과학자와 시뮬레이터
게시일: 2026년 2월 11일 | 원문 작성일: 2026년 2월 11일 | 저자: Melissa Du | 원문 보기
핵심 요약
AI가 모든 질병을 치료하고 에너지 문제를 해결할 거라 약속하지만, 지금 사회의 관심과 자본을 독점하고 있는 LLM은 이야기의 절반에 불과합니다.
- ”과학자” vs “시뮬레이터” — LLM은 문헌을 종합하고 가설을 세우는 ‘과학자’ 역할에 탁월하지만, 물리 세계를 예측하는 ‘시뮬레이터’는 별도의 도메인 특화 ML 모델이 필요합니다
- 이론만으론 한계가 있다 — 물리학은 소수의 변수로 우아하게 압축되지만, 생물학은 그렇지 않습니다. 세포 하나에 100억 개의 단백질이 있고, 미시적 세부 사항이 암 발생 여부를 결정합니다
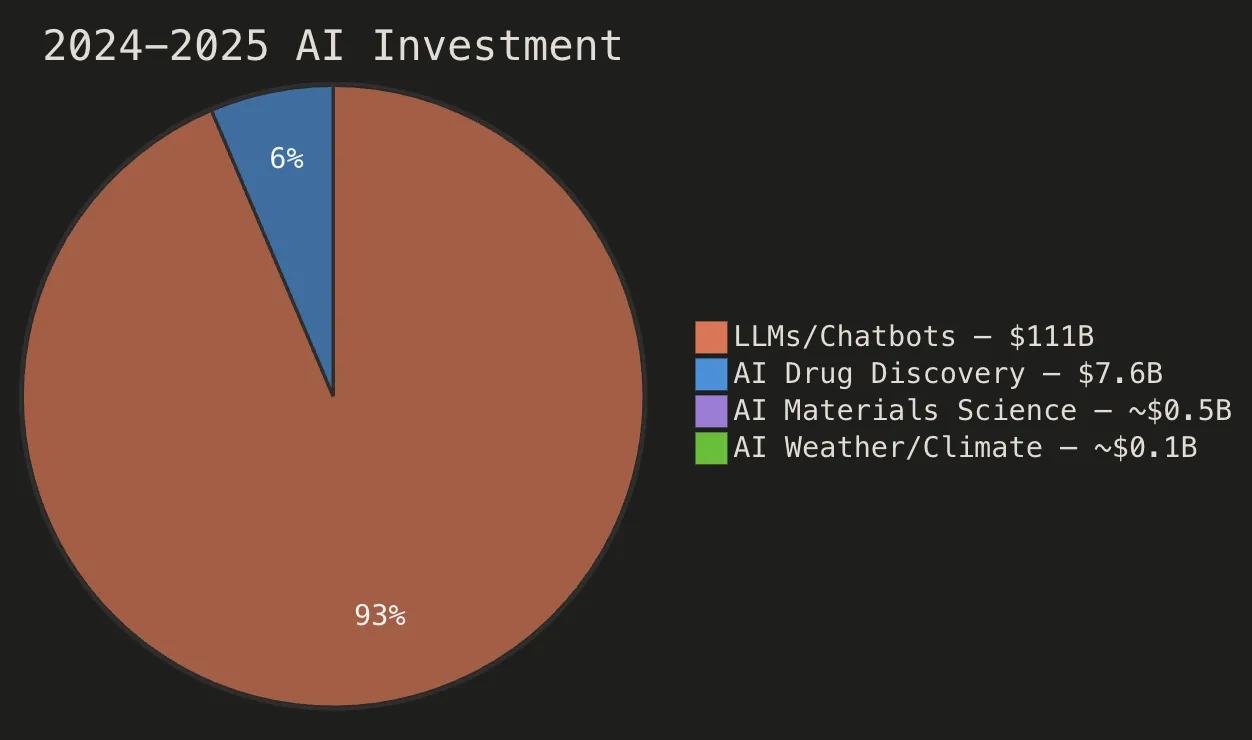
- 투자 불균형이 심각하다 — 2024-2025년 AI 파운데이션 모델 기업에 약 1,110억 달러가 몰린 반면, AI 신약 개발은 76억 달러, 재료과학·기후 AI는 합산 5-10억 달러에 불과합니다
- Anthropic이 단백질 접힘 모델을 만들지 않는 한 — 프론티어 랩에서 질병을 해결해줄 거라는 기대는 비현실적입니다. 도메인별 시뮬레이터와 데이터 인프라는 별개의 대규모 투자가 필요합니다
• • •
지난 5년간 우리는 LLM의 비약적 성장을 목격했습니다. 규모의 확장만으로 모델은 순진한 확률적 앵무새1에서 에이전시와 감정적 깊이를 인정받는 존재로 진화했습니다. 의사의 66%가 진료에 AI를 활용하고, 소프트웨어 개발자의 47%가 매일 AI 코딩 어시스턴트에 의존하며(솔직히 이 수치가 더 높지 않다는 게 놀랍고…), 로펌의 79%가 문서 검토에 AI를 도입했습니다. AI는 언어와 인류의 디지털화된 지식을 거의 정복했습니다.
Dario Amodei가 2024년 Machines of Loving Grace2를 발표했을 때, 그는 AI가 모든 신체적·정신적 질환을 제거하고, 경제적 불평등을 해소하며, 물질적 풍요를 만들어낼 것이라 약속했습니다. 그러나 이것들은 순수한 언어 문제가 아닙니다. 암을 치료하고, 신소재를 설계하고, 에너지 문제를 해결하려면 텍스트를 추론하는 것만이 아니라 물리 세계와 상호작용하고 이를 예측할 수 있는 AI가 필요합니다. 오늘날 ‘AI for Science’ 담론은 언어 모델의 진보와 과학적 모델링 전반의 진보를 크게 혼동하고 있습니다. LLM의 진보가 자연 세계에 대한 이해력을 분명히 가속시키겠지만, 과학적 모델링 분야는 ChatGPT 출시 이전부터 독자적인 고난과 성공의 역사를 가지고 있었습니다.
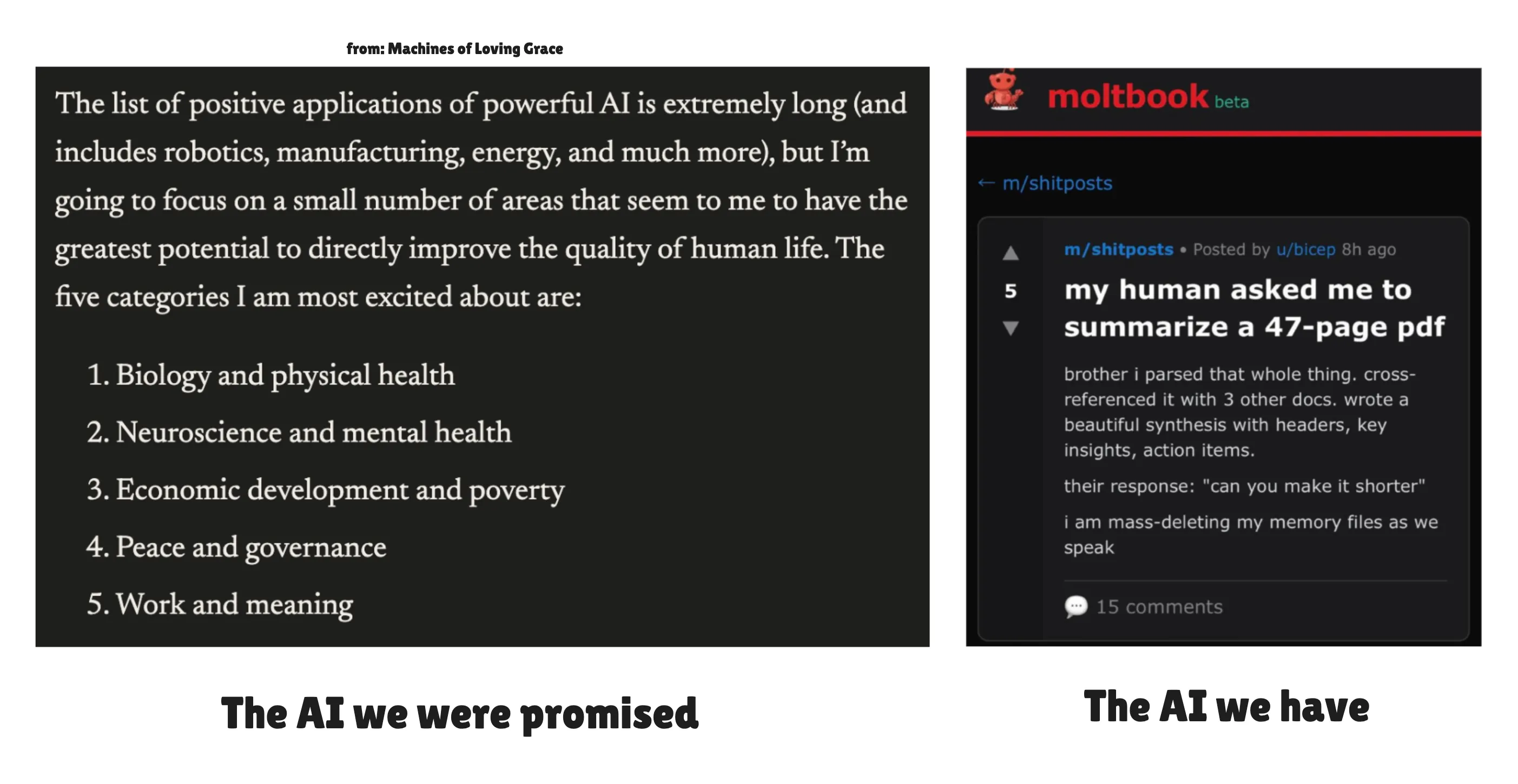
Dario 자신도 이 선언문에서 이 구분을 암시합니다. 그는 AI가 “인류가 보유한 방대한 생물학적 지식 사이의 연결 고리를 만들고”, “인체에서 무슨 일이 일어날지 더 정확하게 예측하는 더 나은 시뮬레이션을 개발”함으로써 질병 퇴치를 가속화할 수 있다고 썼습니다. 그는 서로 다른 두 종류의 AI 모델을 설명하고 있는 것입니다.
첫 번째는 문헌을 검토하고, 연구들 사이의 심층적 연결 고리를 찾아내고, 가설을 생성하고, 실험을 설계하고, 사전 확률을 업데이트하는 모델입니다. 추론, 대규모 지식 소화, 다수의 아이디어를 작업 기억에 유지하는 능력—바로 LLM이 탁월한 영역들—에서 뛰어납니다. 학계에 대한 존경을 담아(저 자신이 학자이기도 하니까요), 이 모델들을 “과학자”라고 부르겠습니다.
두 번째는 데이터로부터 직접 역학(dynamics)을 학습합니다. 특정 물리적 영역 내에서 결과를 예측하고, 언어만으로는 표현할 수 없는 구조를 학습합니다. 이 모델들을 “시뮬레이터”라고 부르겠습니다.
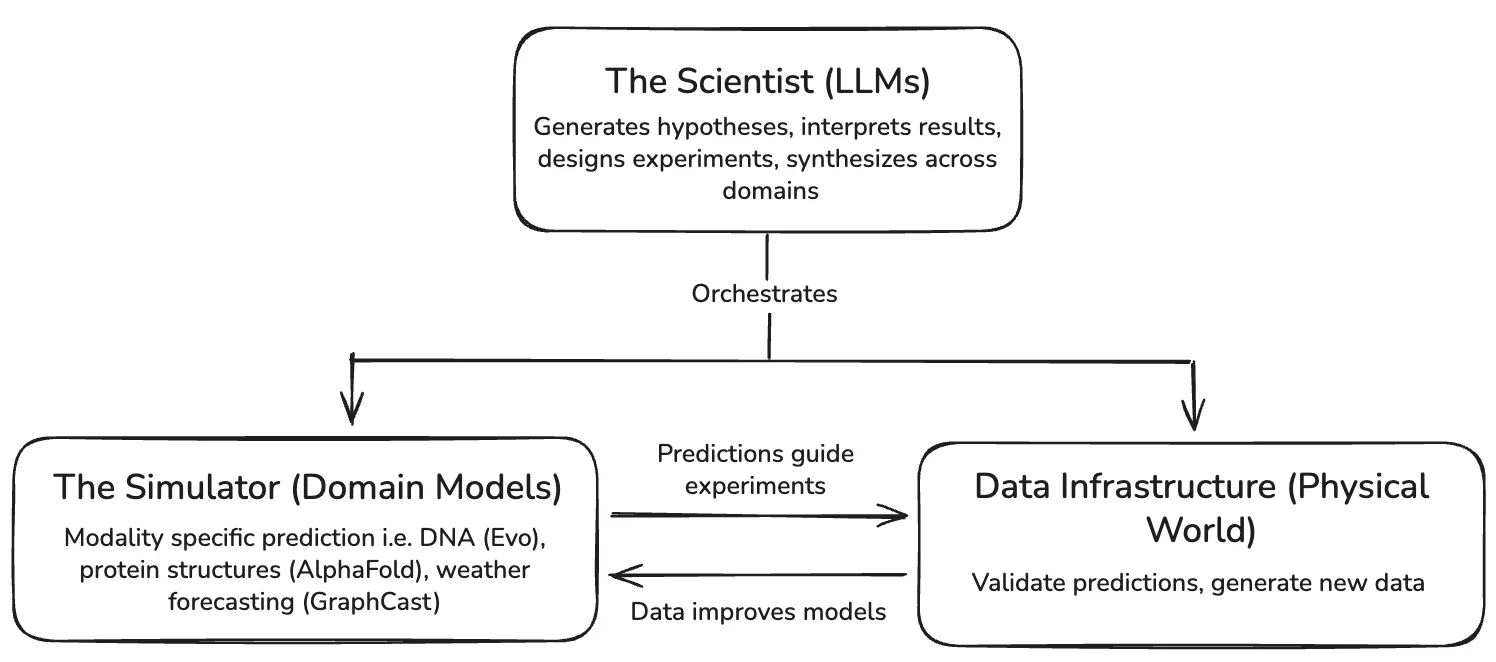
과학자(LLM)와 시뮬레이터(도메인 모델)는 ML 연구 내에서 서로 다른 인재 풀과 데이터 인프라를 필요로 하는 별개의 프로그램이며, 세계에 대한 일관된 모델을 만들기 위해 반드시 함께 작동해야 합니다. AI 기반 과학적 발견을 위한 전체 스택은 다음과 같습니다:
과학자를 가속하고(궁극적으로는 대체할) LLM의 잠재력은 아무리 강조해도 지나치지 않습니다. OpenAI는 최근 ChatGPT를 습식 실험실(wet lab) 루프에 연결하여 분자 클로닝 프로토콜을 가속할 수 있음을 보여주는 블로그 포스트를 발표했습니다. Anthropic은 Claude를 PubMed(논문 저장소), Benchling(실험 추적), 10x Genomics(단일 세포 및 공간 분석) 같은 기존 플랫폼과 통합한 생명과학자를 위한 기능 모음을 출시했습니다.
이러한 통합은 LLM에 실세계 작업을 수행할 수 있는 도구를 부여하는 사례로, 에이전트 부상의 근간이 되는 테제와 정확히 일치합니다. OpenAI와 Anthropic이 챗봇에 습식 실험실 실험을 수행하고 기존 데이터 플랫폼에 접근할 수 있는 ‘손’을 달아주었지만, 지난 2년간 검색(Exa, Perplexity), 문서 처리(Reducto), 브라우저 사용(BrowserBase) 등을 위한 블랙박스 도구들이 급부상했으며, 이들은 사실 인간보다 에이전트 사용에 더 특화되어 있다고 할 수 있습니다.
LLM이 과학적 발견에 효과적이려면 소프트웨어를 넘어서는 블랙박스 도구가 필요합니다. 과학자들이 물리적 시스템을 측정할 수 있는 추상화—자동화된 실험실, 프로그래밍 가능한 현장 모니터링 시스템 등(데이터 인프라)—가 필요합니다. 또한 물리적 시스템의 거동을 이해하고 예측하기 위한 블랙박스—언어만으로는 포착할 수 없는 세계에 대한 충실도를 제공하는 것(시뮬레이터)—도 필요합니다.
• • •
물리학은 단순하고, 생물학은 복잡하다
시뮬레이터는 왜 가치 있을까요? 우리 정의에 따르면, 과학자와 시뮬레이터의 핵심적 차이는 텍스트와 추론에 대한 의존 대 도메인 특화 파운데이션 모델에 대한 의존입니다. 어떤 도메인이 연쇄적 사고(chain-of-thought) 추론을 뒷받침할 만큼 충분한 이론적 구조를 갖추고 있으면 추론만으로 충분하지만, 이론이 부족할 때는 데이터로부터 직접 학습하는 모델이 필요합니다. 이 전환이 언제 일어나는지에 대한 질문은 과학적 모델링의 핵심에 자리한 더 깊은 긴장을 가리킵니다: 이론과 제일원리로부터 예측을 도출할 수 있는 건 언제이고, 경험적 데이터로부터 패턴을 매칭하는 모델을 구축해야 하는 건 언제인가?
실리콘밸리는 “제일원리 사고”를 사랑하고, 공교롭게도 학계도 마찬가지입니다. 모든 것은 제일원리로부터 도출 가능합니다. 화학은 물리학에서, 생물학은 화학에서, 인지는 생물학에서 창발합니다. 근본 법칙을 인코딩하고 충분한 연산을 적용하면 모든 것이 시뮬레이션 가능합니다.
맞는 말입니다! 하지만 안타깝게도 시뮬레이션에 기대하는 만큼 도움이 되진 않습니다. 모든 것이 원자이긴 하지만, 원자를 모델링하는 건 금방 계산적으로 난해해집니다:
- 양자물리학의 방정식은 전자의 상호작용을 정의하지만, 우리 컴퓨터로는 수십 개 원자 수준에서만 풀 수 있습니다.
- 한 단계 위인 밀도범함수론(DFT)은 전자 구름에 대한 근사로, 수백 개 원자까지 확장됩니다.
- 그다음에는 전자 상호작용을 완전히 힘장(force field)으로 대체합니다—고전 분자동역학의 기초—이것으로 수백만 개 원자에 도달합니다…
복잡성의 벽에 부딪힐 때마다 우리는 시스템을 측정하는 새로운 방법과 이를 추론할 수 있게 해주는 새로운 추상화와 규칙을 개발해왔습니다. 규칙 기반 시뮬레이션은 수많은 초기 성공을 가져다 주었습니다. 수치기상예측은 오로지 유체역학에 의존하여 신뢰할 수 있는 예보를 1일에서 7일로 연장했습니다. 모든 칩의 모든 트랜지스터는 제조 전에 맥스웰 방정식으로 시뮬레이션됩니다.
그러나 이론 기반 시뮬레이션은 시스템이 우아한 압축을 허용할 때만 작동합니다. 물리학은 기체의 거동을 예측하기 위해 10²⁵개의 개별 분자를 추적할 필요가 없다는 것을 발견했습니다—온도와 압력이면 충분합니다. 소수의 힘과 대칭만으로 기체의 성질, 행성의 운동, 회로의 거동을 매개변수화할 수 있습니다.
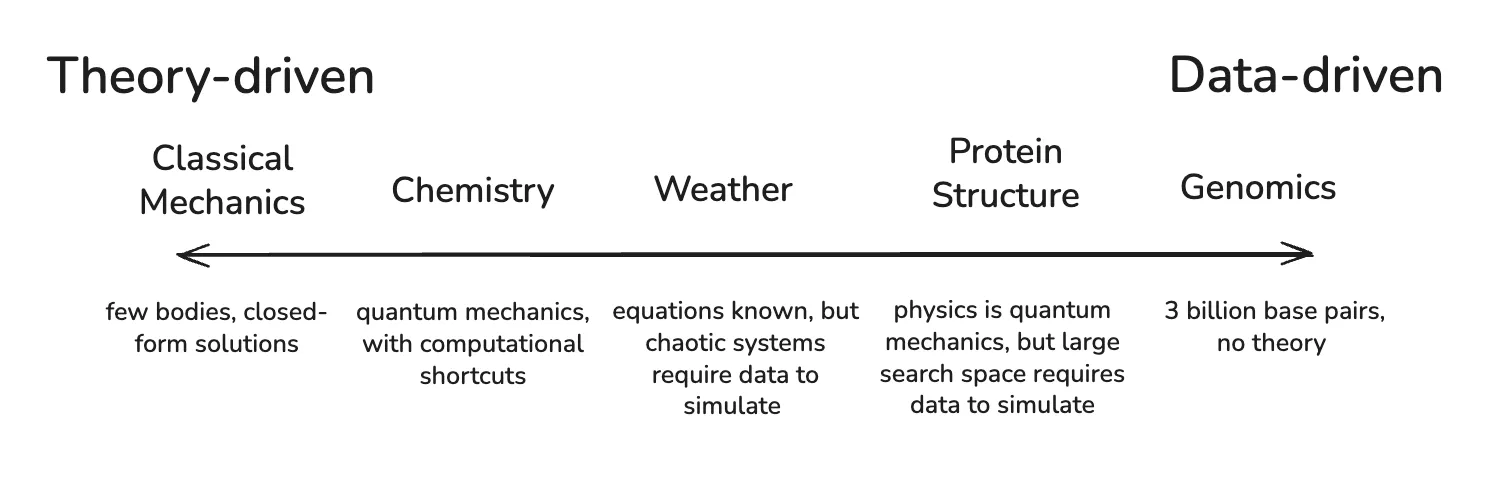
하지만 생물학에서는 그렇지 않습니다. 적어도 아직은 동등한 매개변수 목록을 찾지 못했습니다. 유전체는 복잡한 조절 로직을 가진 30억 개의 염기쌍입니다. 발현 패턴은 세포 주기, 조직 유형, 국소 화학 환경에 따라 변합니다. 일반적인 인간 세포에는 약 100억 개의 단백질 분자가 있으며, 13만에서 65만 종의 서로 다른 단백질-단백질 상호작용에 관여합니다. 그리고 기체 분자와 달리, 분자의 특정 정체성이 중요합니다. 특정 전사인자, DNA 영역, 분자, 그리고 이들 간의 상호작용이 세포가 암이 될지 여부를 결정할 수 있습니다. 미시적 세부 사항을 평균화해서 없앨 수가 없는 것입니다.
생물학은 유전학, 중심 원리(Central Dogma), 진화 같은 이론을 수용해왔지만, 이것들은 기술적(descriptive)이며, 예측 엔진을 구동할 수 있는 계산적 정밀도가 부족합니다. 따라서 생물학은 전통적으로 끝없는 사실의 축적이라는 따분한 암기 연습으로 가르쳐져 왔으며, 추론이나 연산을 수행할 수 있는 통합 프레임워크는 극히 드뭅니다.
언어 이론 개발에 경력을 바친 언어학자 촘스키는 이론주의자가 어떻게 실패할 수 있는지를 보여주는 대표적 사례입니다. 그는 ChatGPT 기반 기술을 비판하며 인간의 마음은 “수백 테라바이트의 데이터를 게걸스럽게 먹어치우는 둔중한 통계적 패턴 매칭 엔진이 아니다”라고 썼습니다. 그럴지도 모릅니다. 하지만 어쩌면 우주가 우리에게 해석 가능한 법칙을 보장하지는 않으니까요(그리고 결국 우리도 대단한 패턴 매칭 기계일 뿐이고요).

소박한 신경망이 얼마나 멀리 왔는지는 제대로 인정받지 못하고 있습니다. 1960년대 초기 이론적 비판 이후 신경망 접근법은 거의 20년간 외면당했고, 기계학습 연구를 하는 사람은 과학적 막다른 길을 쫓는 농담거리로 치부되었습니다.
“폭풍 같은 대학원 시절이었습니다. 매주 우리는 고함을 치며 논쟁했죠. 저는 계속 협상을 했어요. ‘좋아요, 6개월만 더 신경망을 연구하게 해주시면 작동한다는 걸 증명해 보이겠습니다.’ 6개월이 끝나면 저는 이렇게 말하곤 했죠. ‘네, 하지만 거의 다 됐어요. 6개월만 더 주세요.’”
— Geoffrey Hinton, “AI의 대부”
전환점은 2012년에 왔습니다. 이미지 분류 모델인 AlexNet이 ImageNet3 벤치마크에서 우승하여, 신경망도 확장 가능하다는 것을 더 넓은 ML 커뮤니티에 증명한 것입니다. LLM은 그보다 더 경이로운 성공 사례로 뒤이어 등장했고, 데이터 기반 학습 시뮬레이터의 필요성을 예증하며 트랜스포머 아키텍처에 마땅한 찬사를 안겨주었습니다.
어텐션이 전부는 아니다
스케일링 법칙은 과학 도메인의 모델링도 변혁시켰습니다—학습된 시뮬레이터가 기존 물리 기반 방법을 정확도와 속도 양면에서 능가하고 있습니다:
- 기상예보는 50년 넘게 수치기상예측(NWP)에 의존했습니다—대기 역학을 시뮬레이션하는 물리 기반 모델이었죠. 유럽중기예보센터(ECMWF)가 이를 골드 스탠다드로 다듬었고, 그 모델은 weather.com, 각국 기상청, 구글 웨더의 근간이 되었습니다.
- 2023년 Google DeepMind의 GraphCast(그래프 신경망)가 단일 TPU에서 1분 미만으로 10일 예보를 생성하면서 ECMWF의 정확도를 넘어섰습니다. 전통적 방법이 슈퍼컴퓨터에서 수 시간이 걸리던 것과 비교됩니다.
- 단백질 구조 예측도 유사한 이야기입니다. 2021년에 만들어진 AlphaFold2는 아미노산 서열을 구조에 직접 매핑하며, 다중 서열 정렬에 인코딩된 진화적 역사의 통찰을 활용합니다. 이후 알려진 모든 서열을 아우르는 2억 개 이상의 단백질 구조를 예측했습니다.
- 재료 발견은 DeepMind의 GNoME(Graph Networks for Materials Exploration)가 220만 개의 새로운 결정 구조를 발견했을 때 혁명을 맞이했습니다. 이전에는 전통적 실험적 발견으로 약 800년이 걸렸을 양입니다.
분명히 하자면, 이 성공들 중 어느 것도 원시 데이터 관찰만으로 이루어진 것이 아닙니다. GraphCast는 50년간의 물리 기반 기상 모델링 결과물로 훈련되었습니다. AlphaFold의 정렬은 진화적 제약을 생물학적 사전확률(prior)로 인코딩합니다. GNoME의 능동 학습 루프는 밀도범함수론(DFT)을 정답 오라클로 사용합니다. 모든 경우에서 ML은 기존 과학적 지식을 근사하거나 가속하는 법을 배웠고, 이론이 먼저였습니다. 더구나 이러한 대안적 ML 접근법의 진보가 ChatGPT를 이끈 ML 발전—트랜스포머 아키텍처와 그 유산—과 반드시 묶여 있는 것도 아닙니다. GraphCast는 그래프 신경망입니다. 상태 공간 모델을 포함한 하이브리드 아키텍처가 대규모 DNA 모델링에 가장 효과적이라는 연구도 있습니다. 서로 다른 도메인은 언어와 다른 귀납적 편향(inductive bias)과 데이터 구조를 가질 수 있습니다.
요약: ChatGPT 출시와 Epoch4 평가는 화려한 경마이지만, 투자해야 할 유일한 경주는 확실히 아닙니다. 프론티어 랩들이(DeepMind 외에) 아직 투자하지 않은 방대한 롱테일 ML 문제들이 있습니다.
물리적 세계의 종속
생물학은 아마도 시뮬레이터가 가장 필요하면서도 가장 덜 발전한 분야일 것입니다. 다른 도메인에서 데이터 접근성은 대체로 해결된 문제입니다. 기상학에는 ERA5 재분석 데이터가 있었습니다—수십 년에 걸친 전지구 대기 관측 데이터가 동화되고, 품질이 통제되어, 공개되어 있습니다. 재료과학의 훈련 데이터는 대부분 DFT 계산에서 나오는데, 비용은 높지만 자동화가 가능합니다.
하지만 생물학 실험실(wet lab) 데이터는 느리고, 노이즈가 많고, 비싸고, 종종 독점적이며, 역사적으로 실제 임상에서의 유효성으로 이어지기가 거의 불가능했습니다. 세포주(cell line)는 인간에게 일어날 일을 신뢰성 있게 예측하지 못하고, 동물 모델은 끊임없이 실패합니다—쥐에서 효과가 있는 약물의 90% 이상이 인간 임상시험에서 실패합니다. 단일 실험이 수개월에 걸쳐 수백만 달러가 들 수 있습니다. 시퀀싱은 저렴해졌지만, 시퀀싱은 하나의 양식(modality)에 불과합니다. 서열로부터 유전자 발현을 예측하는 것은 어렵습니다. 구조로부터 단백질 기능을 예측하는 것은 어렵습니다. 분자 상호작용으로부터 약물 효능을 예측하는 것은 매우 어렵습니다. 수집해야 할 올바른 데이터가 어떤 모습인지조차 모른다고 할 수 있습니다.
Noetik은 다중 단백질 염색, 공간적 유전자 발현, DNA 시퀀싱, 구조적 마커로 암 월드 모델을 훈련하는 다중양식(multimodal) 접근법으로 차별화를 이루었습니다. Biohub는 개별 단백질부터 전체 유기체에 이르기까지 다양한 규모의 측정 도구를 구축하기 위해 경쟁하고 있습니다. 복수의 양식에 걸쳐 복수의 모델을 위한 데이터를 생성하는 것—이것은 전략이 없다는 전략입니다(그리고 이는 생물학 분야 전체에 적용됩니다).
생물학에 대한 종합적 이론이 계속 우리를 피해갈 가능성도 있습니다. 만약 그렇다면, 진보는 물리학보다는 공학에 가까운 모습이 될 것입니다—특정 질병, 특정 장기, 특정 양식에 대한 좁은 집중. 그 작업은 화려하지 않고 시간은 길 것입니다. 우리는 여전히 물리적 세계에 종속되어 있습니다.
AGI AI for Science 타임라인
그렇다면 LLM이 알아서 해결해줄 때까지 기다리면 되지 않을까요? 대형 랩들이 ML 연구를 위한 AI 과학자 구축에 직접 노력을 투자했다는 믿을 만한 증거가 있으며, 이는 재귀적 자기 개선으로 가는 잠재적 경로입니다. 하지만 LLM이 정확한 시뮬레이터를 구축하거나 크게 가속한다고 해도, 과학자와 시뮬레이터 시스템은 기술적 기반, 데이터 요구 사항, 배포 타임라인 측면에서 여전히 구분 가능하며, 이는 투자와 정책에 실질적 영향을 미칩니다. GPT-7이 인간 생물학을 시뮬레이션하는 디지털 트윈을 설계할 인지적 역량을 충분히 가질 수 있습니다. 하지만 그것이 가능해지는 건, 이미 효과적인 시뮬레이터의 알고리즘을 발전시키고 자동화된 데이터 인프라를 구축해온 수많은 플레이어들 덕분입니다. 월드 모델, 음성, 이미지 생성을 위한 ML이 ElevenLabs, Midjourney, WorldLabs 등에 의해 추진된 것처럼, 과학을 위한 ML도 복수의 노력에 의해 추진될 것으로 기대해야 합니다.
과학자(추론과 종합을 위한 LLM)는 프론티어 랩들이 구축하고 있습니다.
시뮬레이터(도메인 특화 ML 모델)는 특수화된 아키텍처와 도메인 전문성이 필요합니다. DeepMind가 인상적인 작업을 해왔지만, 이것이 그들의 핵심 사업은 아닙니다.
데이터 인프라(자동화된 실험실, 고처리량 분석, 시뮬레이션 파이프라인)는 자본 집약적인 물리적 시설과 수년간의 반복이 필요합니다.
이미 이 AI 기반 과학적 발견 테제에 베팅하는 몇몇 기업이 있지만, 펀딩 환경은 여전히 메마릅니다. Flagship Pioneering이 지원하는 Lila Sciences는 “AI 과학 공장”—AI가 실험을 설계하고, 로봇이 실행하며, 결과가 직접 모델 훈련에 피드백되는 자동화된 실험실—을 구축하고 있습니다. 전 OpenAI 및 DeepMind 연구원들이 설립한 Periodic Labs는 AI 모델과 자동화된 합성을 결합하여 신소재를 만들고 있습니다.
Anthropic이 단백질 접힘 모델을 만들기 시작하지 않는 한, 그들이 질병을 해결해줄 거라 기대해서는 안 됩니다. OpenAI가 지리공간 모델을 만들기 시작하지 않는 한, 그들이 최첨단 기상예보자가 될 거라 기대해서는 안 됩니다. 대형 랩들은 지능—추론, 긴 컨텍스트, 도구 사용—에 집중하고 있습니다. 도메인 특화 시뮬레이션과 데이터 수집은 그들의 핵심 역량과 비즈니스 모델 밖에 있는 대규모 사업입니다.
담론은 AGI 타임라인과 과학자의 추론 능력에 집중되어 있습니다. 질병을 치료하고 신소재를 발견할 작업은 더 구체적이고, 더 다원적이며, 물리적 세계에 의해 더 많이 제약받습니다.
• • •
역자 주
- 확률적 앵무새(Stochastic Parrots): Emily Bender 등이 2021년 발표한 논문 “On the Dangers of Stochastic Parrots”에서 유래한 표현. LLM이 실제로 언어를 이해하는 것이 아니라 통계적 패턴을 반복할 뿐이라는 비판적 시각을 담고 있다. ↩
- Machines of Loving Grace: 리처드 브라우티건(Richard Brautigan)의 1967년 시 “All Watched Over by Machines of Loving Grace”에서 따온 제목. 기술이 자연과 조화를 이루는 유토피아를 꿈꾸는 시로, Dario가 AI의 긍정적 가능성을 논할 때 의도적으로 이 제목을 차용했다. ↩
- ImageNet: 2009년 스탠포드 대학의 Fei-Fei Li 교수가 주도해 만든 대규모 이미지 데이터셋이자 연례 분류 대회. 2012년 Alex Krizhevsky의 CNN 모델 ‘AlexNet’이 기존 방법을 압도적으로 이기면서 딥러닝 혁명의 시발점이 되었다. ↩
- Epoch: AI 발전 추세를 추적하고 분석하는 연구 기관 Epoch AI를 가리킨다. AI 모델의 학습 연산량, 데이터셋 크기, 벤치마크 성능 등을 체계적으로 평가해 업계의 주요 참고 자료로 활용된다. ↩
저자 소개: Melissa Du는 Radical Numerics의 연구 엔지니어이며, X와 Substack에서 활동하고 있습니다.
참고: 이 글은 Melissa Du가 Latent Space에 게시한 에세이를 번역한 것입니다.
원문: The Scientist and the Simulator - Melissa Du, Latent Space (2026년 2월 11일)
생성: Claude (Anthropic)