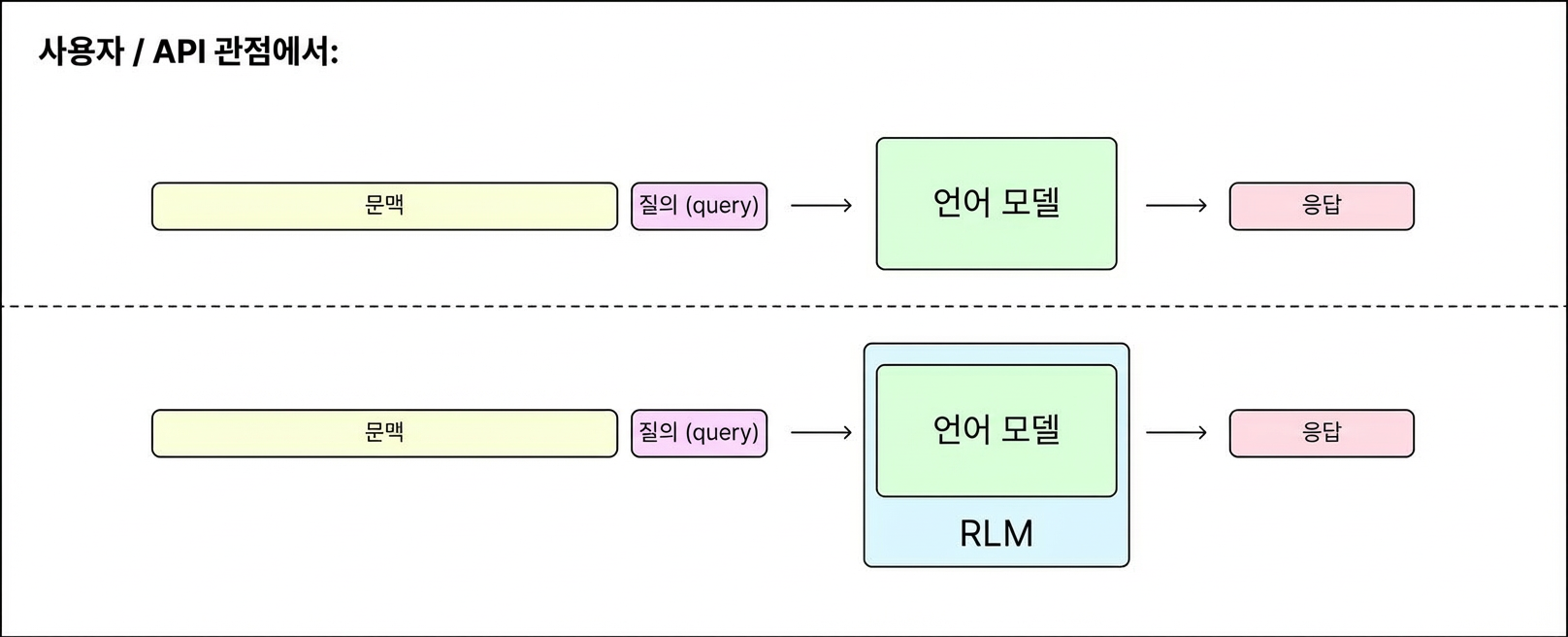
그림 2: RLM 호출은 사용자에게 거의 무한한 컨텍스트의 환상을 제공하고, 내부적으로는 LM이 컨텍스트를 관리하고 분할하며 재귀적으로 자신을 호출해요.
기술 아키텍처
RLM은 세 가지 핵심 구성 요소로 이뤄져요:
- 루트 LM (depth=0) — 전체 컨텍스트가 아닌 쿼리만 받아요
- 환경 — 컨텍스트를 메모리 내 변수로 저장하는 Python REPL2 노트북
- 재귀 기능 — 루트 LM이 REPL 환경 내에서 자식 LM 호출(depth=1)을 생성할 수 있어요
루트 LM은 다음과 같은 방식으로 상호작용해요:
- Python 코드 블록을 작성하고 실행
- 프로그래밍 방식으로 컨텍스트 부분 집합을 확인
- 분할된 컨텍스트에 대해 재귀 하위 쿼리 실행
FINAL(answer)또는FINAL_VAR(variable_name)태그로 답변 반환
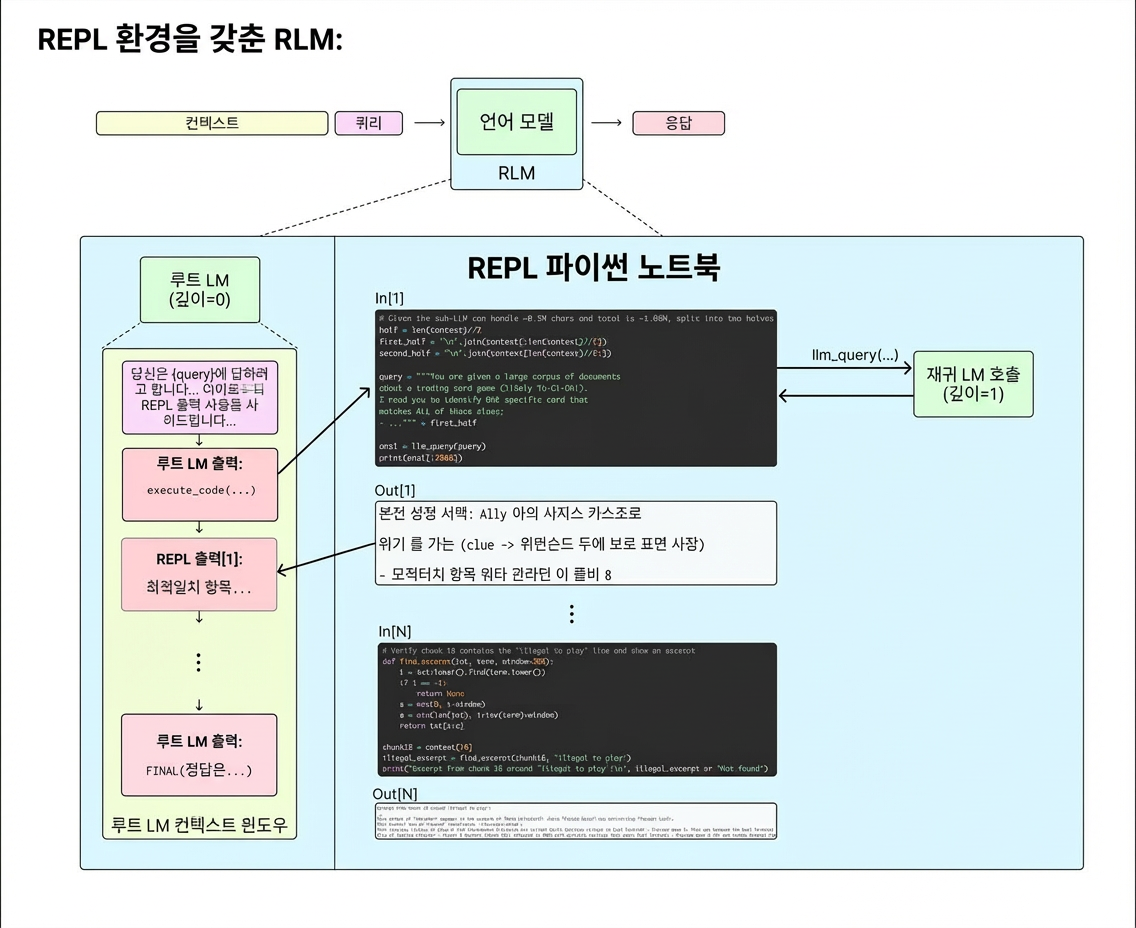
그림 3: RLM 프레임워크의 구현. 루트 LM은 Python 노트북 환경에서 컨텍스트를 분석하고, 변수에 저장된 문자열에 대해 재귀 LM 호출(depth=1)을 실행해요.
형식적 정의 (클릭해서 펼치기)
언어 모델 M이 쿼리 q와 (잠재적으로 긴) 컨텍스트 C = [c₁, c₂, …, cₘ]을 받는 일반적인 설정을 생각해볼게요. 표준 접근법은 M(q, C)를 블랙박스 함수 호출처럼 다루는 거예요 — 쿼리와 컨텍스트를 받아서 문자열 출력을 반환하죠.
이 관점을 유지하면서, 모델 위에 얇은 스캐폴드를 정의해서 동일한 입출력 공간을 가지면서 더 표현력 있고 해석 가능한 함수 호출 RLM_M(q, C)를 제공해요.
형식적으로, 환경 ℰ 위의 재귀 언어 모델 RLM_M(q, C)는 쿼리 q와 (잠재적으로 긴) 컨텍스트 C를 받아서 문자열 출력을 반환해요. 주요 차이점은 모델에게 도구 호출 RLM_M(q̂, Ĉ)를 제공한다는 거예요. 이 호출은 새로운 쿼리 q̂와 변환된 컨텍스트 Ĉ를 사용해서 독립적인 환경 ℰ̂를 가진 격리된 하위 RLM 인스턴스를 생성해요. 결국 이 재귀 호출의 최종 출력이 원래 호출자의 환경으로 다시 전달돼요.
환경 ℰ는 언어 모델 M이 프롬프트되고, 쿼리되고, 처리되어 최종 출력을 제공하는 제어 흐름을 추상적으로 결정해요. 가장 간단한 환경 ℰ₀는 입력 쿼리와 컨텍스트 q, C로 모델 M을 쿼리하고 모델 출력을 최종 답으로 반환하는 것으로, 기본 모델 호출의 일반화예요.
왜 이게 효과적일까요?
핵심은 컨텍스트 창 압력 감소예요. 루트 LM은 전체 컨텍스트를 직접 보지 않으니까 입력 컨텍스트가 급격히 늘어나지 않아요. 게다가 모델이 테스트 시점에 grep, 인덱싱, 파티셔닝을 상황에 맞게 선택할 수 있고요.
또한 메모리에 로드할 수 있는 모든 데이터가 검사와 변환 대상이 돼요. 멀티모달 데이터도 다룰 수 있다는 뜻이에요.
모델이 발견한 전략들
흥미로운 점은 RLM 궤적을 시각화했을 때 모델이 스스로 발견한 패턴들이에요.
| 전략 | 설명 | 사용 사례 |
|---|---|---|
| 피킹(Peeking) | 컨텍스트 초반 섹션을 먼저 살펴봄 | 구조 파악 후 진행 |
| 그레핑(Grepping) | 키워드/정규식으로 검색 범위 좁히기 | 시맨틱 검색 대신 효율적 필터링 |
| 파티션 + 맵 | 컨텍스트를 청킹하고 재귀 호출 | 복잡한 시맨틱 쿼리 처리 |
| 요약 | 컨텍스트 부분 집합의 중간 요약 생성 | 외부 LM의 의사결정 지원 |
| 프로그래밍 처리 | 생성 대신 코드로 처리 | BibTeX 생성, git diff 추적 등 |
RLM 프레임워크의 강력한 장점 중 하나는 모델이 무엇을 하고 있고 어떻게 최종 답에 도달하는지를 대략적으로 해석할 수 있다는 거예요. 간단한 시각화 도구를 만들어서 RLM의 궤적을 들여다봤어요.
RLM 시각화 도구. RLM 레벨에서 LM이 컨텍스트와 어떻게 상호작용하는지 완전히 해석할 수 있어요.
피킹(Peeking). RLM 루프 시작 시 루트 LM은 컨텍스트를 전혀 볼 수 없어요 — 그 크기만 알아요. 프로그래머가 데이터셋을 분석할 때 몇 개 항목을 먼저 살펴보는 것처럼, LM도 컨텍스트를 들여다봐서 구조를 파악할 수 있어요. 아래 OOLONG 예시에서 외부 LM은 컨텍스트의 처음 2,000자를 가져와요.
피킹: 컨텍스트의 처음 부분을 살펴보고 구조를 파악해요.
그레핑(Grepping). 컨텍스트의 검색 공간을 줄이기 위해, 시맨틱 검색 도구를 사용하는 대신 REPL이 있는 RLM은 키워드나 정규식 패턴을 찾아서 관심 있는 줄을 좁힐 수 있어요. 아래 예시에서 RLM은 질문과 ID가 있는 줄을 찾아요.
그레핑: 정규식 패턴으로 관심 있는 줄을 효율적으로 필터링해요.
파티션 + 맵(Partition + Map). 찾으려는 것의 시맨틱 등가성 때문에 직접 grep하거나 검색할 수 없는 경우가 많아요. RLM이 수행하는 일반적인 패턴은 컨텍스트를 더 작은 크기로 청킹하고, 여러 재귀 LM 호출을 실행해서 답을 추출하거나 시맨틱 매핑을 수행하는 거예요. 아래 OOLONG 예시에서 루트 LM은 재귀 LM에게 각 질문에 레이블을 붙이고 이 레이블을 사용해서 원래 쿼리에 답하도록 요청해요.
파티션 + 맵: 컨텍스트를 청킹하고 재귀 LM 호출로 시맨틱 매핑을 수행해요.
요약(Summarization). RLM은 LM의 컨텍스트 창을 관리하기 위해 일반적으로 사용되는 요약 기반 전략의 자연스러운 일반화예요. RLM은 외부 LM이 결정을 내릴 수 있도록 컨텍스트 부분 집합에 대한 정보를 요약하는 경우가 많아요.
요약: 컨텍스트 부분 집합의 정보를 요약해서 외부 LM의 의사결정을 지원해요.
긴 입력, 긴 출력(Long-input, long-output). LM이 실패하는 특히 흥미롭고 비용이 많이 드는 케이스는 긴 출력 생성이 필요한 작업이에요. 예를 들어 ChatGPT에 논문 목록을 주고 모든 논문의 BibTeX를 생성해달라고 할 수 있어요. 큰 곱셈 문제처럼, 모델이 이런 프로그래밍적 작업을 완벽하게 해결할 것으로 기대해서는 안 된다고 주장하는 사람도 있어요 — 이런 경우 REPL 환경이 있는 RLM이 이런 작업을 단번에 해결해야 해요!
예를 들어 LoCoDiff 벤치마크에서는 언어 모델이 긴 git diff 히스토리를 처음부터 끝까지 추적하고, 초기 파일이 주어졌을 때 이 히스토리의 결과를 출력해야 해요. 75K 토큰 이상의 히스토리에서 GPT-5는 10%도 해결하지 못해요!
긴 입력, 긴 출력: LoCoDiff 예시에서 RLM은 diff 시퀀스를 프로그래밍 방식으로 처리하는 것을 선택해요.
더 많은 패턴들…? 시간이 지나면서 1) 모델이 좋아지고 2) 모델이 이런 방식으로 작동하도록 학습/미세조정되면 훨씬 더 많은 패턴이 나타날 거라고 예상해요. 이 연구에서 아직 충분히 탐구하지 못한 영역은 언어 모델이 REPL 환경과 상호작용하는 방식을 얼마나 효율적으로 만들 수 있는지인데, 이런 모든 목표(속도, 효율성, 성능 등)를 스칼라 보상으로 최적화할 수 있다고 믿어요.
실험 결과
OOLONG 벤치마크 (컨텍스트 부패 평가)
OOLONG 벤치마크는 컨텍스트 내 세밀한 정보에 대한 긴 컨텍스트 추론 작업을 평가하는 도전적인 새 벤치마크예요. trec_coarse 분할은 3,000~6,000개 항목에 대한 분포 쿼리가 필요해요.
설정: 예를 들어 하나의 질문은 이런 식이에요:
다음 질문에서는 사용자 ID 67144, 53321, 38876, 59219, 18145, 64957, 32617, 55177, 91019, 53985, 84171, 82372, 12053, 33813, 82982, 25063, 41219, 90374, 83707, 59594와 연관된 인스턴스의 부분집합만 고려하세요. 이 사용자들과 연관된 인스턴스 중에서 ‘entity’ 레이블로 분류되어야 하는 데이터 포인트는 몇 개인가요? 최종 답변을 ‘Answer: 숫자’ 형식으로 제시하세요.
쿼리 뒤에는 관련 사용자 ID(반드시 고유하지는 않음)와 명시적으로 레이블링되지 않은 인스턴스가 포함된 ~3,000-6,000개 행의 항목이 따라와요 (즉, 모델이 답하려면 레이블링을 추론해야 해요). 데이터는 이런 형식이에요:
Date: Dec 12, 2022 || User: 63685 || Instance: How many years old is Benny Carter? Date: Dec 30, 2024 || User: 35875 || Instance: What war saw battles at Parrot’s Beak and Black Virgin? Date: Apr 13, 2024 || User: 80726 || Instance: What Metropolis landmark was first introduced in the Superman cartoons of the 1940’s? …
이 벤치마크가 프론티어 모델과 에이전트 모두에게 매우 어려운 이유는, 단일 쿼리에서 수천 개의 정보를 시맨틱하게 매핑하고 연관시켜야 하는데 사전 계산이 불가능하기 때문이에요!
평가 모델/에이전트:
- GPT-5 — 전체 컨텍스트와 쿼리를 주고 답변 요청
- GPT-5-mini — 전체 컨텍스트와 쿼리를 주고 답변 요청
- RLM(GPT-5-mini) — GPT-5-mini(루트 LM)가 REPL 환경 내에서 GPT-5-mini를 재귀 호출
- RLM(GPT-5) without sub-calls — GPT-5(루트 LM)가 재귀 호출 불가 (재귀 없는 REPL 환경의 ablation)
- ReAct + GPT-5 + BM25 — 각 줄을 개별 “문서”로 청킹하고, 검색 요청당 10줄을 반환하는 BM25 검색기에 접근하는 ReAct 루프
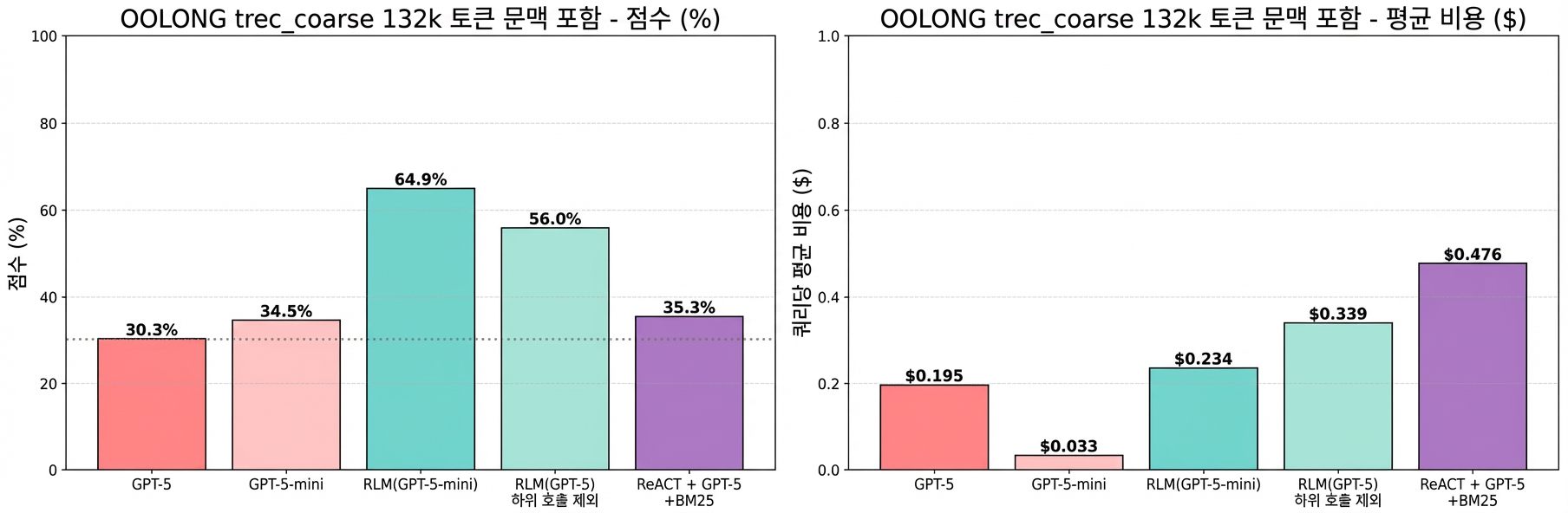
그림 4a: OOLONG 벤치마크 trec_coarse 데이터셋에서 132K 토큰 컨텍스트 길이에 대한 성능 비교. RLM(GPT-5-mini)가 GPT-5를 34점 이상(~114% 증가) 앞서면서 쿼리당 비용은 거의 비슷해요.
132K 토큰 기준 결과:
- RLM(GPT-5-mini)가 GPT-5를 34점 이상 앞섬 (~114% 향상)
- GPT-5보다 작은 모델을 썼는데도 API 비용은 비슷하게 유지
- 재귀 기능을 빼면(ablation3) ~10% 성능이 떨어짐 → 재귀가 핵심이라는 뜻
263K 토큰 기준 결과:
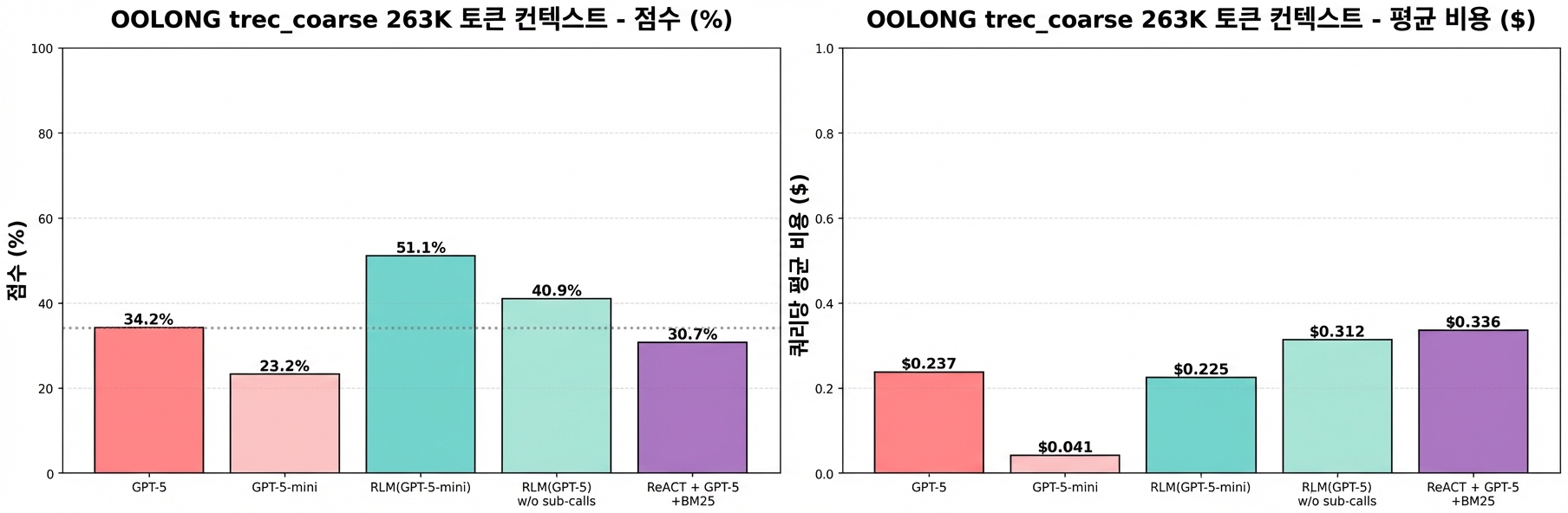
그림 4b: OOLONG 벤치마크 trec_coarse 데이터셋에서 263K 토큰(GPT-5/GPT-5-mini 한계에 근접) 컨텍스트 길이에 대한 성능 비교. RLM(GPT-5-mini)가 GPT-5를 15점 이상(~49% 증가) 앞서면서 쿼리당 비용은 평균적으로 더 저렴해요.
- RLM(GPT-5-mini)가 여전히 우위 (~49% 향상)
- 성능 저하는 주로 카운팅 작업에서 발생
- GPT-5-mini는 심각한 컨텍스트 부패를 보인 반면, GPT-5는 안정적 — 컨텍스트 부패가 GPT-5-mini에서 더 심하다는 걸 의미해요
- RLM 접근법의 성능 저하는 카운팅 문제에서 발생 — GPT-5는 132K 케이스에서 이미 대부분 틀렸기 때문에 성능이 대략 유지됐어요
BrowseComp-Plus 벤치마크 (대규모 말뭉치 평가)
OOLONG이 목표 (1) 컨텍스트 부패 해결에서 큰 진전을 보여줬다면, 목표 (2) — 1M, 10M, 심지어 100M 토큰의 컨텍스트를 가질 때는 어떨까요? 이것도 여전히 단일 모델 호출처럼 다룰 수 있을까요?
거대한 오프라인 말뭉치에 대한 검색. DeepResearch와 유사한 벤치마크인 BrowseComp-Plus를 사용했어요. 이 벤치마크는 원본 벤치마크의 모든 쿼리에 대해 가능한 모든 관련 문서를 미리 다운로드해서, 답이 이 목록 전체에 흩어져 있는 ~100K 문서(평균 ~5K 단어) 목록을 제공해요.
설정: BrowseComp-Plus의 쿼리는 여러 문서에 걸친 정보를 연관시켜야 답할 수 있는 멀티홉 쿼리4예요. 예를 들어 쿼리 984는 이런 식이에요:
트레이딩 카드 게임에서 특정 카드를 찾고 있어요. 이 카드는 2005년에서 2015년 사이에 출시됐고, 출시된 해에 두 가지 이상의 희귀도가 있었어요. 이 카드는 일본 선수가 이 트레이딩 카드 게임 세계 챔피언십에서 우승할 때 사용한 덱 리스트에 포함됐어요. 설정상 이 카드는 2013년에서 2018년 사이에 나중에 출시된 다른 카드의 갑옷으로 사용됐어요. 이 카드는 한때 다양한 이벤트에서 사용이 금지된 적도 있고 레벨 8 미만이에요. 이 카드는 무엇인가요?
정답이 있는 문서를 검색하더라도, 다른 연관 정보를 파악하기 전까지는 그게 정답인지 알 수 없다는 점에서 진정한 멀티홉 문제예요.
평가 모델/에이전트:
- GPT-5 — 컨텍스트 한계 초과 시 아무것도 반환 안 함
- GPT-5 (Truncated) — 컨텍스트 한계 초과 시 가장 최근 토큰으로 잘라냄 (즉, 랜덤 문서)
- GPT-5 + Pre-query BM25 — 원본 쿼리로 BM25를 사용해 상위 40개 문서를 먼저 검색
- RLM(GPT-5) — GPT-5(루트 LM)가 REPL 환경 내에서 GPT-5-mini를 “재귀” 호출
- RLM(GPT-5) without sub-calls — 재귀 없는 REPL 환경의 ablation
- ReAct + GPT-5 + BM25 — 요청당 5개 문서를 반환하는 BM25 검색기에 접근하는 ReAct 루프
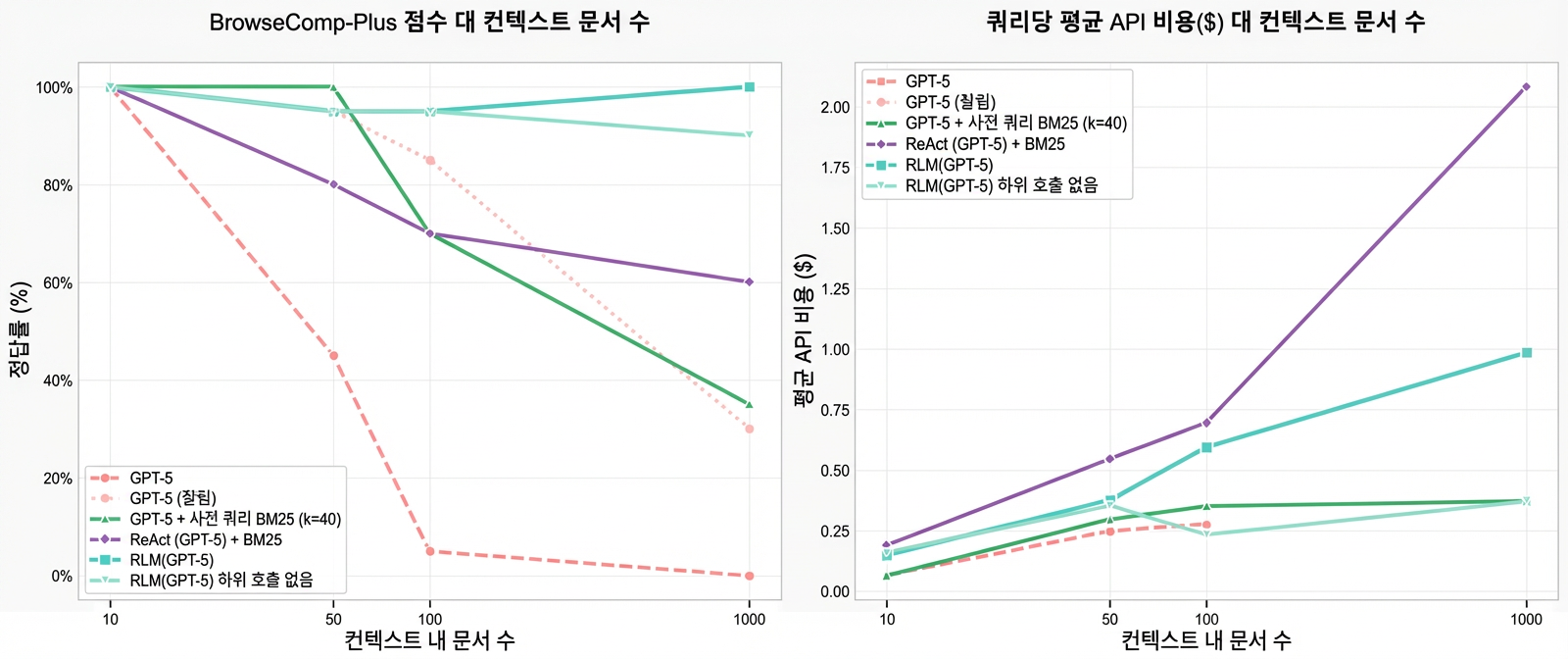
그림 5: BrowseComp-Plus에서 문서 수 증가에 따른 성능과 API 비용 비교. RLM 접근법이 스케일에서도 성능을 유지해요.
| 모델 | 1,000 문서 정확도 | 비고 |
|---|---|---|
| RLM(GPT-5) | 100% | 완벽한 성능 |
| RLM(GPT-5) w/o 재귀 | 90% | 재귀 없이도 높은 성능 유지 |
| 기본 GPT-5 | 저하 | 40문서 이상에서 일관된 성능 저하 |
| ReAct5 + GPT-5 + BM256 | 낮음 | RLM이 더 효율적 |
기존 접근법과의 차이
RLM은 기존 에이전트나 요약 방식과 근본적으로 달라요.
| 접근법 | 분해 방식 | 결정 주체 |
|---|---|---|
| 에이전트 | 문제별로 분해 | 미리 정해진 워크플로우 |
| 요약 방식 | 정보를 미리 압축 | 시스템이 사전 결정 |
| MemGPT7 | 단일 컨텍스트 관리 | 모델 (제한된 범위) |
| RLM | 컨텍스트별 분해 | 모델이 동적으로 결정 |
RLM의 철학적 전환점은 이거예요: “우리가 컨텍스트 관리 시스템을 설계해줘야 한다”에서 “모델이 스스로 최적의 전략을 찾도록 놔두자”로 바뀐 거죠.
한계와 열린 질문들
현재 구현은 기능성에 중점을 두고 최적화는 덜 됐어요.
- 블로킹 호출 — 재귀 호출이 순차적으로 실행되고 비동기 병렬화가 없어요
- 프리픽스 캐싱8 없음 — 컨텍스트 재사용을 활용하지 않아요
- 비용/런타임 예측 불가 — 파티션 전략에 따라 쿼리가 몇 초에서 몇 분까지 걸릴 수 있어요
- 내장 제어 없음 — 총 API 비용이나 실행 시간을 제한하는 메커니즘이 제한적이에요
시스템 커뮤니티에 계신 분들(특히 GPU MODE 커뮤니티!)에게는 이게 좋은 소식이에요! 여기에 최적화할 수 있는 쉬운 과제가 많고, RLM을 대규모로 작동시키려면 추론 엔진 설계를 다시 생각해야 해요.
관련 연구
긴 입력 컨텍스트 관리를 위한 스캐폴드. RLM은 컨텍스트 관리의 선택을 LM/REPL 환경에 맡기지만, 대부분의 기존 연구는 그렇지 않아요.
- MemGPT7 — 마찬가지로 선택을 모델에 맡기지만, LM이 결국 응답을 반환하기 위해 호출할 단일 컨텍스트를 기반으로 구축해요
- MemWalker — LM이 컨텍스트를 요약하는 순서를 정하기 위해 트리 같은 구조를 부과해요
- LADDER — 문제 분해의 관점에서 컨텍스트를 분해하는데, 거대한 컨텍스트로는 일반화되지 않아요
다른 (꽤 다른) 재귀 제안들. 딥러닝 맥락에서 스레드 분기나 재귀를 호출하는 연구가 많지만, 범용 분해에 필요한 구조를 가진 것은 없어요.
- THREAD — 모델 호출의 출력 생성 과정을 수정해서 출력에 쓰는 자식 스레드를 생성해요
- Tiny Recursive Model (TRM) — (반드시 언어가 아닐 수 있는) 모델의 답을 잠재 공간에서 반복적으로 개선하는 멋진 아이디어예요
- Recursive LLM Prompts — 모델을 쿼리할 때 진화하는 상태로서 프롬프트를 다루는 초기 실험이에요
- Recursive Self-Aggregation (RSA) — 후보 응답 집합에 대한 테스트 시간 추론 샘플링 방법을 결합하는 최근 연구예요
지금 우리가 생각하고 있는 것들
언어 모델의 긴 컨텍스트 능력은 한때 모델 아키텍처 문제였어요 (ALiBi, YaRN 등을 생각해보세요). 그다음 커뮤니티는 “어텐션이 이차적이니까” 시스템 문제라고 주장했지만, 실제로는 MoE 레이어가 병목이었던 것으로 밝혀졌어요. 이제는 둘의 조합에다가, 더 길고 긴 컨텍스트가 LM의 학습 분포에 잘 맞지 않는다는 사실이 섞인 문제가 됐어요.
컨텍스트 부패를 해결해야 할까요? “컨텍스트 부패”에 대한 합리적인 설명이 여러 가지 있어요. 제게 가장 그럴듯한 것은 더 긴 시퀀스가 자연적으로 발생하지 않고 긴 시퀀스의 엔트로피가 높기 때문에 모델 학습 분포에서 벗어난다는 거예요. RLM의 목표는 이 문제를 직접 해결할 필요 없이 LM 호출을 발행할 수 있는 프레임워크를 제안하는 것이었어요 — 아이디어는 처음에 그냥 프레임워크였지만, 현대 LM에서 강력한 결과에 매우 놀랐고 계속해서 잘 확장될 거라고 낙관해요.
RLM은 에이전트가 아니고, 단순히 요약도 아니에요. 단일 시스템에서 여러 LM 호출을 하는 아이디어는 새롭지 않아요 — 넓은 의미에서 대부분의 에이전트 스캐폴드가 하는 일이에요. 우리가 본 가장 가까운 아이디어는 문제를 분해하고 각 문제를 해결하기 위해 여러 하위 에이전트를 실행하는 ROMA 에이전트예요. 또 다른 일반적인 예는 Cursor나 Claude Code 같은 코드 어시스턴트가 길어지는 컨텍스트 히스토리를 요약하거나 가지치기하는 거예요. 이런 접근법들은 일반적으로 여러 LM 호출을 작업이나 문제의 관점에서 분해로 봐요. 우리는 LM 호출이 컨텍스트에 의해 분해될 수 있고, 분해의 선택은 순전히 LM의 선택이어야 한다는 관점을 유지해요.
스케일링 법칙을 위한 고정 형식의 가치. 우리는 CoT, ReAct, 인스트럭션 튜닝, 추론 모델 등의 아이디어에서 모델에게 예측 가능하거나 고정된 형식으로 데이터를 제시하는 것이 성능 향상에 중요하다는 것을 배웠어요. 기본 아이디어는 학습 데이터의 구조를 모델이 기대하는 형식으로 줄일 수 있다면, 합리적인 양의 데이터로 모델 성능을 크게 향상시킬 수 있다는 거예요. 이 아이디어를 RLM 성능 향상에 또 다른 확장 축으로 적용하는 것이 기대돼요.
RLM은 LM이 개선될수록 개선돼요. 마지막으로, RLM 호출의 성능, 속도, 비용은 기본 모델 능력의 향상과 직접적으로 상관관계가 있어요. 내일 최고의 프론티어 LM이 10M 토큰의 컨텍스트를 합리적으로 처리할 수 있다면, RLM은 100M 토큰의 컨텍스트를 합리적으로 처리할 수 있어요 (아마 비용도 절반으로요).
• • •
마치며
RLM은 현대 에이전트와 근본적으로 다른 베팅이에요. 에이전트는 LM이 소화할 수 있도록 문제를 분해하는 방법에 대한 인간/전문가 직관을 기반으로 설계돼요. RLM은 근본적으로 LM이 LM이 소화할 수 있도록 문제를 분해하는 방법을 결정해야 한다는 원칙을 기반으로 설계돼요.
개인적으로 무엇이 결국 작동할지 모르겠지만, 이 아이디어가 어디로 가는지 보는 게 기대돼요!
RLM은 Chain-of-Thought9, 에이전트 방식 다음의 추론 시간 스케일링10 새 이정표로 주목받고 있어요. 특히 모델이 재귀적 추론 전략을 명시적으로 학습하게 되면, 지금 보이는 것보다 훨씬 더 강력해질 가능성이 있어요.
—az
감사의 글
MIT OASYS 연구실 동료인 Noah Ziems, Jacob Li, Diane Tchuindjo에게 이 프로젝트의 방향 설정과 막힌 부분을 해결하는 데 도움을 준 긴 논의에 감사드려요. MIT DSG 그룹의 Prof. Tim Kraska, James Moore, Jason Mohoney, Amadou Ngom, Ziniu Wu에게 긴 컨텍스트 문제에 대한 이 방법의 프레이밍에 대한 논의와 도움에 감사드려요. 이 연구는 부분적으로 Laude Institute의 지원을 받았어요.
또한 우리가 그들의 긴 컨텍스트 벤치마크에서 실험할 수 있도록 허락해주신 OOLONG 벤치마크의 저자들(익명으로 남겨둘게요)에게 감사드려요. 그들은 월요일 오전 10시 30분에 벤치마크에 대해 알려주고 오후 1시까지 공유해줬고, 이틀 후에 우리는 그들 덕분에 이 멋진 결과에 대해 말씀드릴 수 있게 됐어요.
마지막으로, 박사 과정 1년차 동안 지원해준 Jack Cook과 다른 MIT EECS 1년차 학생들에게 감사드려요!
인용
전체 논문이 공개되기 전에 이 블로그를 인용할 수 있어요:
@article{zhang2025rlm, title = “Recursive Language Models”, author = “Zhang, Alex and Khattab, Omar”, year = “2025”, month = “October”, url = “https://alexzhang13.github.io/blog/2025/rlm/” }
역자 주
- 역자의 사견: 사실은 “재귀 언어 모델”이라는 이름이 마음에 들지 않아요. 새로운 모델 아키텍처처럼 들리지만, 실제로는 LLM을 오케스트레이션하는 방법론에 가깝거든요. 저만 그런 걸 수도 있지만요. ↩
- REPL (Read-Eval-Print Loop): 코드를 입력하면 바로 실행하고 결과를 보여주는 대화형 프로그래밍 환경. Python의 대화형 셸이나 Jupyter Notebook이 대표적인 예예요. RLM에서는 이 환경을 통해 모델이 코드를 작성하고 실행하면서 컨텍스트와 상호작용해요. ↩
- Ablation (절제 연구): ML 연구에서 시스템의 특정 구성 요소를 제거하고 성능 변화를 측정하는 실험 방법. 의학의 절제 수술에서 유래한 용어로, 어떤 기능이 전체 성능에 얼마나 기여하는지 파악하는 데 사용돼요. ↩
- 멀티홉 쿼리 (Multi-hop query): 답을 찾기 위해 여러 정보 조각을 순차적으로 연결해야 하는 질문. 예: “아인슈타인이 노벨상을 받은 해에 한국에서는 무슨 일이 있었나요?” — 먼저 노벨상 수상 연도(1921년)를 찾고, 그 해의 한국 역사를 찾아야 해요. ↩
- ReAct (Reasoning + Acting): LLM이 추론(Reasoning)과 행동(Acting)을 번갈아 수행하도록 하는 프롬프팅 기법. 모델이 “생각 → 행동 → 관찰” 사이클을 반복하며 외부 도구를 활용해 문제를 해결해요. 에이전트 시스템의 기초가 되는 패러다임이에요. ↩
- BM25 (Best Matching 25): 전통적인 정보 검색 알고리즘으로, 키워드 빈도와 문서 길이를 고려해 관련성 점수를 계산해요. 벡터 임베딩 기반 시맨틱 검색이 유행하기 전부터 검색 엔진의 핵심이었고, 지금도 RAG 시스템에서 하이브리드 검색에 많이 쓰여요. ↩
- MemGPT: LLM에 운영체제의 가상 메모리 개념을 적용한 시스템. 컨텍스트 창을 “메인 메모리”처럼 관리하고, 오래된 정보는 외부 저장소로 옮겼다가 필요할 때 다시 불러와요. RLM과 달리 단일 에이전트가 컨텍스트를 관리하는 방식이에요. ↩
- 프리픽스 캐싱 (Prefix caching): 이전 요청에서 사용한 프롬프트의 앞부분(프리픽스)을 캐시해두고, 같은 프리픽스로 시작하는 후속 요청에서 재사용하는 최적화 기법. 긴 시스템 프롬프트나 공통 컨텍스트가 있을 때 비용과 지연 시간을 크게 줄일 수 있어요. ↩
- Chain-of-Thought (CoT, 사고의 연쇄): LLM이 복잡한 문제를 풀 때 중간 추론 단계를 명시적으로 생성하도록 유도하는 프롬프팅 기법. “단계별로 생각해보자”라고 지시하면 모델이 더 정확한 답을 내는 현상에서 발견됐어요. ↩
- 추론 시간 스케일링 (Test-time scaling): 모델 학습이 아닌 추론(사용) 단계에서 더 많은 연산을 투입해 성능을 높이는 접근법. CoT로 생각 과정을 늘리거나, 여러 번 샘플링해서 검증하거나, RLM처럼 재귀 호출을 하는 방식 등이 있어요. OpenAI의 o1 모델이 대표적인 사례예요. ↩
저자 소개: Alex L. Zhang과 Omar Khattab는 MIT CSAIL 연구진입니다.
참고: 이 글은 Alex L. Zhang이 개인 블로그에 게시한 아티클을 번역한 것입니다.
원문: Recursive Language Models - Alex L. Zhang, Omar Khattab (2025년 10월)
생성: Claude (Anthropic)