AI 에이전트의 채택과 사용: Perplexity 초기 데이터 분석
게시일: 2025년 12월 19일 | 원문 작성일: 2025년 12월 7일 | 저자: Perplexity 연구팀 | 원문 보기
핵심 요약
익명화된 수억 건의 실제 사용 기록을 분석한 최초의 대규모 연구예요. AI 에이전트를 실제로 누가, 얼마나, 뭘 위해 쓰는지 밝혀냈어요.
- 누가 쓰나? — 얼리 어답터, 고소득 국가, 지식 집약 직군(IT, 학계, 금융, 마케팅)이 주도해요
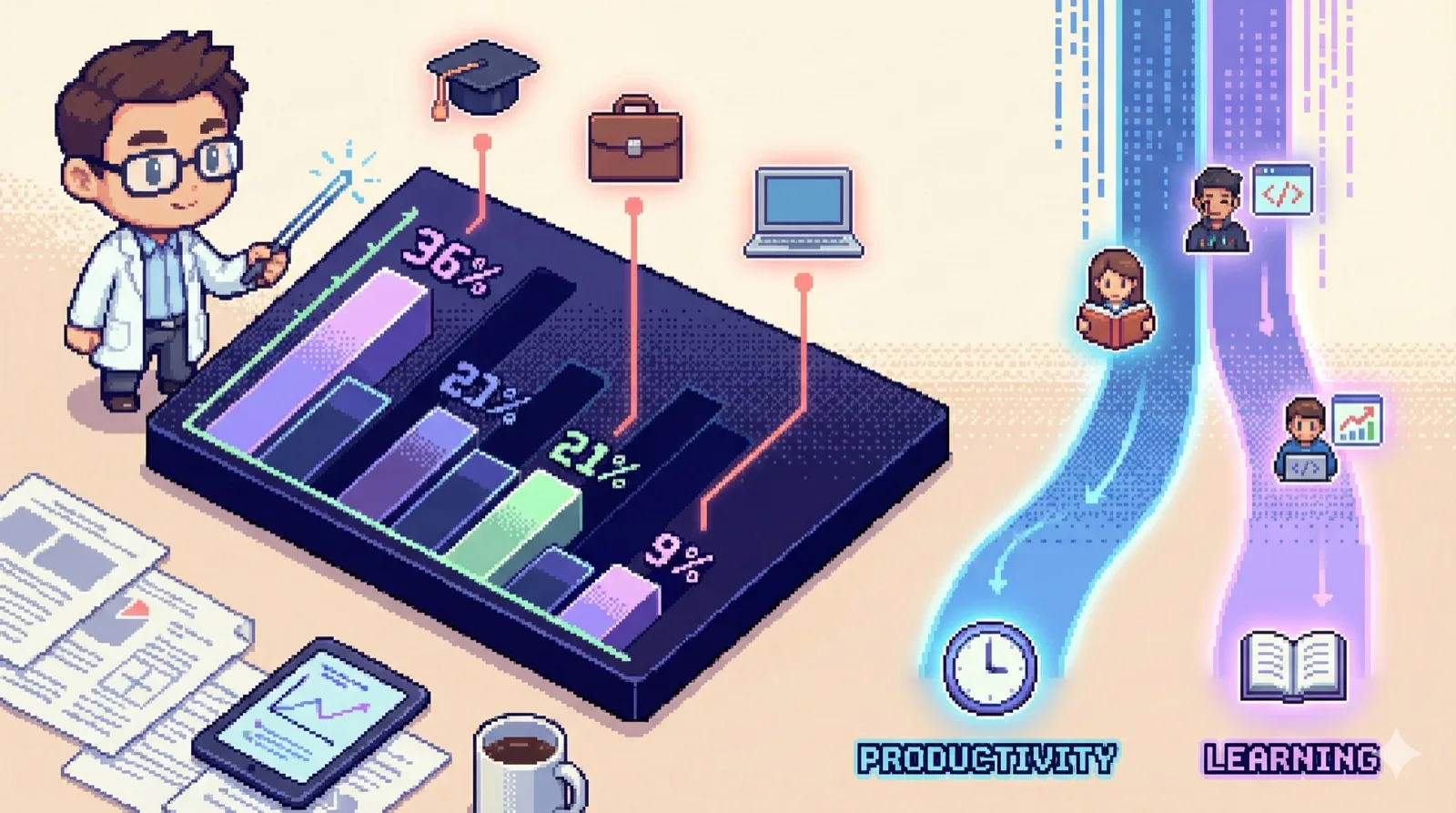
- 뭘 위해 쓰나? — 생산성/워크플로우(36%)와 학습/연구(21%)가 전체의 57%를 차지해요
- 어디서 쓰나? — Google Docs, 이메일, LinkedIn, YouTube, Amazon이 상위 5개 환경이에요
- 시간이 지나면? — 초기 탐색에서 점차 생산성과 학습 중심으로 사용 패턴이 진화해요
- 불평등 우려 — 현재 채택 패턴이 기존의 생산성/학습 격차를 더 벌릴 수 있어요
2025년, “에이전트 AI의 해”
2025년은 “에이전트 AI의 해”로 널리 인식되고 있어요. 챗봇은 정보를 알려줄 뿐이지만, 에이전트는 직접 일을 해결해 줘요. 이런 차이가 중요하기 때문에 대화형 LLM 챗봇에서 행동을 취하는 AI 에이전트로 큰 전환이 일어나고 있는 거예요.
AI 에이전트란 뭘까요? 사용자가 목표만 정해주면 스스로 달성해 나가는 시스템이에요. 핵심 특성은 이런 거예요:
- 목표 지향성 — 명확한 목표를 향해 작동해요
- 행동 수행 — 정보 교환뿐 아니라 실제로 환경을 수정해요
- 자율성 — 사람의 개입 없이 작업을 진행해요
LLM이 “두뇌”라면, 에이전트는 실제로 행동하는 “손”이에요. 이런 “생각하고 행동하기”를 체계적으로 반복하는 방식이 있어요. ReAct1라는 프레임워크인데요: 생각(계획) → 행동(실행) → 관찰(피드백) → 반복.
시장 전망: 글로벌 에이전트 AI 시장은 2025년 80억 달러에서 2034년 1,990억 달러로 성장할 전망이에요. PwC에 따르면 2030년까지 연간 2.6조~4.4조 달러의 경제적 가치를 창출할 수 있다고 해요.
하지만 이런 열기에도 불구하고, 실제로 사람들이 어떻게 쓰는지에 대한 체계적인 데이터는 부족했어요. 이 연구는 Perplexity의 AI 기반 브라우저 Comet과 그 내장 에이전트 Comet Assistant의 수억 건 익명 상호작용을 분석해서 그 궁금증을 풀어줘요.
연구 방법론
2025년 7월 9일 출시부터 10월 22일까지의 데이터를 분석했어요. 세 가지 샘플을 활용했죠:
| 샘플 | 크기 | 용도 |
|---|---|---|
| 샘플 A | 전체 수백만 사용자 | 도입율 및 사용 강도 전체 통계 |
| 샘플 B | 무작위 10만 명 | 직업군별 도입 및 사용 분석 |
| 샘플 C | 에이전트 사용자 10만 명 | 사용 사례 심층 분석 및 종단 패턴 |
사용자들이 에이전트에게 어떤 일을 맡기는지 체계적으로 정리하려고 데이터를 바탕으로 3단계를 거쳐 새 분류 체계를 만들었어요. K-means 클러스터링2으로 비슷한 질문들을 묶고, 사람이 직접 검토해서 구조화했어요:
결과물은 3단계 계층 구조예요:
- 레벨 1 (주제): 생산성 & 워크플로우
- 레벨 2 (하위 주제): 이메일 관리
- 레벨 3 (작업): 이메일 검색/필터, 이메일 삭제/구독 해지
핵심 발견 1: 누가 얼마나 쓰나?
두 가지 주요 지표를 도입했어요:
- AAR (Agent Adoption Ratio) — 특정 그룹에서 에이전트를 도입한 비율이 전체 평균 대비 얼마나 높은지
- AUR (Agent Usage Ratio) — 특정 그룹에서 에이전트를 쓰는 빈도가 전체 평균 대비 얼마나 높은지
AAR이나 AUR이 1보다 크면 해당 그룹이 평균보다 더 많이 도입하거나 쓴다는 뜻이에요. 예를 들어 AAR이 2라면, 그 그룹은 평균보다 2배 많이 에이전트를 도입했다는 거예요.
사용자 코호트별 분석
10월 2일 GA3 전에 접근한 얼리 어답터는 전체 사용자의 약 30%지만, 에이전트 도입자의 50%, 전체 에이전트 쿼리의 70%를 차지해요.
첫 번째 코호트(7월 9일)는 GA 코호트 대비:
- 에이전트 도입 가능성 2배
- 평균 에이전트 쿼리 수 9배
기술 확산의 전형적인 패턴이에요. 다만 유료 구독자에게 먼저 공개하고 나중에 무료 사용자에게 열었기 때문에 이런 차이가 생긴 점은 감안해야 해요.
국가별 분석
에이전트 도입과 사용 강도는 국가의 경제·교육 지표와 강한 양의 상관관계를 보여요:
| 지표 | 상관계수 (r) | 결정계수 (R²) |
|---|---|---|
| 1인당 GDP | 0.85 | 0.73 |
| 평균 교육 연수 | 0.75 | 0.56 |
경제력과 교육 수준이 높은 국가의 사용자들이 AI 에이전트 도입을 주도하고 있어요.
직업군별 분석
에이전트 도입은 디지털과 지식 집약 분야에 몰려 있어요:
| 직업 클러스터 | 도입자 비율 | 쿼리 비율 |
|---|---|---|
| 디지털 기술 | 28% | 30% |
| 학계 | 상위권 | |
| 금융 | 상위권 | |
| 마케팅 | 상위권 | |
| 창업 | 상위권 | |
이 지식 집약 분야들이 총 도입자와 쿼리의 70% 이상을 차지해요.
흥미로운 점: 학생, 창업, 마케팅 그룹에서는 에이전트를 도입한 비율보다 실제 사용 빈도가 더 높아요. 일단 써보면 더 자주 찾게 된다는 뜻이죠. 그만큼 유용하게 쓰고 있다는 신호예요.
핵심 발견 2: 뭘 위해 쓰나?
주요 주제와 하위 주제
에이전트 쿼리의 분포는 소수 영역에 집중되어 있어요:
| 주제 | 쿼리 비율 |
|---|---|
| 생산성 & 워크플로우 | 36% |
| 학습 & 연구 | 21% |
| 미디어 & 엔터테인먼트 | 16% |
| 쇼핑 & 커머스 | 10% |
상위 2개 주제가 전체의 57%를 차지해요. 에이전트가 지적 업무와 실무를 돕는 도구로 자리잡고 있다는 뜻이에요.
하위 주제 수준에서 가장 큰 두 카테고리는:
- 강좌: 전체 쿼리의 13%
- 상품 쇼핑: 전체 쿼리의 9%
가장 흔한 작업들
작업 수준으로 내려가면 분포가 더 집중돼요. 90개 식별된 작업 중 상위 10개가 전체 쿼리의 55%를 차지해요.
| 순위 | 작업 | 비율 |
|---|---|---|
| 1 | 연습문제 풀이 도움 | 9.41% |
| 2 | 연구 정보 요약/분석 | 6.71% |
| 3 | 문서/양식 생성/편집 | 6.58% |
| 4 | 제품 검색/필터 | 6.43% |
| 5 | 연구 정보 검색/필터 | 5.95% |
상위 10개 작업 중 절반이 학습·연구 관련이에요. 지식 습득과 분석에 에이전트를 많이 활용한다는 의미죠.
사용 맥락과 환경
에이전트 쿼리는 세 가지 맥락에 분포해요:
- 개인: 55%
- 업무: 30%
- 교육: 16%
각 맥락마다 뚜렷한 초점이 있어요. 업무 사용은 생산성과 커리어 관련 작업(80%), 교육 사용은 거의 전적으로 학습(89%)에 집중돼요.
에이전트가 작업을 수행하는 “환경”(웹사이트)도 집중되어 있어요. 상위 5개 환경이 전체 에이전트 쿼리의 43%를 차지해요:
| 환경 | 비율 |
|---|---|
| docs.google.com | 11.97% |
| 이메일 서비스(통합) | 11.23% |
| linkedin.com | 9.42% |
| youtube.com | 7.03% |
| amazon.com | 3.46% |
다만 이 집중도는 하위 주제마다 크게 달라요. 예를 들어 음악은 Spotify나 YouTube Music 몇 곳에 집중되어 상위 5개 환경이 97%를 차지하지만, 계정 관리는 수많은 사이트에 분산되어 28%에 불과해요.
시간에 따른 사용 패턴 변화
사용자들은 한번 시작한 주제에 계속 머무르는 경향이 강해요 (이를 “stickiness”라고 해요). 연속해서 비슷한 질문을 하는 거죠. 특히 생산성, 학습, 커리어 관련 작업에서요.
시간이 지나면서 주목할 만한 변화가 나타나요:
사용자들이 익숙해지면서 초기의 신기함 추구에서 중요한 학습이나 업무에 에이전트를 자연스럽게 활용하는 방향으로 진화해요.
시사점과 논의
이 연구는 범용 AI 에이전트의 실제 도입과 활용에 대한 첫 대규모 실증 데이터를 제공해요. 그룹마다 사용 패턴이 꽤 다르고, 초기 패턴은 경제적으로 발전한 국가의 기술에 익숙한 지식 집약적 사용자들이 주도하고 있어요.
이해관계자별 시사점
| 이해관계자 | 시사점 |
|---|---|
| 연구자 | 계층적 에이전트 분류 체계가 향후 분석의 출발점이 될 수 있음 |
| AI 개발사 | 유망한 타겟 세그먼트(지식 근로자)와 고빈도 사용 사례(연구, 문서 관리) 파악 가능 |
| 플랫폼 기업 (Google, LinkedIn 등) | AI를 통해 접속하는 사용자를 위한 인터페이스 간소화 기회 |
| 정책입안자 & 교육자 | 불균등한 도입이 기존 생산성·학습 격차를 키울 수 있음. 더 폭넓은 AI 리터러시 교육이 중요해질 수 있음 |
연구의 한계
이 연구에는 몇 가지 한계가 있어요:
- 샘플이 주로 얼리 어답터를 반영하며, 일반 대중을 대표한다고 보기 어려워요
- 쿼리 분류에는 위양성(에이전트 요청이 아닌데 그렇게 분류)과 위음성(에이전트 요청인데 놓침)의 노이즈가 있을 수 있어요
- 수집한 데이터만으로는 에이전트가 작업을 완전히 대신한 건지, 단순히 도와준 건지 구분하기 어려워요
향후 연구 방향
- 플랫폼 간 에이전트 사용 차이
- 기업 특화 사용 사례
- 체계적인 에이전트 성능 평가
- 에이전트 지원에서 파생되는 경제적 가치 정량화
범용 AI 에이전트는 큰 기술적 진전이에요. 그 실제 영향을 이해하는 게 중요하고, 이 연구가 후속 연구의 출발점이 되길 바라요.
역자 주
- ReAct: “Reasoning + Acting”의 줄임말이에요. 2022년 프린스턴과 구글이 발표한 논문에서 제안된 프레임워크로, AI가 추론(Reasoning)과 행동(Acting)을 번갈아 수행하면서 복잡한 문제를 해결하는 방식이에요. 단순히 한 번에 답을 내놓는 게 아니라, 생각 → 행동 → 결과 관찰 → 다시 생각의 사이클을 반복해요. ↩
- K-means 클러스터링: 데이터를 K개의 그룹으로 나누는 대표적인 비지도 학습 알고리즘이에요. 여기서는 사용자 쿼리들의 임베딩(텍스트를 숫자 벡터로 변환한 것)을 분석해서 의미적으로 비슷한 질문들끼리 자동으로 묶었어요. ↩
- GA (General Availability): 소프트웨어 업계에서 제품이 모든 사용자에게 공개되는 시점을 말해요. 그 전에는 보통 베타 테스터나 유료 구독자 등 제한된 그룹에게만 먼저 공개해요. Comet의 경우 10월 2일에 GA가 되어 누구나 사용할 수 있게 됐어요. ↩
참고: 이 글은 Perplexity 연구팀의 학술 논문을 요약·번역한 것입니다. AI 에이전트의 실제 사용 패턴에 대한 첫 대규모 실증 연구로, 향후 기술 발전과 정책 수립에 중요한 기초 자료가 될 것입니다.
원문: The Adoption and Usage of AI Agents: Early Evidence from Perplexity - Perplexity 연구팀, arXiv (2025년 12월 7일)
생성: Claude (Anthropic)