소셜 파일시스템
게시일: 2026년 1월 20일 | 원문 작성일: 2026년 1월 18일 | 저자: Dan Abramov | 원문 보기
핵심 요약
AT Protocol의 핵심 개념을 파일시스템 비유로 설명하는 심층 기술 글입니다.
- 파일 패러다임 — 개인 컴퓨팅에서 파일이 앱과 독립적인 것처럼, 소셜 데이터도 앱에서 독립할 수 있어요
- 레코드와 컬렉션 — AT Protocol에서 모든 소셜 데이터는 JSON 레코드로 표현되고, 렉시콘으로 정의된 컬렉션에 저장돼요
- DID와 영구 링크 — 호스팅이나 핸들이 바뀌어도 깨지지 않는 영구적인 식별자 시스템이에요
- 분산형 생태계 — 앱이 데이터를 가두지 않고, 누구나 같은 데이터로 새로운 앱을 만들 수 있어요
• • •
파일을 기억하시나요?
문서를 작성하고, 저장 버튼을 누르면, 파일이 컴퓨터에 저장돼요. 그건 당신 것이에요. 직접 살펴볼 수 있고, 친구에게 보낼 수 있고, 다른 앱으로 열 수 있어요.
파일은 개인 컴퓨팅 패러다임에서 온 것이에요.
하지만 이 글은 개인 컴퓨팅에 대한 이야기가 아니에요. 제가 이야기하고 싶은 건 소셜 컴퓨팅—Instagram, Reddit, Tumblr, GitHub, TikTok 같은 앱들이에요.
파일과 소셜 컴퓨팅이 무슨 관계가 있을까요?
역사적으로는 별로 없었어요—최근까지는요.
하지만 먼저, 파일에 대한 찬사부터 해볼게요.
파일이 대단한 이유
원래 발명된 의도대로라면, 파일은 앱 안에 살도록 만들어진 게 아니에요.
파일은 당신의 창작물을 나타내니까, 당신이 통제하는 어딘가에 있어야 해요. 앱은 당신을 대신해서 파일을 만들고 읽지만, 파일이 앱에 속하는 건 아니에요.
파일은 당신—그 앱들을 사용하는 사람—의 것이에요.
앱(과 그 개발자들)이 당신의 파일을 소유하지는 않지만, 읽고 쓸 수 있어야 해요. 그걸 안정적으로 하려면, 앱은 파일이 구조화되어 있어야 해요. 그래서 앱 개발자들은 앱을 만들면서 파일 포맷을 발명하고 발전시켜요.
파일 포맷은 언어 같은 거예요. 앱은 여러 포맷을 “말할” 수 있어요. 하나의 포맷은 여러 앱이 이해할 수 있어요. 앱과 포맷은 다대다 관계예요. 파일 포맷 덕분에 서로 다른 앱들이 서로 몰라도 함께 작동할 수 있어요.
이 .svg 파일을 생각해보세요:
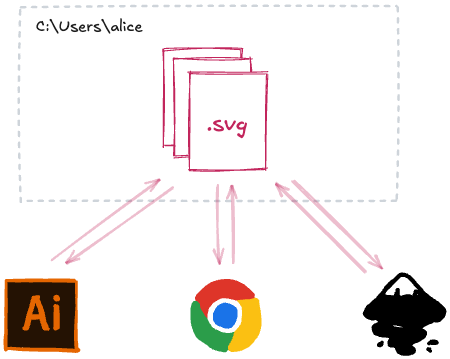
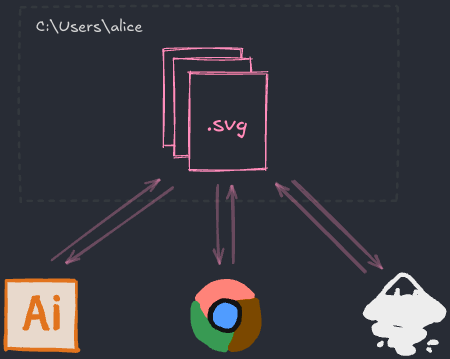
SVG는 공개 명세예요. 이건 다양한 개발자들이 SVG를 읽고 쓰는 방법에 동의했다는 뜻이에요. 저는 이 SVG 파일을 Excalidraw[1]에서 만들었지만, Adobe Illustrator나 Inkscape를 대신 쓸 수도 있었어요. 브라우저는 이미 이 SVG를 표시하는 방법을 알고 있었어요. Excalidraw API를 호출하거나 Excalidraw에게 허락을 구할 필요가 없었어요. 어떤 앱이 이 SVG를 만들었는지는 중요하지 않아요.
파일 포맷이 곧 API예요.
물론, 모든 파일 포맷이 공개되거나 문서화된 건 아니에요.
어떤 파일 포맷은 .doc처럼 특정 애플리케이션 전용이거나 심지어 독점적이에요. 그래도 .doc이 문서화되지 않았다고 해서, 의욕적인 개발자들이 리버스 엔지니어링해서 .doc을 읽고 쓰는 소프트웨어를 더 많이 만드는 걸 막지는 못했어요:
파일 패러다임의 또 다른 승리예요.
파일 패러다임은 도구에 대한 현실 세계의 직관을 포착해요: 도구로 만든 것은 그 도구에 속하지 않는다는 거예요. 원고는 타자기 안에 머물지 않고, 사진은 카메라 안에 머물지 않고, 노래는 마이크에 머물지 않아요.
우리의 기억, 생각, 디자인은 그것들을 만드는 데 사용한 소프트웨어보다 오래 살아남아야 해요. 앱에 구애받지 않는 저장소(파일시스템)가 이 분리를 강제해요.
어떤 의미에서, 파일은 여러 삶을 살아요.
한 앱에서 파일을 만들 수 있지만, 다른 사람이 다른 앱으로 그걸 읽을 수 있어요. 사용하는 앱을 바꾸거나, 함께 사용할 수 있어요. 파일을 한 포맷에서 다른 포맷으로 변환할 수 있어요. 두 앱이 같은 파일 포맷을 올바르게 “말”하기만 하면, 개발자들이 서로 싫어해도 함께 작동할 수 있어요.
그리고 앱이 별로면?
누군가 당신이 이미 가진 파일들을 위한 “다음 앱”을 항상 만들 수 있어요:
앱은 오고 가도, 파일은 남아요—적어도 앱이 파일 단위로 생각하는 한은요.
”모든 것” 폴더
소셜 앱—Instagram, Reddit, Tumblr, GitHub, TikTok—을 생각하면, 아마 파일은 떠오르지 않을 거예요. 파일은 개인 컴퓨팅에만 해당되잖아요, 그렇죠?
Tumblr 포스트는 파일이 아니에요.
Instagram 팔로우는 파일이 아니에요.
Hacker News[2] 업보트는 파일이 아니에요.
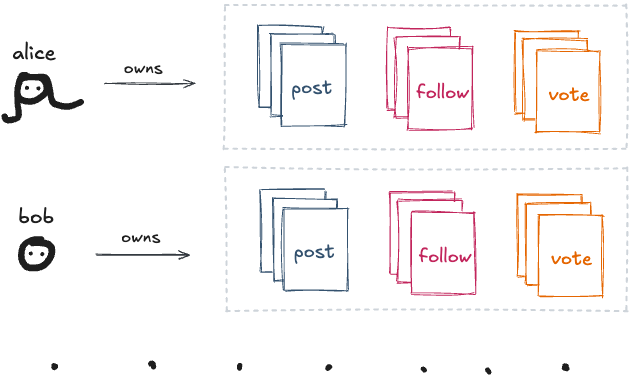
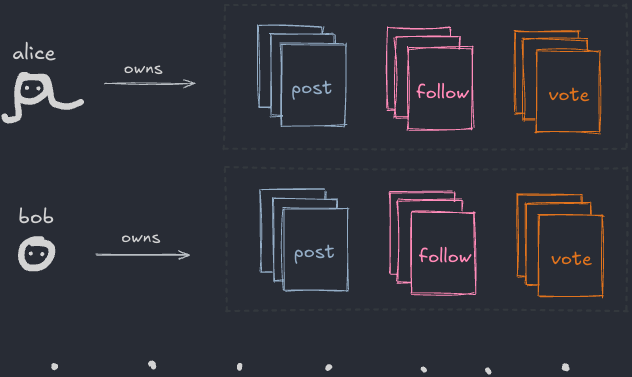
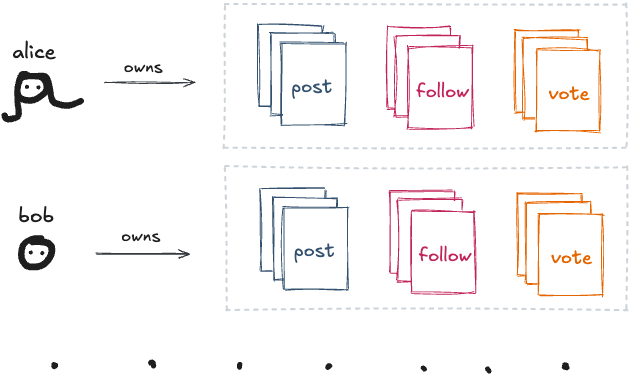
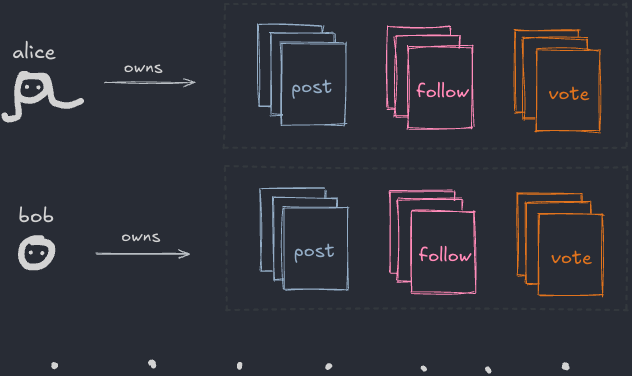
하지만 그것들이 파일처럼 행동한다면—적어도 중요한 모든 면에서? 당신의 온라인 페르소나가 게시한 모든 것을 담은 폴더가 있다고 가정해보세요:
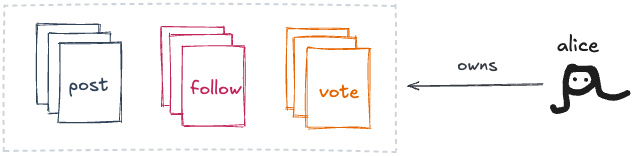
다양한 소셜 앱에서 만든 모든 것—포스트, 좋아요, 스크로블[3], 레시피 등—을 포함할 거예요. 이걸 “모든 것 폴더”라고 부를 수 있을 거예요.
물론, Instagram 같은 폐쇄적인 앱은 이렇게 만들어지지 않았어요. 하지만 그랬다고 상상해보세요. 그 세계에서 “Tumblr 포스트”나 “Instagram 팔로우”는 소셜 파일 포맷이에요:
이 폴더는 어떤 종류의 아카이브가 아니라는 점에 주목하세요. 당신의 데이터가 실제로 사는 곳이에요:
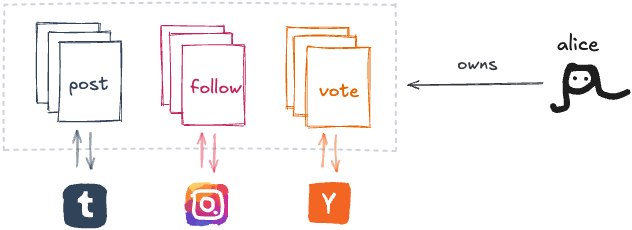
파일이 진실의 원천이에요—앱은 폴더에 있는 것을 반영할 뿐이에요.
폴더에 쓰는 모든 것이 관심 있는 앱에 동기화돼요. 예를 들어, “Instagram 팔로우” 파일을 삭제하면 앱에서 언팔로우하는 것과 똑같이 작동해요. 세 개의 Tumblr 커뮤니티에 크로스포스팅하는 건 세 개의 “Tumblr 포스트” 파일을 만들어서 할 수 있어요. 내부적으로, 각 앱이 당신의 폴더에 있는 파일을 관리해요.
이 패러다임에서, 앱은 파일에 반응적이에요. 모든 앱의 데이터베이스는 대부분 파생 데이터가 돼요—모든 사람의 폴더에 대한 앱 특화 캐시된 구체화 뷰[4]예요.
소셜 파일시스템
이게 매우 가설적으로 들릴 수 있지만, 그렇지 않아요. 지금까지 설명한 건 AT Protocol의 전제예요. 대규모 프로덕션 환경에서 잘 작동해요. Bluesky, Leaflet, Tangled, Semble, Wisp가 이런 방식으로 만들어진 새로운 오픈 소셜 앱들 중 일부예요.
그 앱들을 사용하는 느낌은 다르지 않아요. 하지만 사용자 데이터를 앱 밖으로 끌어올림으로써, 개인 컴퓨팅에서 가졌던 것과 같은 분리를 강제해요: 앱이 당신이 만든 것을 가두지 않아요. 누군가 항상 오래된 데이터를 위한 새 앱을 만들 수 있어요:
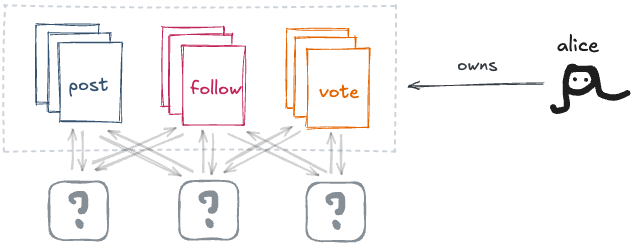
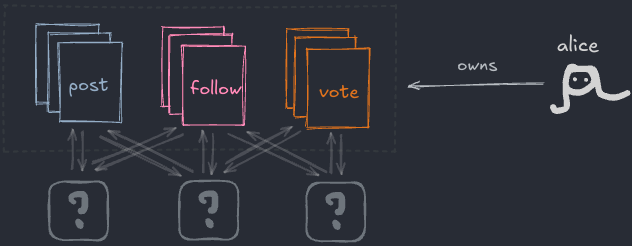
전처럼, 앱 개발자들이 파일 포맷을 발전시켜요. 하지만 그 포맷의 파일을 읽고 쓰는 사람을 게이트키핑할 수 없어요. 어떤 앱을 쓸지는 당신이 정해요.
모든 사람의 폴더가 모이면 분산형 소셜 파일시스템 같은 게 돼요:
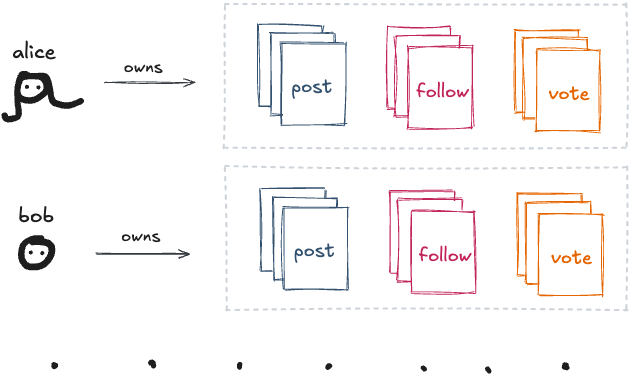
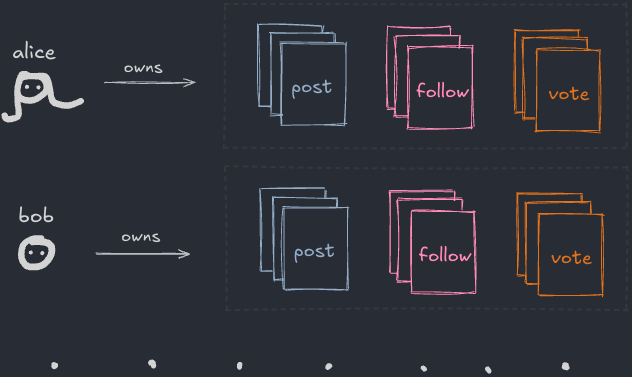
저는 이전에 Open Social에서 AT Protocol에 대해 웹 중심적 관점으로 썼어요. 하지만 파일시스템 관점에서 보는 것도 똑같이 흥미롭다고 생각해서, 어떻게 작동하는지 투어를 해보도록 초대할게요.
개인 파일시스템은 파일에서 시작해요.
소셜 파일시스템은 뭐에서 시작할까요?
레코드
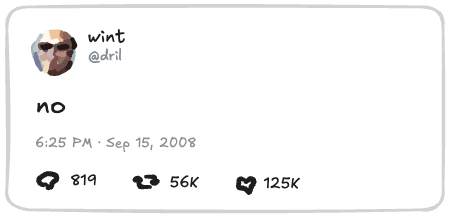
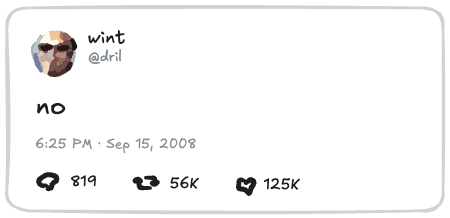
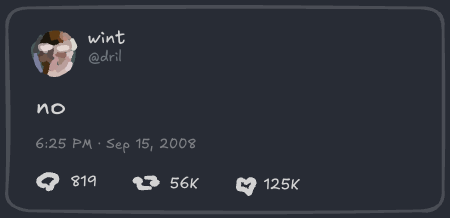
여기 전형적인 소셜 미디어 포스트가 있어요:
이걸 파일로 어떻게 표현할까요?
포맷으로 JSON을 고려하는 게 자연스러워요. 결국, API를 만든다면 반환할 거잖아요. 그러니 이 포스트를 JSON으로 완전히 설명해볼게요:
{
author: {
avatar: 'https://example.com/dril.jpg',
displayName: 'wint',
handle: 'dril'
},
text: 'no',
createdAt: '2008-09-15T17:25:00.000Z',
replyCount: 819,
repostCount: 56137,
likeCount: 125381
}하지만 이 포스트를 파일로 저장하고 싶다면, 저자 정보를 거기에 임베드하는 건 말이 안 돼요. 결국, 저자가 나중에 표시 이름이나 아바타를 바꾸면, 모든 포스트를 돌아다니면서 바꾸고 싶지 않을 테니까요.
그러니 아바타와 이름이 다른 곳에—아마 다른 파일에—산다고 가정해요. JSON에 author: ‘dril’을 남겨둘 수 있지만 이것도 불필요해요. 이 파일이 만든 사람의 폴더 안에 있으니까—그들의 포스트니까요—현재 보고 있는 폴더가 누구 것인지로 항상 저자를 알아낼 수 있어요.
저자 필드를 완전히 제거해볼게요:
{
text: 'no',
createdAt: '2008-09-15T17:25:00.000Z',
replyCount: 819,
repostCount: 56137,
likeCount: 125381
}이건 이 포스트를 설명하는 좋은 방법 같아요:
하지만 잠깐, 아니, 이건 아직 틀렸어요.
보세요, replyCount, repostCount, likeCount는 포스트 작성자가 만든 게 아니에요. 이 값들은 다른 사람들이 만든 데이터—그들의 답글, 리포스트, 좋아요—에서 파생돼요. 이 포스트를 표시하는 앱이 그것들을 어떻게든 추적해야 하지만, 이 사용자의 데이터는 아니에요.
그래서 실제로 남는 건 이것뿐이에요:
{
text: 'no',
createdAt: '2008-09-15T17:25:00.000Z'
}이게 파일로서의 우리 포스트예요!
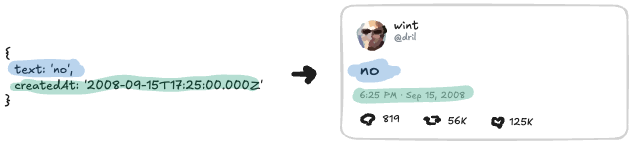
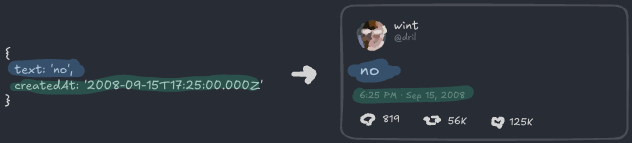
데이터의 어떤 부분이 실제로 이 레코드에 속하는지 식별하려면 어느 정도 다듬기가 필요했다는 걸 알아두세요. 이건 AT Protocol로 앱을 만들 때 의도적으로 해야 하는 것이에요. 이것에 대한 제 멘탈 모델은 POST 요청을 생각하는 거예요. 사용자가 이것을 만들 때, 어떤 데이터를 보냈나요? 그게 아마 저장하고 싶은 것에 가까울 거예요. 그게 사용자가 방금 만든 것이에요.
우리 소셜 파일시스템은 전통적인 파일시스템보다 더 엄격하게 구조화될 거예요. 예를 들어, JSON 파일만으로 구성될 거예요. 이걸 더 명시적으로 만들기 위해, 새로운 용어를 도입하기 시작할게요. 이런 종류의 파일을 레코드라고 부를게요.
레코드 키
이제 레코드에 이름을 줘야 해요. 포스트에는 자연스러운 이름이 없어요. 순차 번호를 쓸 수 있을까요? 이름은 폴더 안에서만 유일하면 돼요:
posts/
├── 1.json
├── 2.json
└── 3.json한 가지 단점은 최신 것을 추적해야 해서 여러 기기에서 동시에 많은 파일을 만들 때 충돌 위험이 있다는 거예요.
대신, 시계별 랜덤성을 섞은 타임스탬프를 사용해요:
posts/
├── 1221499500000000-c5.json
├── 1221499500000000-k3.json # clock id로 전역 충돌 방지
└── 1221499500000001-k3.json # 인공적 +1로 로컬 충돌 방지이게 더 좋아요. 로컬에서 생성할 수 있고 거의 절대 충돌하지 않을 테니까요.
이 이름들을 URL에서 쓸 거니까 더 간결하게 인코딩해요. 알파벳순 정렬이 시간순으로 가도록 인코딩을 신중하게 선택해요[5]:
posts/
├── 34qye3wows2c5.json
├── 34qye3wows2k3.json
└── 34qye3wows3k3.json이제 ls -r이 포스트의 역시간순 타임라인을 줘요! 멋지네요. 또한, JSON을 공용어로 쓰니까, 파일 확장자가 필요 없어요.
posts/
├── 34qye3wows2c5
├── 34qye3wows2k3
└── 34qye3wows3k3모든 레코드가 시간이 지나면서 쌓이는 건 아니에요. 예를 들어, 포스트는 많이 쓸 수 있지만, 프로필 정보—아바타와 표시 이름—의 사본은 하나뿐이에요. “싱글톤” 레코드에는 me나 self 같은 미리 정의된 이름을 쓰는 게 말이 돼요:
posts/
├── 34qye3wows2c5
├── 34qye3wows2k3
└── 34qye3wows3k3
profiles/
└── self참고로, 이 프로필 레코드를 profiles/self에 저장해볼게요:
{
avatar: 'https://example.com/dril.jpg",
displayName: 'wint'
}posts/34qye3wows2c5와 profiles/self를 함께 보면 처음 시작했던 UI의 더 많은 부분을 재구성할 수 있지만, 일부 부분은 아직 빠져 있어요:

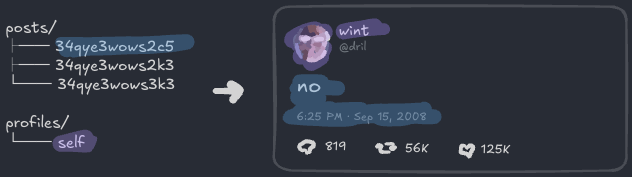
그것들을 채우기 전에, 시스템을 더 튼튼하게 만들어야 해요.
렉시콘
이게 포스트 레코드의 형태였어요:
{
text: 'no',
createdAt: '2008-09-15T17:25:00.000Z'
}그리고 이게 프로필 레코드의 형태였어요:
{
avatar: 'https://example.com/dril.jpg",
displayName: 'wint'
}이것들이 파일로 저장되니까, 포맷이 변하지 않는 게 중요해요.
타입 정의를 좀 써볼게요:
type Post = {
text: string,
createdAt: string
};
type Profile = {
avatar?: string,
displayName?: string
};TypeScript가 이것에 편리해 보이지만 충분하지 않아요. 예를 들어, “text 문자열은 최대 300개의 유니코드 그래핌이어야 한다”거나 “createdAt 문자열은 datetime으로 포맷되어야 한다” 같은 제약을 표현할 수 없어요.
소셜 파일 포맷을 정의하는 더 풍부한 방법이 필요해요.
기존 옵션(RDF? JSON Schema?)[6]을 찾아볼 수 있지만 딱 맞는 게 없으면, 소셜 파일시스템의 필요에 명시적으로 맞춘 우리만의 스키마 언어를 설계해도 돼요. 짜잔! Post가 이렇게 생겼어요:
{
// ...
"defs": {
"main": {
"type": "record",
"key": "tid",
"record": {
"type": "object",
"required": ["text", "createdAt"],
"properties": {
"text": { "type": "string", "maxGraphemes": 300 },
"createdAt": { "type": "string", "format": "datetime" }
}
}
}
}
}이걸 Post 렉시콘이라고 부를게요. 앱이 이제 말할 수 있는 언어 같은 거니까요.
제 첫 반응도 “으악”이었지만 개념적으로 이렇다고 생각하면 도움이 됐어요:
type Post = {
@maxGraphemes(300) text: string,
createdAt: datetime
};더 나은 구문을 갈망했었지만 실제로 JSON을 조심스럽게 감사하게 됐어요. 파싱하기가 정말 쉬워서 주변에 도구를 만들기 아주 쉬워요(끝에서 더 얘기할게요). 그리고 물론, 이것들을 어떤 프로그래밍 언어든 타입 정의와 검증 코드로 바꾸는 바인딩을 만들 수 있어요.
컬렉션
지금까지 소셜 파일시스템은 이렇게 생겼어요:
posts/
├── 34qye3wows2c5
├── 34qye3wows2k3
└── 34qye3wows3k3
profiles/
└── selfposts/ 폴더는 Post 렉시콘을 만족하는 레코드가 있고, profiles/ 폴더는 Profile 렉시콘을 만족하는 레코드(사실 단일 레코드)가 있어요.
이건 단일 앱에서 잘 작동하게 만들 수 있어요. 하지만 문제가 있어요. 다른 앱이 자체적인 “posts”와 “profiles” 개념을 가지고 있다면?
기억하세요, 각 사용자는 모든 앱의 데이터가 있는 “모든 것 폴더”를 가져요:
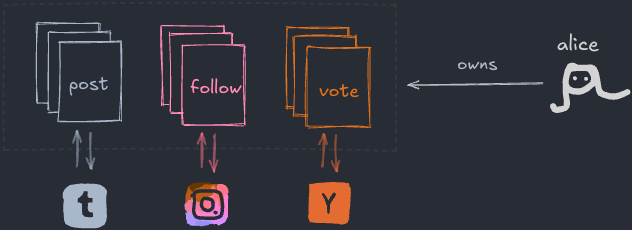
다른 앱들은 “포스트”의 포맷이 뭔지 아마 동의하지 않을 거예요! 예를 들어, 마이크로블로그 포스트는 300자 제한이 있을 수 있지만, 제대로 된 블로그 포스트는 그렇지 않을 수 있어요.
앱들이 서로 동의하게 할 수 있을까요?
모든 앱 개발자를 같은 방에 넣고 포스트에 대한 완벽한 렉시콘에 모두 동의할 때까지 기다려볼 수 있어요. 모두의 시간을 흥미롭게 쓰는 방법이겠네요.
크로스사이트 신디케이션 같은 일부 사용 사례에는 표준 같은 공동 관리 렉시콘이 말이 돼요. 다른 경우에는, 앱이 담당하기를 정말 원해요. 다른 제품들이 포스트가 뭔지 동의하지 않을 수 있는 게 실제로 좋아요! 다른 제품, 다른 느낌. 그걸 지원하고 싶지, 싸우고 싶지 않아요.
사실, 우리는 잘못된 질문을 하고 있었어요. 모든 앱 개발자가 포스트가 뭔지 동의할 필요가 없어요; 누구나 자신의 포스트를 “정의”할 수 있게 하면 돼요.
앱 이름으로 레코드 타입의 네임스페이스를 만들어볼 수 있어요:
twitter/
├── posts/
│ ├── 34qye3wows2c5
│ ├── 34qye3wows2k3
│ └── 34qye3wows3k3
└── profiles/
└── self
tumblr/
├── posts/
│ ├── 34qye3wows4c5
│ └── 34qye3wows5k3
└── profiles/
└── self하지만 앱 이름도 충돌할 수 있어요. 다행히, 충돌을 피하는 방법이 이미 있어요—도메인 이름. 도메인 이름은 유일하고 소유권을 암시해요.
Java에서 영감을 얻어볼까요?
com.twitter.post/
├── 34qye3wows2c5
├── 34qye3wows2k3
└── 34qye3wows3k3
com.twitter.profile/
└── self
com.tumblr.post/
├── 34qye3wows4c5
└── 34qye3wows5k3
com.tumblr.profile/
└── self이게 컬렉션이에요.
컬렉션은 특정 렉시콘 타입의 레코드가 있는 폴더예요. Twitter의 포스트 렉시콘은 Tumblr과 다를 수 있고, 괜찮아요—별개의 컬렉션에 있으니까요. 컬렉션은 항상 <렉시콘.설계하는.사람>.<이름> 형식으로 이름 지어요.
예를 들어, 이런 컬렉션 이름들을 상상할 수 있어요:
app.bsky.feed.postcom.tumblr.postapp.bsky.actor.profilecom.github.repository
좀 더 기발한 컬렉션 이름들도 상상할 수 있어요:
fm.teal.alpha.feed.playapp.sidetrail.walkio.overreacted.comment
컬렉션은 모든 파일 확장자마다 폴더가 있는 것 같아요.
실제 렉시콘 이름을 보고 싶다면, UFOs와 Lexicon Garden을 확인해보세요.
렉시콘 경찰은 없어요
애플리케이션 작성자라면, 이렇게 생각하고 있을 수 있어요:
레코드가 렉시콘과 일치하는지 누가 강제해요? 어떤 앱이든 (사용자의 명시적 동의로) 다른 앱의 컬렉션에 쓸 수 있다면, 어떻게 잘못된 데이터가 많이 생기지 않나요? 다른 앱이 “내” 컬렉션에 쓰레기를 넣으면?
답은 레코드가 쓰레기일 수 있지만, 어쨌든 잘 작동한다는 거예요.
파일 확장자와 비교하면 도움이 돼요. 누군가 cat.jpg를 cat.pdf로 이름 바꾸는 걸 막을 건 없어요. PDF 리더가 그냥 열기를 거부할 거예요.
렉시콘 검증도 같은 방식으로 작동해요. com.tumblr.post에서 com.tumblr은 렉시콘을 설계한 사람을 신호하지만, 레코드 자체는 어떤 앱에서든 만들어졌을 수 있어요. 그래서 앱은 항상 레코드를 POST 요청 본문처럼 신뢰할 수 없는 입력으로 취급해요. 렉시콘에서 타입 정의를 생성할 때, 검증을 해주는 함수도 얻어요. 어떤 레코드가 검사를 통과하면, 좋아요—타입이 지정된 객체를 얻어요. 그렇지 않으면, 괜찮아요, 그 레코드를 무시해요.
읽을 때 검증해요, 파일처럼요.
렉시콘을 발전시킬 때 주의가 필요해요. 렉시콘이 실제로 사용되는 순간부터, 어떤 레코드를 유효하다고 볼지 절대 바꾸면 안 돼요. 예를 들어, 새로운 선택적 필드를 추가할 수 있지만, 어떤 필드가 선택적인지는 바꿀 수 없어요. 이렇게 하면 새 코드가 여전히 오래된 레코드를 읽을 수 있고, 오래된 코드가 새 레코드를 읽을 수 있어요. 이걸 검사하는 린터가 있어요. (호환성을 깨는 변경은 파일 포맷처럼 새 렉시콘을 만들어요.)
필수는 아니지만, 문서화와 배포를 위해 렉시콘을 게시할 수 있어요. 타입 정의를 게시하는 것 같아요. 별도의 레지스트리는 없어요; 어떤 계정의 com.atproto.lexicon.schema 컬렉션에 넣고, 렉시콘의 도메인이 당신 것임을 증명하면 돼요. 예를 들어, io.overreacted.comment 렉시콘을 게시하고 싶다면, 여기에 둘 수 있어요:
app.bsky.feed.post/
├── 3mclfkzg4uc2k
├── 3mcleqsh7cc2k
└── 3mclejvlp5c2k
com.atproto.lexicon.schema
└── io.overreacted.comment그러고 나서 overreacted.io가 제 것임을 증명하기 위해 DNS 설정을 좀 해야 해요. 그러면 제 렉시콘이 pdsls, Lexicon Garden, 다른 도구들에 나타날 거예요.
링크
포스트로 다시 돌아가요.
프로필은 com.twitter.profile 컬렉션에 살고, 포스트 자체는 com.twitter.post 컬렉션에 살기로 이미 정했어요:

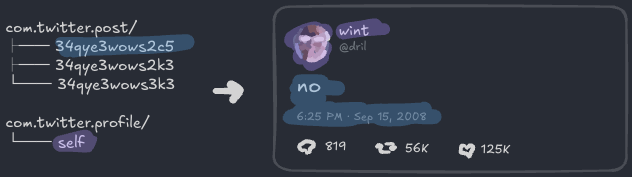
하지만 좋아요는요?
사실, 좋아요가 뭐예요?
좋아요는 사용자가 만드는 것이니까, 각 좋아요가 레코드인 게 말이 돼요. 좋아요 레코드는 어떤 포스트에 좋아요를 눌렀는지 외에 다른 데이터를 전달하지 않아요:
type Post = {
text: string,
createdAt: string
};
// ...
type Like = {
subject: Post
};TypeScript에서, 이걸 Post 타입에 대한 참조로 표현했어요. 렉시콘은 전역적으로 유일한 이름을 가진 JSON 파일이니까, 렉시콘에서 이렇게 말할 거예요:
{
"lexicon": 1,
"id": "com.twitter.like",
"defs": {
"main": {
"type": "record",
"key": "tid",
"record": {
"type": "object",
"required": ["subject"],
"properties": {
"subject": { "type": "ref", "ref": "com.twitter.post" }
}
}
}
}
}Like는 어떤 Post를 참조하는 subject 필드가 있는 객체라고 말하는 거예요.
하지만, “참조”가 많은 일을 하고 있어요. Like 레코드가 실제로 어떻게 생겼어요? 한 JSON 파일 안에서 다른 JSON 파일을 실제로 어떻게 참조해요?
{
subject: "???"
}”모든 것 폴더”에서 경로로 Post 레코드를 참조해볼 수 있어요:
{
subject: "com.twitter.post/34qye3wows2c5"
}하지만 이건 단일 사용자의 “모든 것 폴더” 안에서만 유일하게 식별해요. 기억하세요, 각 사용자는 자신의 모든 것이 있는 완전히 격리된 폴더를 가져요:
사용자 자체를 참조하는 방법을 찾아야 해요:
{
subject: "???????????????????????????????/com.twitter.post/34qye3wows2c5"
}어떻게 할까요?
신원
이건 어려운 문제예요.
지금까지, 소셜 앱을 위한 파일시스템 같은 걸 만들어왔어요. 하지만 “소셜” 부분은 사용자 간 링크가 필요해요. 어떤 사용자를 참조하는 믿을 수 있는 방법이 필요해요. 어려운 점은 다른 사용자들의 “모든 것 폴더”가 다른 컴퓨터에, 다른 회사, 커뮤니티, 조직에 호스팅되거나, 셀프 호스팅될 수 있는 분산 파일시스템을 만들고 있다는 거예요.
더구나, 누구도 현재 호스팅에 갇히길 원치 않아요. 사용자가 “모든 것 폴더”를 누가 호스팅하는지 언제든 바꿀 수 있어야 하고, 파일에 대한 기존 링크를 깨지 않아야 해요. 주요 긴장은 사용자의 호스팅 변경 능력을 보존하면서 링크가 깨지지 않게 하고 싶다는 거예요. 추가로, 시스템이 분산되어 있지만, 각 데이터가 변조되지 않았다는 확신을 갖고 싶어요.
지금은 레코드, 컬렉션, 폴더에 대해 다 잊어도 돼요. 단일 문제에 집중할게요: 링크. 더 구체적으로, 호스팅을 바꿀 수 있는 영구 링크 설계가 필요해요. 이게 작동하지 않으면, 다른 모든 것이 무너져요.
시도 1: 호스트를 신원으로
dril[7]의 콘텐츠가 some-cool-free-hosting.com에 호스팅된다고 가정해요. 그의 콘텐츠에 링크하는 가장 직관적인 방법은 그의 호스팅에 일반 HTTP 링크를 사용하는 거예요:
{
subject: "https://some-cool-free-hosting.com/com.twitter.post/34qye3wows2c5"
}이건 작동하지만, dril이 호스팅을 바꾸고 싶으면, 모든 링크가 깨져요. 그래서 이건 해결책이 아니에요—바로 그게 우리가 해결하려는 문제니까요. 링크가 “dril의 것이 지금 있는 곳”이 아니라 “dril의 것이 앞으로 있을 곳”을 가리키길 원해요.
어떤 종류의 간접 참조가 필요해요.
시도 2: 핸들을 신원으로
dril에게 @dril 같은 영구적인 식별자를 주고 그걸 링크에 쓸 수 있어요:
{
subject: "@dril/com.twitter.post/34qye3wows2c5"
}그러고 나서 각 사용자에 대해 이런 JSON 문서를 저장하는 레지스트리를 운영할 수 있어요:
{
// ...
"service": [{
// ...
"serviceEndpoint": "https://some-cool-free-hosting.com"
}]
}아이디어는 이 문서가 @dril의 실제 호스팅을 찾는 방법을 알려준다는 거예요.
dril이 이 문서를 업데이트할 방법도 제공해야 해요.
이것의 어떤 버전은 작동할 수 있지만, 인터넷에 이미 있는 전역 네임스페이스를 놔두고 우리만의 것을 발명하는 건 아쉬워 보여요. 이 아이디어에 변형을 시도해볼게요.
시도 3: 도메인을 신원으로
누구나 참여할 수 있는 전역 네임스페이스가 이미 있어요: DNS. dril이 wint.co를 소유한다면, 그 도메인을 영구적인 신원으로 쓰게 해줄 수 있어요:
{
subject: "@wint.co/com.twitter.post/34qye3wows2c5"
}이건 실제 콘텐츠가 wint.co에 호스팅된다는 의미가 아니에요; wint.co가 콘텐츠가 현재 어디 있는지 말하는 JSON 문서를 호스팅한다는 거예요. 예를 들어, 관례적으로 그 문서를 /document.json으로 서빙하는 거예요. 다시, 문서가 호스팅을 가리켜요. 당연히, dril은 자기 문서를 업데이트할 수 있어요.
이건 어느 정도 우아하지만 실제로 트레이드오프가 좋지 않아요. 도메인 잃는 건 꽤 흔하고, 대부분의 사람들은 그게 계정을 벽돌로 만들길 원치 않아요.
시도 4: 해시를 신원으로
마지막 두 시도는 결함을 공유해요: 같은 핸들에 영원히 묶여요.
@dril 같은 핸들이든 @wint.co 같은 도메인 핸들이든, 사람들이 링크를 깨지 않고 언제든 핸들을 바꿀 수 있길 원해요.
익숙하게 들리나요? 호스팅에도 같은 걸 원해요. 그러니 “도메인 핸들” 아이디어를 유지하면서 현재 핸들을 현재 호스팅과 함께 JSON에 저장해요:
{
// ...
"alsoKnownAs": ["@wint.co"],
// ...
"service": [{
// ...
"serviceEndpoint": "https://some-cool-free-hosting.com"
}]
}이 JSON이 신원에 대한 명함 같은 게 되어가고 있어요. “@wint.co라고 불러요, 제 것은 https://some-cool-free-hosting.com에 있어요.”
이제 이 문서를 호스팅할 곳과 편집할 방법이 필요해요.
접근법 #2의 “중앙화된 레지스트리”를 다시 살펴볼게요. 그것의 한 가지 문제는 핸들을 영구 식별자로 쓰는 거였어요. 또한, 중앙화가 나쁜데, 왜 나쁠까요? 여러 이유로 나쁘지만, 보통 권력 남용 위험이나 단일 실패점이에요. 그 위험들을 제거하지 못하더라도 줄일 수 있을 거예요. 예를 들어, 레지스트리의 출력을 자체 검증 가능하게 만들면 좋겠어요.
수학이 이걸 도울 수 있는지 봐요.
계정을 만들 때, 개인 키와 공개 키를 생성해요. 그러고 나서 초기 핸들, 호스팅, 공개 키가 있는 JSON을 만들어요. 이 “계정 생성” 작업에 개인 키로 서명해요. 그러고 나서 서명된 작업을 해시해요. 그러면 6wpkkitfdkgthatfvspcfmjo 같은 이상한 문자열이 나와요.
레지스트리가 그 해시 아래에 당신의 작업을 저장해요. 그 해시가 계정의 영구 식별자가 돼요. 당신을 참조하기 위해 링크에 그걸 쓸 거예요:
{
subject: "6wpkkitfdkgthatfvspcfmjo/com.twitter.post/34qye3wows2c5"
}이런 링크를 해석하려면, 6wpkkitfdkgthatfvspcfmjo에 속한 문서를 레지스트리에 요청해요. 현재 호스팅, 핸들, 공개 키를 반환해요. 그러고 나서 호스팅에서 com.twitter.post/34qye3wows2c5를 가져와요.
좋아요, 하지만 이 레지스트리에서 핸들이나 호스팅을 어떻게 업데이트해요?
업데이트하려면, 이전 작업의 해시로 설정된 prev 필드가 있는 새 작업을 만들어요. 서명하고 레지스트리에 보내요. 레지스트리가 서명을 검증하고, 작업을 로그에 추가하고, 문서를 업데이트해요.
서빙된 문서를 위조하지 않음을 증명하기 위해, 레지스트리는 식별자에 대한 과거 작업들을 나열하는 엔드포인트를 노출해요. 작업을 검증하려면, 서명이 유효하고 prev 필드가 그 전 작업의 해시와 일치하는지 확인해요. 이렇게 하면 첫 번째 작업까지 업데이트의 전체 체인을 검증할 수 있어요. 첫 번째 작업의 해시가 식별자니까, 그것도 검증할 수 있어요. 그 시점에서, 모든 변경이 사용자의 키로 서명됐다는 걸 알아요.
(신뢰 모델에 대해 더 알고 싶으면 PLC 명세를 보세요.)
이 접근법으로, 레지스트리는 여전히 중앙화되어 있지만 감지될 위험 없이 누구의 문서도 위조할 수 없어요. 레지스트리를 신뢰할 필요를 더 줄이기 위해, 전체 작업 로그를 감사 가능하게 만들어요. 레지스트리는 비공개 데이터를 갖지 않고 완전히 오픈 소스예요. 이상적으로, 결국 독립적인 법적 실체로 분리되어 장기적으로 ICANN[8]처럼 될 수 있어요.
대부분의 사람들이 키 관리를 하고 싶지 않을 테니, 호스팅이 사용자를 대신해 키를 보관한다고 가정해요. 레지스트리는 호스팅 자체가 불량해질 경우를 대비해 우선하는 교체 키를 등록하는 방법을 포함해요. (좋은 UX로 이걸 설정하는 방법이 있으면 좋겠어요; 대부분의 사람들은 이걸 켜지 않아요.)
마지막으로, 핸들이 이제 레지스트리에 있는 문서로 결정되니까, 도메인이 어떤 식별자의 핸들이 되는 것에 동의한다는 신호를 보내는 방법을 추가해야 해요. 이건 DNS, HTTPS, 또는 둘의 혼합으로 할 수 있어요.
휴! 완벽하지는 않지만 놀랍도록 멀리 왔어요.
시도 5: DID를 신원으로
최종 사용자 관점에서, 시도 #4(해시를 신원으로)가 가장 친화적이에요. 신원에 도메인을 쓰지 않고(핸들로만), 도메인 잃는 건 괜찮아요.
하지만, 아무리 투명하더라도 제3자 레지스트리에 의존하는 게 받아들일 수 없다고 생각하는 사람들도 있어요. 그래서 접근법 #3(도메인을 신원으로)도 지원하면 좋겠어요.
본질적으로 관련 없는 여러 식별 방법의 네임스페이스를 만드는 방법인 DID (탈중앙화 식별자)라는 유연한 식별자 표준을 쓸 거예요:
did:plc:6wpkkitfdkgthatfvspcfmjo— 해시 기반 (PLC 레지스트리)did:web:wint.co— 도메인 기반
이러면 Like 레코드가 이렇게 돼요:
{
subject: "at://did:plc:6wpkkitfdkgthatfvspcfmjo/com.twitter.post/34qye3wows2c5"
}이게 최종 형태예요. 여기서 at://를 쓰는 건 이게 HTTP 링크가 아니라는 걸 상기시키고, 결과를 실제로 얻으려면 해석 절차(문서 가져오기, 호스팅 가져오기, 그다음 레코드 가져오기)를 따라야 한다는 거예요.
이제 방금 논의한 모든 걸 잊고 네 가지만 기억하면 돼요:
- DID는 사용자의 영구 식별자예요
- 핸들은 DID의 사람 친화적인 이름이에요 (바꿀 수 있음)
- 호스팅은 데이터가 실제로 있는 곳이에요 (옮길 수 있음)
- DID 문서는 핸들, 호스팅, 공개 키를 매핑해요
멘탈 모델은 이런 함수가 있다는 거예요:
async function resolveDID(did) {
// ...
return { hosting, handle, publicKey };
}DID를 주면, 그들의 것을 찾을 곳, 양방향 검증된 현재 핸들, 공개 키를 반환해요. ‘use cache’를 붙이고 싶을 거예요.
(아니, 진심이에요.)
이제 소셜 파일시스템을 완성해요.
at:// URI
DID가 있으면, 마침내 모든 특정 레코드를 식별하는 경로를 구성할 수 있어요:
at:// URI는 호스팅과 핸들 변경에도 살아남는 레코드 링크예요.
여기 멘탈 모델은 항상 레코드로 해석할 수 있다는 거예요:
async function fetchRecord(atURI) {
const { did, collection, rkey } = parseATUri(atURI);
const { hosting } = await resolveDID(did);
const params = `repo=${did}&collection=${collection}&rkey=${rkey}`;
return fetch(`${hosting}/xrpc/com.atproto.repo.getRecord?${params}`);
}호스팅이 다운되면, 일시적으로 해석이 안 되지만, 사용자가 어딘가에 올리고 DID를 거기로 가리키면, 다시 해석되기 시작해요. 사용자는 레코드를 삭제할 수도 있고, 그러면 “모든 것 폴더”에서 제거돼요.
at:// URI를 생각하는 또 다른 방법은 파일시스템의 모든 레코드에 대한 유일한 식별자로 쓰여서 데이터베이스나 캐시의 키로 쓸 수 있다는 거예요.
JSON의 웹
링크가 있으면, 마침내 레코드 간 관계를 표현할 수 있어요.
dril의 포스트를 다시 봐요:
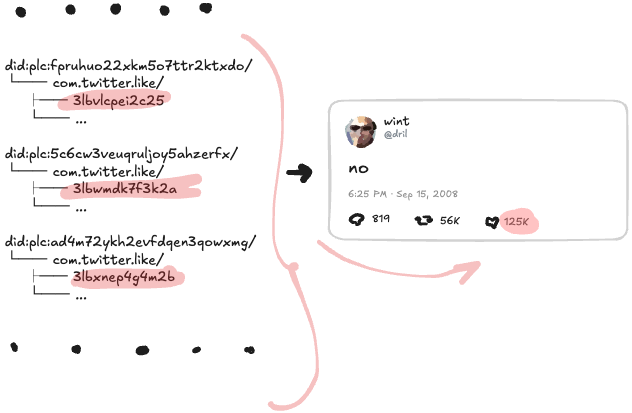
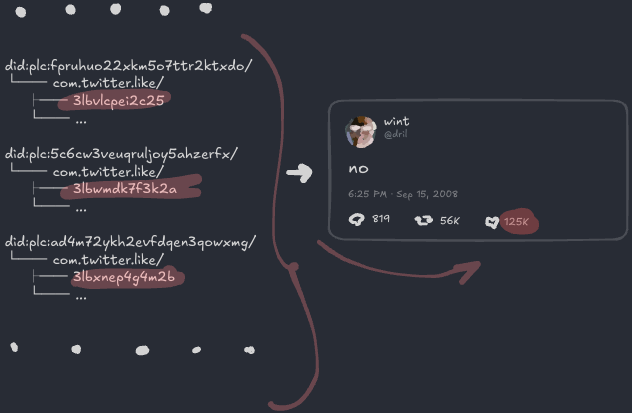
12만 5천 개의 좋아요는 어디서 오나요?
이건 그냥 다른 사람들의 “모든 것 폴더”에 있는 12만 5천 개의 com.twitter.like 레코드가 각각 dril의 com.twitter.post 레코드에 링크하는 거예요:
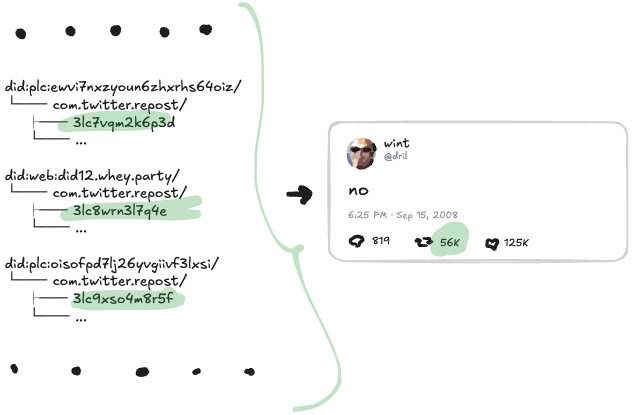
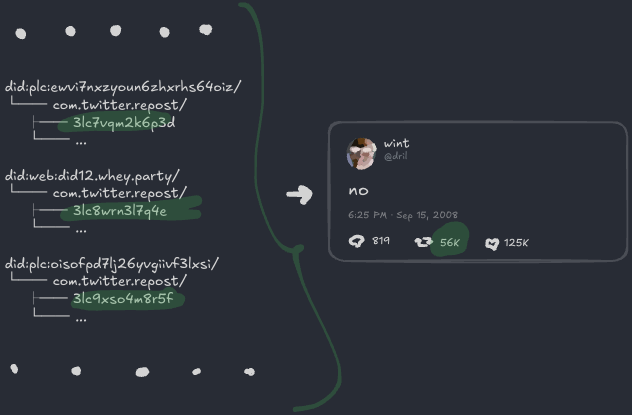
56K 리포스트는 어디서 오나요? 마찬가지로, 소셜 파일시스템 전체에 이 포스트에 링크하는 56K com.twitter.repost 레코드가 있다는 뜻이에요:
답글은요?
답글은 그냥 부모 포스트가 있는 포스트예요. TypeScript로 이렇게 쓸 거예요:
type Post = {
text: string,
createdAt: string
parent?: Post
};렉시콘으로 이렇게 쓸 거예요:
// ...
"text": { "type": "string", "maxGraphemes": 300 },
"createdAt": { "type": "string", "format": "datetime" },
"parent": { "type": "ref", "ref": "com.twitter.post" }
// ...이건 parent 필드가 다른 com.twitter.post 레코드에 대한 참조라는 거예요.
dril의 포스트에 대한 모든 답글은 dril의 포스트를 parent로 가져요:
{
"text": "yes",
"createdAt": "2008-09-15T18:02:00.000Z",
"parent": "at://did:plc:6wpkkitfdkgthatfvspcfmjo/com.twitter.post/34qye3wows2c5"
}그래서, 답글 수를 얻으려면, 그런 모든 포스트를 세기만 하면 돼요:

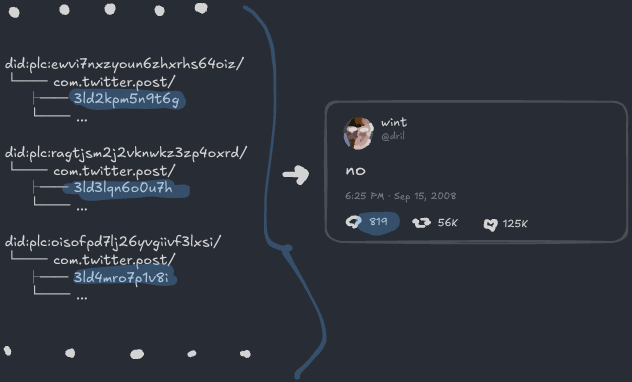
이제 원래 UI의 모든 조각이 어떻게 파일에서 파생되는지 설명했어요.
마지막 마무리는 핸들이에요. 안타깝게도, 도메인을 핸들로 쓰기로 해서 @dril은 더 이상 핸들로 쓸 수 없어요. 위안이라면, dril은 원한다면 모든 미래 소셜 앱에서 @wint.co를 쓸 수 있어요.
저장소
”모든 것 폴더”에 제대로 된 이름을 줄 때예요. 저장소라고 부를게요. 저장소는 DID로 식별돼요. 컬렉션을 포함하고, 컬렉션은 레코드를 포함해요:
did:plc:fpruhuo22xkm5o7ttr2ktxdo/
├── com.twitter.like/
│ └── ...
├── com.twitter.post/
│ └── ...
├── fm.last.scrobble/
│ ├── 3ld5nsp8q2w9j
│ ├── 3ld5ntq9r3x0k
│ └── ...
└── com.ycombinator.news.vote/
├── 3ld6our0s4y1l
└── ...각 저장소는 소셜 파일시스템에서 사용자의 작은 조각이에요. 저장소는 어디든—무료 제공자, 유료 서비스, 또는 자체 서버에—호스팅할 수 있어요. 링크를 깨지 않고 저장소를 원하는 만큼 옮길 수 있어요.
실제로 소셜 파일시스템을 만들 때 한 가지 어려움은 앱이 추가 오버헤드 없이 파생 데이터(예: 좋아요 수)를 계산할 수 있어야 한다는 거예요. 물론, 특정 포스트를 참조하는 모든 저장소의 모든 com.twitter.like 레코드를 찾는 건 그 포스트의 UI를 서빙할 때 완전히 비실용적이에요.
그래서 저장소를 파일시스템처럼 취급하는 것 외에—목록을 보고 읽을 수 있음—스트림처럼 취급해서 WebSocket으로 구독할 수 있어요. 이렇게 하면 누구나 앱이 필요로 하는 파생 데이터만 있는 로컬 앱 특화 캐시를 만들 수 있어요. 스트림으로 각 커밋을 트리 델타와 함께 이벤트로 받아요.
예를 들어, Hacker News 백엔드가 모든 알려진 저장소에서 com.ycombinator.news.* 레코드의 생성/업데이트/삭제를 듣고 빠른 쿼리를 위해 로컬에 저장할 수 있어요. vote_count 같은 파생 데이터도 추적할 수 있어요.
모든 앱에서 모든 알려진 저장소를 구독하는 건 불편해요. 릴레이라는 전용 서비스를 쓰는 게 더 좋아요. 릴레이는 모든 이벤트를 재전송해요. 하지만 이건 신뢰 문제를 일으켜요: 다른 사람의 릴레이가 거짓말하는지 어떻게 알아요?
이걸 해결하기 위해, 저장소 데이터를 자체 인증 가능하게 만들어요. 저장소를 해시 트리로 구조화할 수 있어요. 각 쓰기는 새 루트 해시를 포함하는 서명된 커밋이에요. 이렇게 하면 들어오는 레코드를 원래 작성자의 공개 키에 대해 검증할 수 있어요. 증명을 재전송하는 릴레이를 구독하는 한, 레코드가 진짜인지 알기 위해 모든 증명을 확인할 수 있어요.
레코드의 진위를 검증하는 데 콘텐츠를 저장할 필요가 없어서, 릴레이는 단순한 재전송기로 작동할 수 있고 운영 비용이 저렴해요.
대기권 위로
대기권(at://-mosphere, 이해하셨죠?)을 탐험하고 싶다면, pdsls가 최고의 시작점이에요. DID나 핸들을 주면, 컬렉션과 레코드 목록을 보여줘요. 정말 옛날식 파일 관리자 같아요, 소셜 것들을 위한 것 빼고요.
시작할 랜덤한 장소를 원한다면 여기 at://danabra.mov가 있어요. 거기서 무슨 일이 일어나는지 80%를 이해하게 될 거예요—컬렉션, 신원, 레코드 등. 자유롭게 들어가 보세요. 레코드는 다른 링크로 연결돼요, 등등. 거기엔 집계가 거의 없어서 (예: Bluesky처럼 스레드 뷰가 없음) 약간 “근거 없는” 느낌이 들지만 백링크 같은 흥미로운 탐색 기능이 있어요.
제가 대기권을 잠깐 돌아다니는 걸 보세요:
(그래, 저 렉시콘 뭐야?! 녹화하다가 우연히 마주칠 줄 몰랐어요.)
아무튼, 제가 좋아하는 데모는 이거예요.
pdsls로 레코드를 만들어서 Bluesky 포스트를 만드는 걸 보세요:
🎬 데모 영상 보기: pdsls로 Bluesky 포스트 만들기
이건 어떤 AT 앱에서도 작동해요, Bluesky만의 특별한 게 아니에요. 사실, Bluesky Post 렉시콘의 이벤트를 듣는 모든 AT 앱이 이 포스트가 만들어진 걸 알아요. 앱은 모두의 레코드의 다운스트림에 있어요.
Next.js를 배우려고, 얼마 전에 Sidetrail이라는 작은 앱을 만들었어요 (오픈 소스예요). 단계별 워크스루를 만들고 그걸 “걸을” 수 있게 해줘요.
여기서 pdsls에서 app.sidetrail.walk 레코드를 삭제하고, 해당 걷기가 Sidetrail “걷기” 탭에서 사라지는 걸 볼 수 있어요:
왜 작동하는지 정확히 알아요, 놀랄 리가 없는데, 놀라워요! 제 저장소가 정말 진실의 원천이에요. 제 데이터가 대기권에 살고, 앱이 그에 “반응”해요.
이상해요!!!
여기 제 인제스터[10] 코드가 있어요:
export async function handleEvent(db: IngesterDb, evt: JetstreamEvent): Promise<void> {
if (evt.kind === "account") {
await handleAccountEvent(db, evt.account);
return;
}
if (evt.kind === "identity") return;
if (evt.kind !== "commit") return;
const { commit } = evt;
const { collection, rkey } = commit;
if (!COLLECTIONS.includes(collection)) return;
const [accountStatus] = await db
.select({ active: accounts.active })
.from(accounts)
.where(eq(accounts.did, evt.did))
.limit(1);
if (accountStatus && !accountStatus.active) {
return;
}
const uri = `at://${evt.did}/${collection}/${rkey}`;
if (commit.operation === "delete") {
switch (collection) {
case "app.sidetrail.trail":
await deleteTrail(db, uri);
break;
case "app.sidetrail.walk":
await deleteWalk(db, uri);
break;
case "app.sidetrail.completion":
await deleteCompletion(db, uri);
break;
}
return;
}
const record = commit.record as Record<string, unknown>;
await ensureAccount(db, evt.did);
switch (collection) {
case "app.sidetrail.trail":
await upsertTrail(
db,
uri,
commit.cid,
evt.did,
rkey,
record,
(record.createdAt as string) || new Date().toISOString(),
);
break;
case "app.sidetrail.walk": {
const trailRef = record.trail as { uri: string } | undefined;
const trailUri = trailRef?.uri || "";
await upsertWalk(
db,
uri,
commit.cid,
evt.did,
rkey,
trailUri,
record,
(record.createdAt as string) || new Date().toISOString(),
);
break;
}
case "app.sidetrail.completion": {
const trailRef = record.trail as { uri: string } | undefined;
const trailUri = trailRef?.uri || "";
await upsertCompletion(
db,
uri,
commit.cid,
evt.did,
rkey,
trailUri,
record,
(record.createdAt as string) || new Date().toISOString(),
);
break;
}
}
}이건 모든 사람의 저장소 변경을 제 데이터베이스에 동기화해서 쿼리하기 쉬운 스냅샷을 갖게 해요. 더 깔끔하게 쓸 수 있을 것 같지만, 개념적으로, 데이터베이스를 다시 렌더링하는 것 같아요. 인터넷 “위”에서 setState를 호출한 것 같고, 이제 새 props가 파일에서 앱으로 흘러내려가고, 제 DB가 이제 반응적이에요.
프로덕션에서 그 테이블들을 삭제해도, Tap[11]을 써서 데이터베이스를 처음부터 백필할 수 있어요. 전역 데이터의 슬라이스를 캐싱하고 있을 뿐이에요. AT 앱을 만드는 모든 사람도 슬라이스들을 캐싱해야 해요. 아마 다른 슬라이스들이지만, 겹쳐요. 그래서 자원을 모으는 게 더 유용해져요. 아니면 적어도 공유 도구가 더 많아요.
정말 좋아하는 또 다른 예가 있어요.
여기 @chadmiller.com이 만든 teal.fm Relay 데모가 있어요. 모든 사람의 최근 재생 트랙 목록과 전체 통계 일부를 보여줘요:
이제, 화면 상단에 “678,850 scrobbles”라고 돼 있는 걸 볼 수 있어요. 사람들이 한동안 teal.fm API에 재생을 스크로블해왔다고 생각할 수 있어요.
음, 그렇지 않아요.
teal.fm API는 실제로 존재하지 않아요. 그런 게 없어요. 더구나, teal.fm 제품도 실제로 존재하지 않아요. 개발 중인 것 같긴 한데 (취미 프로젝트예요!), 이 글을 쓰는 시점에 https://teal.fm/은 그냥 랜딩 페이지예요.
하지만 그건 중요하지 않아요!
스크로블을 시작하는 데 필요한 건 fm.teal.alpha.feed.play 렉시콘의 레코드를 저장소에 넣는 것뿐이에요.
렉시콘은 레코드로 게시되지 않았지만 (아직?) GitHub에서 쉽게 찾을 수 있어요. 그래서 누구나 이것들을 쓰는 스크로블러를 만들 수 있어요. 저도 그런 스크로블러 중 하나를 쓰고 있어요.
여기 제 스크로블이 나타나는 거예요:
(좀 느리지만 지연은 Spotify/스크로블러 통합 쪽인 것 같아요.)
명확히 하자면, 이 데모를 만든 사람도 teal.fm에서 일하지 않아요. “공식” 데모나 뭐 그런 게 아니고, “teal.fm 데이터베이스”나 “teal.fm API” 같은 것도 쓰지 않아요. 그냥 fm.teal.alpha.feed.plays를 인덱싱할 뿐이에요.
지금 사람들이 뭔가 듣고 있는지 궁금해요.
이 데모 얘기가 나와서, 새 lex-gql 패키지를 쓰는데 이것도 @chadtmiller.com의 실험이에요. 렉시콘들을 주면, 소셜 파일시스템의 관련 부분의 백필된 스냅샷에서 GraphQL을 실행할 수 있게 해줘요.
세상의 JSON이 있으면, 제품들에 걸쳐 조인을 실행하지 않을 이유가 없잖아요?
fragment TrackItem_play on FmTealAlphaFeedPlay {
trackName
playedTime
artists {
artistName
}
releaseName
releaseMbId
actorHandle
musicServiceBaseDomain
appBskyActorProfileByDid {
displayName
avatar {
url(preset: "avatar")
}
}
}흥미로웠다고 생각한 마지막 예가 있어요.
몇 달 동안, 솔직히 저한테 잘 안 맞는 Bluesky의 기본 Discover 피드에 대해 불평해왔어요. 그러다가 @spacecowboy17.bsky.social의 For You 알고리즘에 대해 좋은 말을 하는 사람들을 들었어요.
써보니까 정말 좋아요!
🎬 데모 영상 보기: For You 커스텀 피드 알고리즘
결국 완전히 바꿨어요. 2017년 트위터 알고리즘이 생각나요—변동이 좀 세지만 놓치고 싶지 않은 것들을 찾아줘요. “덜 보여줘”에도 훨씬 더 반응적이에요. 핵심 원칙은 꽤 단순해 보여요.
이런 커스텀 피드는 어떻게 작동할까요? 음, Bluesky 피드는 그냥 at:// URI 목록을 반환하는 엔드포인트예요. 그게 계약이에요. 어떻게 작동하는지 알잖아요.
[
{ post: 'at://did:example:1234/app.bsky.feed.post/1' },
{ post: 'at://did:example:1234/app.bsky.feed.post/2' },
{ post: 'at://did:example:1234/app.bsky.feed.post/3' }
]웃긴 건, @spacecowboy17.bsky.social은 한동안 집 컴퓨터에서 For You를 운영했어요. 그는 피드 변경의 A/B 테스트 같은 흥미로운 것들을 많이 올려요. 또, 여기 제 계정의 For You 디버거가 있어요. “관점 전환”이 멋져요.
몇 주 전에 Bluesky가 알고리즘을 너무 못해서 사용자들이 좋은 경험을 얻으려면 서드파티 피드를 설치해야 한다고 놀리는 트윗이 있었어요.
@dame.is가 이건 중요한 걸 보여준다고 말한 거에 동의해요: Bluesky는 그게 가능한 곳이에요. 왜요? 대기권에서, 서드 파티가 퍼스트 파티예요. 우리 모두 같은 데이터의 투영을 만들고 있어요. 누군가 더 잘할 수 있다는 게 기능이에요.
모든 것을 하는 앱은 모든 것을 하려고 해요.
모든 것의 생태계는 모든 것이 이루어지게 해요.
• • •
역자 주
- Excalidraw: 오픈소스 화이트보드/다이어그램 도구예요. 손으로 그린 듯한 스타일의 다이어그램을 만들 수 있고, SVG를 포함한 다양한 포맷으로 내보낼 수 있어요. 브라우저에서 바로 사용할 수 있고, 협업 기능도 지원해요. ↩
- Hacker News: Y Combinator가 운영하는 기술 뉴스 커뮤니티 사이트예요. 스타트업, 프로그래밍, 기술 관련 링크를 공유하고 토론하는 곳이에요. “업보트(upvote)“는 좋은 글에 투표하는 기능으로, Reddit의 추천 시스템과 비슷해요. ↩
- 스크로블(scrobble): Last.fm에서 유래한 용어로, 음악 청취 기록을 자동으로 추적하고 저장하는 것을 말해요. 예를 들어, Spotify에서 노래를 들으면 그 기록이 Last.fm에 자동으로 기록되는 거예요. teal.fm은 AT Protocol 기반의 오픈 스크로블링 서비스예요. ↩
- 구체화 뷰(Materialized View): 데이터베이스에서 자주 사용되는 개념으로, 미리 계산된 쿼리 결과를 저장해두는 것이에요. 원본 데이터가 변경되면 뷰도 업데이트되어야 해요. 여기서는 각 앱이 자신만의 방식으로 전체 소셜 데이터의 일부를 캐싱하고 있다는 의미예요. ↩
- TID (Timestamp ID): AT Protocol에서 레코드를 식별하는 데 사용하는 타임스탬프 기반 ID예요. Base32 인코딩(a-z와 2-7 사용)을 사용해서 URL에서 안전하게 쓸 수 있고, 알파벳순으로 정렬하면 자동으로 시간순이 되도록 설계됐어요. ↩
- RDF와 JSON Schema: 데이터 구조를 정의하는 기존 표준들이에요. RDF(Resource Description Framework)는 시맨틱 웹을 위한 W3C 표준으로, 데이터 간의 관계를 표현해요. JSON Schema는 JSON 데이터의 구조와 유효성을 정의하는 명세예요. AT Protocol은 이들 대신 자체 스키마 언어인 렉시콘을 사용해요. ↩
- dril (@dril, wint): 트위터/X에서 2008년부터 활동한 전설적인 익명 계정이에요. 초현실적이고 부조리한 유머로 유명하며, 인터넷 밈 문화에 큰 영향을 미쳤어요. 본명은 공개하지 않았지만 “wint”라는 별명으로도 알려져 있고, wint.co 도메인을 소유하고 있어요. ↩
- ICANN (Internet Corporation for Assigned Names and Numbers): 인터넷 도메인 이름과 IP 주소를 관리하는 국제 비영리 기구예요. .com, .org 같은 최상위 도메인을 관장하고, 도메인 등록 정책을 결정해요. 여기서는 DID 레지스트리가 이처럼 독립적이고 중립적인 기구로 발전할 수 있다는 비전을 말하고 있어요. ↩
- pdsls: “PDS ls”의 줄임말로, AT Protocol의 Personal Data Server(PDS)를 탐색하는 웹 기반 도구예요. 마치 Unix의
ls명령어처럼 사용자의 저장소 내용을 목록으로 보여줘요. DID나 핸들을 입력하면 해당 사용자의 컬렉션과 레코드를 직접 탐색할 수 있어요. ↩ - 인제스터(Ingester)와 Jetstream: AT Protocol 앱에서 데이터를 수집하는 컴포넌트예요. Jetstream은 AT Protocol의 이벤트 스트림 서비스로, 모든 저장소의 변경 사항을 실시간으로 구독할 수 있게 해줘요. 앱은 이 스트림을 구독해서 관심 있는 레코드만 필터링하고 자체 데이터베이스에 저장해요. ↩
- Tap: AT Protocol 생태계의 백필(backfill) 도구예요. 백필은 과거 데이터를 소급해서 가져오는 작업을 말해요. 앱을 처음 시작하거나 데이터베이스를 복구할 때, Tap을 사용해서 기존에 생성된 모든 레코드를 가져와서 데이터베이스를 채울 수 있어요. ↩
저자 소개: Dan Abramov는 React 핵심 팀 전 멤버이자 Redux의 공동 창시자입니다. 현재 Bluesky에서 일하고 있습니다.
참고: 이 글은 Dan Abramov가 자신의 블로그 overreacted.io에 게시한 아티클을 번역한 것입니다.
원문: A Social Filesystem - Dan Abramov, overreacted.io (2026년 1월 18일)
생성: Claude (Anthropic)